Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-databas i Förhandsversion av Microsoft Fabric
SQL-databas i Förhandsversion av Microsoft Fabric
Att utforma effektiva index är nyckeln till att uppnå bra databas- och programprestanda. Brist på index, överindexering eller dåligt utformade index är de främsta källorna till problem med databasprestanda.
Den här guiden beskriver indexarkitekturen och grunderna och innehåller metodtips som hjälper dig att utforma effektiva index för att uppfylla behoven i dina program.
Mer information om tillgängliga indextyper finns i Index.
Den här guiden beskriver följande typer av index:
| Primärt lagringsformat | Indextyp |
|---|---|
| Diskbaserad radlagring | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Grupperat kolumnarkiv | |
| Icke-grupperat kolumnarkiv | |
| Memory-optimized | |
| Hash | |
| Minnesoptimerad icke-grupperad |
Information om XML-index finns i XML-index (SQL Server) och SXI (Selective XML index).
Information om rumsliga index finns i Översikt över rumsliga index.
För information om fulltextindex, se Skapa Full-Text-indexeringar.
Grunderna i index
Tänk på en vanlig bok: i slutet av boken finns det ett index som hjälper till att snabbt hitta information i boken. Indexet är en sorterad lista med nyckelord och bredvid varje nyckelord finns en uppsättning sidnummer som pekar på de sidor där varje nyckelord finns.
Ett radlagringsindex liknar varandra: det är en ordnad lista med värden och för varje värde finns det pekare till de datasidor där dessa värden finns. Själva indexet lagras också på sidor som kallas indexsidor. Om indexet i en vanlig bok sträcker sig över flera sidor och du måste hitta pekare till alla sidor som innehåller ordet SQL till exempel, måste du bläddra från början av indexet tills du hittar indexsidan som innehåller nyckelordet SQL. Därifrån följer du pekarna till alla boksidor. Detta kan optimeras ytterligare om du i början av indexet skapar en enda sida som innehåller en alfabetisk lista över var varje bokstav finns. Till exempel: "A till D - sida 121", "E till G - sida 122" och så vidare. Den här extra sidan skulle eliminera steget för att bläddra igenom indexet för att hitta startplatsen. En sådan sida finns inte i vanliga böcker, men den finns i ett radlagringsindex. Den här enkla sidan kallas för indexets rotsida. Rotsidan är startsidan för trädstrukturen som används av ett index. Efter trädanalogin kallas slutsidorna som innehåller pekare till faktiska data för "lövsidor" i trädet.
Ett index är en struktur på disken eller i minnet som är associerad med en tabell eller vy som påskyndar hämtningen av rader från tabellen eller vyn. Ett radlagringsindex innehåller nycklar som skapats från värdena i en eller flera kolumner i tabellen eller vyn. För radlagringsindex lagras dessa nycklar i en trädstruktur (B+-träd) som gör att databasmotorn kan hitta de rader som är associerade med nyckelvärdena snabbt och effektivt.
Ett radlagringsindex lagrar data logiskt ordnade som en tabell med rader och kolumner och lagras fysiskt i ett radvist dataformat som kallas rowstore1. Det finns ett alternativt sätt att lagra datakolumnmässigt, som kallas columnstore.
Utformningen av rätt index för en databas och dess arbetsbelastning är en komplex balansakt mellan frågehastighet, indexuppdateringskostnad och lagringskostnad. Smala diskbaserade radlagringsindex, eller index med få kolumner i indexnyckeln, kräver mindre lagringsutrymme och mindre uppdateringskostnader. Breda index kan å andra sidan förbättra fler frågor. Du kan behöva experimentera med flera olika designer innan du hittar den mest effektiva uppsättningen index. När programmet utvecklas kan index behöva ändras för att upprätthålla optimala prestanda. Index kan läggas till, ändras och tas bort utan att det påverkar databasschemat eller programdesignen. Därför bör du inte tveka att experimentera med olika index.
Frågeoptimeraren i databasmotorn väljer vanligtvis de mest effektiva indexen för att köra en fråga. Om du vill se vilka index som frågeoptimeraren använder för en specifik fråga går du till SQL Server Management Studio på menyn Fråga och väljer Visa uppskattad körningsplan eller Inkludera faktisk körningsplan.
Likställ inte alltid indexanvändning med bra prestanda och bra prestanda med effektiv indexanvändning. Om användning av ett index alltid hjälpte till att skapa bästa prestanda skulle jobbet för frågeoptimeraren vara enkelt. I verkligheten kan ett felaktigt indexval orsaka mindre än optimala prestanda. Därför är uppgiften för frågeoptimeraren att välja ett index, eller en kombination av index, bara när det förbättrar prestanda och att undvika indexerad hämtning när det hindrar prestanda.
Ett vanligt designfel är att skapa många index spekulativt för att "ge optimeraren val". Den resulterande överindexeringen gör dataändringarna långsammare och kan orsaka samtidighetsproblem.
1 Radlagring har varit det traditionella sättet att lagra relationstabelldata. Radlagring refererar till en tabell där det underliggande datalagringsformatet är en heap, ett B+-träd (grupperat index) eller en minnesoptimerad tabell. Diskbaserad radlagring exkluderar minnesoptimerade tabeller.
Designuppgifter för index
Följande uppgifter utgör vår rekommenderade strategi för att utforma index:
Förstå egenskaperna för databasen och programmet.
I till exempel en OLTP-databas (onlinetransaktionsbearbetning) med frekventa dataändringar som måste upprätthålla ett högt dataflöde, skulle några smala radlagringsindex som är mål för de mest kritiska frågorna vara en bra inledande indexdesign. För extremt högt dataflöde bör du överväga minnesoptimerade tabeller och index, vilket ger en lås- och låsfri design. Mer information finns i Minnesoptimerade riktlinjer för icke-indexdesign och riktlinjer för hash-indexdesign i den här guiden.
Omvänt är det särskilt lämpligt att använda grupperade kolumnlagringsindex för en analys- eller datalagerdatabas (OLAP) som måste bearbeta mycket stora datamängder snabbt. Mer information finns i Columnstore-index: översikt eller Columnstore-indexarkitektur i den här guiden.
Förstå egenskaperna för de vanligaste frågorna.
Om du till exempel vet att en fråga som används ofta ansluter till två eller flera tabeller kan du fastställa uppsättningen index för dessa tabeller.
Förstå datafördelningen i kolumnerna som används i frågepredikaten.
Ett index kan till exempel vara användbart för kolumner med många distinkta datavärden, men mindre för kolumner med många duplicerade värden. För kolumner med många NULL:er eller de som har väldefinierade delmängder av data kan du använda ett filtrerat index. Mer information finns i Riktlinjer för filtrerad indexdesign i den här guiden.
Avgör vilka indexalternativ som kan förbättra prestandan.
Om du till exempel skapar ett grupperat index i en befintlig stor tabell kan du dra nytta av indexalternativet
ONLINE. AlternativetONLINEtillåter att samtidig aktivitet på underliggande data fortsätter medan indexet skapas eller återskapas. Om du använder komprimering av rad- eller siddata kan du förbättra prestandan genom att minska indexets I/O- och minnesavtryck. Mer information finns i SKAPA INDEX.Granska befintliga index i tabellen för att förhindra att dubbletter eller mycket liknande index skapas.
Det är ofta bättre att ändra ett befintligt index än att skapa ett nytt men mestadels duplicerat index. Överväg till exempel att lägga till en eller två extra inkluderade kolumner i ett befintligt index i stället för att skapa ett nytt index med dessa kolumner. Detta är särskilt relevant när du justerar icke-klustrade index med saknade indexförslag, eller om du använder Databasmotorns justeringsrådgivare, där du kan erbjudas liknande varianter av index på samma tabell och kolumner.
Allmänna riktlinjer för indexdesign
Genom att förstå egenskaperna för din databas, dina frågor och tabellkolumner kan du utforma optimala index från början och ändra designen allt eftersom dina program utvecklas.
Databasöverväganden
När du utformar ett index bör du överväga följande riktlinjer för databasen:
Ett stort antal index i en tabell påverkar prestanda för
INSERT,UPDATE,DELETEochMERGE-instruktioner eftersom data i index kan behöva ändras när data i tabellen ändras. Om en kolumn till exempel används i flera index och du kör enUPDATEinstruktion som ändrar kolumnens data, måste även varje index som innehåller kolumnen uppdateras.Undvik att överindexera kraftigt uppdaterade tabeller och hålla indexen smala, dvs. med så få kolumner som möjligt.
Du kan ha fler index för tabeller som har få dataändringar men stora datavolymer. För sådana tabeller kan en mängd olika index förbättra frågeprestandan samtidigt som indexuppdateringens överhead fortfarande är acceptabel. Skapa dock inte index spekulativt. Övervaka indexanvändningen och ta bort oanvända index över tid.
Indexering av små tabeller kanske inte är optimalt eftersom det kan ta längre tid för databasmotorn att bläddra i indexsökningen efter data än att utföra en bastabellsökning. Därför kanske index på små tabeller aldrig används, men måste fortfarande uppdateras när data i tabellen uppdateras.
Index för vyer kan ge betydande prestandavinster när vyn innehåller sammansättningar och/eller kopplingar. Mer information finns i Skapa indexerade vyer.
Databaser på primära repliker i Azure SQL Database genererar automatiskt prestandarekommendationer för databasrådgivare för index. Du kan också aktivera automatisk indexjustering.
Query Store hjälper dig att identifiera frågor med suboptimal prestanda och ger en historik över frågekörningsplaner som låter dig se de index som valts av optimeraren. Du kan använda dessa data för att göra dina indexjusteringsändringar mest effektfulla genom att fokusera på de vanligaste och resurskrävande frågorna.
Frågeöverväganden
När du utformar ett index bör du tänka på följande frågeriktlinjer:
Skapa icke-klustrade index på de kolumner som ofta används i predikater och sammanfogande uttryck i frågor. Det här är dina SARGable-kolumner . Du bör dock undvika att lägga till onödiga kolumner i index. Om du lägger till för många indexkolumner kan det påverka diskutrymmet och indexuppdateringens prestanda negativt.
Termen SARGable i relationsdatabaser refererar till ett Search ARGumentable-predikat som kan använda ett index för att påskynda exekveringen av SQL-frågan. Mer information finns i arkitektur och designguide för SQL Server- och Azure SQL-index.
Tip
Se alltid till att de index som du skapar faktiskt används av frågearbetsbelastningen. Släpp oanvända index.
Indexanvändningsstatistik finns i sys.dm_db_index_usage_stats och sys.dm_db_index_operational_stats.
Att täcka index kan förbättra frågeprestanda eftersom alla data som behövs för att uppfylla kraven för frågan finns i själva indexet. Det vill säga, endast indexsidorna, och inte datasidorna i tabellen eller det klustrade indexet, krävs för att hämta de begärda data, vilket minskar den totala disk-I/O. Till exempel kan en fråga av kolumnerna
AochBpå en tabell som har ett sammansatt index skapat på kolumnernaA,B, ochChämta de angivna data enbart från indexet.Note
Ett täckande index är ett icke-grupperat index som uppfyller all dataåtkomst via en fråga direkt utan att komma åt bastabellen.
Sådana index har alla nödvändiga SARGable-kolumner i indexnyckeln och icke-SARGable-kolumner som inkluderade kolumner. Det innebär att alla kolumner som krävs av frågan, antingen i satserna
WHERE,JOINochGROUP BYeller i satsernaSELECTellerUPDATE, finns i indexet.Det finns potentiellt mycket mindre I/O för att köra frågan, om indexet är tillräckligt smalt jämfört med raderna och kolumnerna i själva tabellen, vilket innebär att det är en liten delmängd av alla kolumner.
Överväg att täcka index när du hämtar en liten del av en stor tabell och där den lilla delen definieras av ett fast predikat.
Undvik att skapa ett täckande index med för många kolumner eftersom det minskar dess fördelar samtidigt som databaslagring, I/O och minnesfotavtryck blåses upp.
Skriv frågor som infogar eller ändrar så många rader som möjligt i en enda instruktion, i stället för att använda flera frågor för att uppdatera samma rader. Detta minskar indexuppdateringens kostnader.
Kolumnöverväganden
När du utformar ett index bör du tänka på följande kolumnriktlinjer:
Håll längden på indexnyckeln kort, särskilt för klustrade index.
Kolumner som är av datatyperna ntext, text, bild, varchar(max), nvarchar(max), varbinary(max), json och vektor kan inte anges som indexnyckelkolumner. Kolumner med dessa datatyper kan dock läggas till i ett icke-grupperat index som icke-nyckelindexkolumner (ingår). Mer information finns i avsnittet Använd inkluderade kolumner i icke-klustrade index i den här guiden.
Granska kolumn unikhet. Ett unikt index i stället för ett icke-substantivt index på samma nyckelkolumner ger ytterligare information för frågeoptimeraren som gör indexet mer användbart. Mer information finns i Riktlinjer för unik indexdesign i den här guiden.
Granska datadistributionen i kolumnen. Att skapa ett index på en kolumn med många rader men få distinkta värden kanske inte förbättrar frågeprestanda även om indexet används av frågeoptimeraren. Som en analogi påskyndar inte en fysisk telefonkatalog som sorteras alfabetiskt på familjenamn att hitta en person om alla människor i staden heter Smith eller Jones. Mer information om datadistribution finns i Statistik.
Överväg att använda filtrerade index på kolumner som har väldefinierade underuppsättningar, till exempel kolumner med många NULL:er, kolumner med värdekategorier och kolumner med distinkta värden. Ett väldesignat filtrerat index kan förbättra frågeprestanda, minska kostnaderna för indexuppdatering och minska lagringskostnaderna genom att lagra en liten delmängd av alla rader i tabellen om den delmängden är relevant för många frågor.
Överväg ordningen på indexnyckelkolumnerna om nyckeln innehåller flera kolumner. Kolumnen som används i frågans predikat i en likhets- (
=), olikhets- (>,>=,<,<=), ellerBETWEENuttryck, eller som är en del av en join, bör placeras först. Ytterligare kolumner bör sorteras baserat på deras distinktitetsnivå, det vill sägs från den mest distinkta till den minst distinkta.Om indexet till exempel definieras som
LastName,FirstNameär indexet användbart när frågepredikatet iWHERE-satsen ärWHERE LastName = 'Smith'ellerWHERE LastName = Smith AND FirstName LIKE 'J%'. Frågeoptimeraren skulle dock inte använda indexet för en fråga som endast sökte påWHERE FirstName = 'Jane', eller så skulle indexet inte förbättra prestandan för en sådan fråga.Överväg att indexera beräknade kolumner om de ingår i frågepredikat. Mer information finns i Index över beräknade kolumner.
Indexegenskaper
När du har fastställt att ett index är lämpligt för en fråga kan du välja den typ av index som passar bäst för din situation. Indexegenskaper är:
- Klustrad eller icke-grupperad
- Unikt eller icke-unikt
- Enskild kolumn eller multikollumn
- Stigande eller fallande ordning för nyckelkolumnerna i indexet
- Alla rader eller filtrerade för icke-grupperade index
- Columnstore eller rowstore
- Hash eller icke-klustererad för minnesoptimerade tabeller
Indexplacering på filgrupper eller partitionsscheman
När du utvecklar indexdesignstrategin bör du överväga placeringen av indexen på de filgrupper som är associerade med databasen.
Som standard lagras index i samma filgrupp som bastabellen (klustrat index eller heap) som indexet skapas på. Andra konfigurationer är möjliga, inklusive:
Skapa icke-grupperade index på en annan filgrupp än bastabellens filgrupp.
Partitionera klustrade och icke-klustrade index över flera filgrupper.
För icke-partitionerade tabeller är den enklaste metoden vanligtvis den bästa: skapa alla tabeller i samma filgrupp och lägg till så många datafiler i filgruppen som behövs för att använda all tillgänglig fysisk lagring.
Mer avancerade metoder för indexplacering kan beaktas när nivåindelad lagring är tillgänglig. Du kan till exempel skapa en filgrupp för tabeller som används ofta med filer på snabbare diskar och en filgrupp för arkivtabeller på långsammare diskar.
Du kan flytta en tabell med ett klustrat index från en filgrupp till en annan genom att släppa det klustrade indexet och ange ett nytt filgrupps- eller partitionsschema i instruktionens MOVE TODROP INDEX sats eller genom att använda -instruktionen CREATE INDEXDROP_EXISTING med -satsen.
Partitionerade index
Du kan också överväga att partitionera diskbaserade heaps, klustrade och icke-grupperade index i flera filgrupper. Partitionerade index partitioneras vågrätt (efter rad), baserat på en partitionsfunktion. Partitionsfunktionen definierar hur varje rad mappas till en partition baserat på värdena för en viss kolumn som du anger, kallad partitioneringskolumnen. Ett partitionsschema anger mappningen av en uppsättning partitioner till en filgrupp.
Partitionering av ett index kan ge följande fördelar:
Gör stora databaser mer hanterbara. OLAP-system kan till exempel implementera partitionsmedveten ETL som avsevärt förenklar tillägg och borttagning av data i bulk.
Få vissa typer av frågor, till exempel långvariga analysfrågor, att köras snabbare. När frågor använder ett partitionerat index kan databasmotorn bearbeta flera partitioner samtidigt och hoppa över (eliminera) partitioner som inte behövs av frågan.
Varning
Partitionering förbättrar sällan frågeprestanda i OLTP-system, men det kan medföra betydande omkostnader om en transaktionsfråga måste komma åt många partitioner.
Mer information finns i Partitionerade tabeller och index.
Designriktlinjer för indexsorteringsordning
När du definierar index bör du överväga om varje indexnyckelkolumn ska lagras i stigande eller fallande ordning. Stigande är standardinställningen. Syntaxen för CREATE INDEX, CREATE TABLE och ALTER TABLE-uttrycken stöder nyckelorden ASC (stigande) och DESC (fallande) för enskilda kolumner i index och begränsningar.
Att ange i vilken ordning nyckelvärden lagras i ett index är användbart när frågor som refererar till tabellen har ORDER BY satser som anger olika riktningar för nyckelkolumnen eller kolumnerna i indexet. I dessa fall kan indexet ta bort behovet av en sorteringsoperator i frågeplanen.
Till exempel måste köparna på inköpsavdelningen för Adventure Works Cycles utvärdera kvaliteten på de produkter som de köper från leverantörer. Köparna är mest intresserade av att hitta produkter som skickas av leverantörer med en hög avvisningsgrad.
Som du ser i följande fråga mot AdventureWorks-exempeldatabasen kräver hämtning av data för att uppfylla det här villkoret RejectedQtyPurchasing.PurchaseOrderDetail att kolumnen i tabellen sorteras i fallande ordning (stor till liten) och ProductID att kolumnen sorteras i stigande ordning (liten till stor).
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
Följande körningsplan för den här frågan visar att frågeoptimeraren använde en sorteringsoperator för att returnera resultatuppsättningen i den ordning som anges av ORDER BY satsen.

Om ett diskbaserat radlagringsindex skapas med nyckelkolumner som matchar dem i ORDER BY -satsen i frågan elimineras sorteringsoperatorn i frågeplanen, vilket gör frågeplanen effektivare.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
När frågan har körts igen visar följande körningsplan att sorteringsoperatorn inte längre finns och att det nyligen skapade icke-klustrade indexet används.
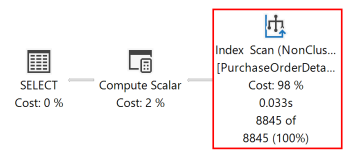
Databasmotorn kan skanna ett index i båda riktningarna. Ett index som definieras som RejectedQty DESC, ProductID ASC kan fortfarande användas för en fråga där kolumnernas sorteringsriktningar i ORDER BY -satsen är omvända. En fråga med ORDER BY -satsen ORDER BY RejectedQty ASC, ProductID DESC kan till exempel använda samma index.
Sorteringsordning kan endast anges för nyckelkolumnerna i indexet. Den sys.index_columns katalogvyn rapporterar om en indexkolumn lagras i stigande eller fallande ordning.
Designriktlinjer för grupperat index
Det klustrade indexet lagrar alla rader och alla kolumner i en tabell. Rader sorteras i ordning efter indexnyckelvärden. Det kan bara finnas ett grupperat index per tabell.
"Termen bas-tabell kan referera till antingen ett klustrat index eller till en heap." En heap är en osorterad datastruktur på disken som innehåller alla rader och alla kolumner i en tabell.
Med några få undantag bör varje tabell ha ett grupperat index. De önskvärda egenskaperna för det klustrade indexet är:
| Fastighet | Description |
|---|---|
| Begränsa | Den klustrade indexnyckeln är en del av alla icke-klustrade index i samma bastabell. En smal nyckel, eller en nyckel där den totala längden på nyckelkolumner är liten, minskar lagringsutrymmet, I/O och minneskostnaderna för alla index i en tabell. Om du vill beräkna nyckellängden lägger du till lagringsstorlekarna för de datatyper som används av nyckelkolumner. Mer information finns i Kategorier av datatyp. |
| Unik | Om det klustrade indexet inte är unikt läggs en intern unik kolumn på 4 byte automatiskt till i indexnyckeln för att säkerställa unikhet. Om du lägger till en befintlig unik kolumn i den klustrade indexnyckeln undviker du lagring, I/O och minnesomkostnader för kolumnen uniqueifier i alla index i en tabell. Dessutom kan frågeoptimeraren generera effektivare frågeplaner när ett index är unikt. |
| Ständigt ökande | I ett ständigt ökande index läggs data alltid till på den sista sidan i indexet. Detta undviker siddelningar i mitten av indexet, vilket minskar sidtätheten och minskar prestanda. |
| Oföränderliga | Den klustrade indexnyckeln är en del av ett icke-klustrat index. När en nyckelkolumn i ett klustrat index ändras måste en ändring också göras i alla icke-klustrade index, vilket lägger till CPU-, loggnings-, I/O- och minnesomkostnader. Omkostnaderna undviks om nyckelkolumnerna i det klustrade indexet inte kan ändras. |
| Har endast icke-nullbara kolumner | Om en rad har null-kolumner måste den innehålla en intern struktur som kallas null-block, som lägger till 3–4 byte lagringsutrymme per rad i ett index. Genom att göra alla kolumner i ett klustrat index icke-null undviker du denna overhead. |
| Har endast kolumner med fast bredd | Kolumner med datatyper med variabel bredd, till exempel varchar eller nvarchar , använder ytterligare 2 byte per värde jämfört med datatyper med fast bredd. Om du använder datatyper med fast bredd, till exempel int , undviks detta i alla index i tabellen. |
Om du uppfyller så många av dessa egenskaper som möjligt när du utformar ett klustrat index blir det inte bara klustrade index utan även alla icke-grupperade index i samma tabell effektivare. Prestandan förbättras genom att du undviker kostnader för lagring, I/O och minne.
Till exempel har en klustrad indexnyckel med en enskild int eller bigint inte nullbar kolumn alla dessa egenskaper om den fylls i av en IDENTITY sats eller en standardbegränsning med hjälp av en sekvens och inte uppdateras efter att en rad har infogats.
Omvänt är en klustrad indexnyckel med en enda unikidentifierarkolumn bredare eftersom den använder 16 byte lagringsutrymme i stället för 4 byte för int och 8 byte för bigint, och uppfyller inte den ständigt ökande egenskapen om inte värdena genereras sekventiellt.
Tip
När du skapar en PRIMARY KEY begränsning skapas ett unikt index som stöder begränsningen automatiskt. Som standard är det här indexet klustrade. Men om det här indexet inte uppfyller de önskade egenskaperna för det klustrade indexet kan du skapa villkoret som icke-grupperat och skapa ett annat grupperat index i stället.
Om du inte skapar ett grupperat index lagras tabellen som en heap, vilket vanligtvis inte rekommenderas.
Klustrad indexarkitektur
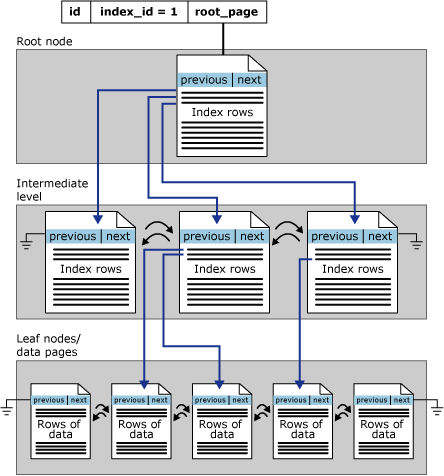
Radlagringsindex ordnas som B+-träd. Varje sida i ett B+-indexträd kallas för en indexnod. Den översta noden i B+-trädet kallas rotnoden. De nedre noderna i indexet kallas lövnoderna. Alla indexnivåer mellan rot- och lövnoderna kallas tillsammans mellanliggande nivåer. I ett grupperat index innehåller lövnoderna datasidorna i den underliggande tabellen. Noderna på rot- och mellannivå innehåller indexsidor som innehåller indexrader. Varje indexrad innehåller ett nyckelvärde och en pekare till antingen en sida på mellannivå i B+-trädet eller en datarad i indexets lövnivå. Sidorna på varje nivå i indexet är länkade i en dubbelt länkad lista.
Klustrade index har en rad i sys.partitioner för varje partition som används av indexet, med index_id = 1. Som standardinställning har ett klustrat index en enda partition. När ett klustrat index har flera partitioner har varje partition en separat B+-trädstruktur som innehåller data för den specifika partitionen. Om ett grupperat index till exempel har fyra partitioner finns det fyra B+-trädstrukturer, en i varje partition.
Beroende på datatyperna i det klustrade indexet har varje klustrad indexstruktur en eller flera allokeringsenheter där du kan lagra och hantera data för en specifik partition. Varje klustrat index har minst en IN_ROW_DATA allokeringsenhet per partition. Det klustrade indexet har också en LOB_DATA allokeringsenhet per partition om det innehåller stora objektkolumner (LOB), till exempel nvarchar(max). Den har också en ROW_OVERFLOW_DATA allokeringsenhet per partition om den innehåller kolumner med variabel längd som överskrider radstorleksgränsen på 8 060 byte.
Sidorna i B+-trädstrukturen sorteras efter värdet på den klustrade indexnyckeln. Alla infogningar görs på sidan där nyckelvärdet i den infogade raden passar i ordningsföljden mellan befintliga sidor. På en sida lagras inte rader nödvändigtvis i någon fysisk ordning. Sidan har dock en logisk ordning på rader med hjälp av en intern struktur som kallas för en fackmatris. Elementen i fackmatrisen behålls i ordning efter indexnyckel.
Den här bilden visar strukturen för ett grupperat index i en enda partition.
Designriktlinjer för icke-illustrerade index
Den största skillnaden mellan ett grupperat och ett icke-grupperat index är att ett icke-grupperat index innehåller en delmängd av kolumnerna i tabellen, vanligtvis sorterat på ett annat sätt än det klustrade indexet. Du kan också filtrera ett icke-grupperat index, vilket innebär att det innehåller en delmängd av alla rader i tabellen.
Ett diskbaserat rowstore-icke-grupperat index innehåller radlokaliserare som pekar på lagringsplatsen för raden i bastabellen. Du kan skapa flera icke-klustrade index i en tabell eller indexerad vy. I allmänhet bör icke-klustrade index utformas för att förbättra prestanda för ofta använda frågor som annars skulle behöva söka igenom bastabellen.
På samma sätt som du använder ett index i en bok söker frågeoptimeraren efter ett datavärde genom att söka i det icke-klustrade indexet för att hitta platsen för datavärdet i tabellen och hämtar sedan data direkt därifrån. Detta gör ickeklustrade index till det optimala valet för exakta matchningsfrågor eftersom indexet innehåller poster som beskriver den exakta platsen i tabellen för de datavärden som söks efter i frågorna.
Om du till exempel vill köra frågor mot HumanResources.Employee-tabellen för alla anställda som rapporterar till en viss chef, kan frågeoptimeraren använda det icke-klustrade indexet IX_Employee_ManagerID. Detta har ManagerID som sin första nyckelkolumn.
ManagerID Eftersom värdena sorteras i det ickeklustrade indexet kan frågeoptimeraren snabbt hitta alla indexposter som matchar det angivna ManagerID värdet. Varje indexinmatning pekar på den exakta sidan och raden i bastabellen där motsvarande data från alla andra kolumner kan hämtas. När frågeoptimeraren hittar alla poster i indexet kan den gå direkt till den exakta sidan och raden för att hämta data i stället för att skanna hela bastabellen.
Icke-grupperad indexarkitektur
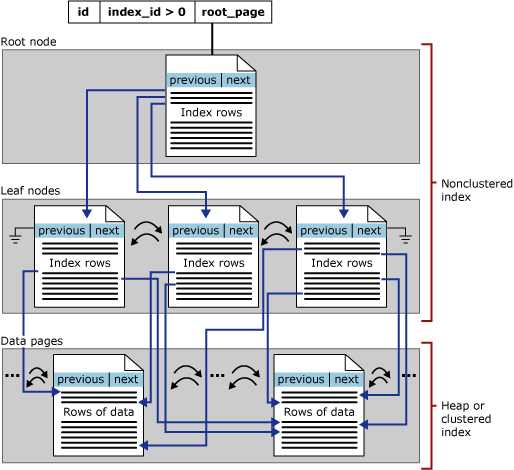
Diskbaserade radlagringsindex som inte är grupperade har samma B+-trädstruktur som klustrade index, förutom följande skillnader:
Ett icke-grupperat index innehåller inte nödvändigtvis alla kolumner och rader i tabellen.
Lövnivån för ett icke-grupperat index består av indexsidor i stället för datasidor. Indexsidorna på lövnivån för ett icke-grupperat index innehåller nyckelkolumner. Alternativt kan de också innehålla en delmängd av andra kolumner i tabellen som inkluderade kolumner, för att undvika att hämta dem från bastabellen.
Radlokaliserare i icke-grupperade indexrader är antingen en pekare till en rad eller är en klustrad indexnyckel för en rad, som beskrivs på följande sätt:
Om tabellen har ett grupperat index, eller om indexet finns i en indexerad vy, är radlokaliseraren den klustrade indexnyckeln för raden.
Om tabellen har en heap-struktur, vilket innebär att den inte har ett klustrat index, är radlokaliseraren en pekare till raden. Pekaren skapas från filidentifieraren (ID), sidnummer och numret på raden på sidan. Hela pekaren kallas för ett rad-ID (RID).
Radlokaliserare säkerställer också unikhet för icke-klustrade indexrader. I följande tabell beskrivs hur databasmotorn lägger till radlokaliserare i icke-grupperade index:
| Bas tabelltyp | Icke-grupperad indextyp | Radlokaliserare |
|---|---|---|
| Heap | ||
| Nonunique | RID har lagts till i nyckelkolumner | |
| Unique | RID har lagts till i inkluderade kolumner | |
| Unikt grupperat index | ||
| Nonunique | Grupperade indexnycklar har lagts till i nyckelkolumner | |
| Unique | Klustrade indexnycklar har lagts till i inkluderade kolumner | |
| Icke-unikt grupperat index | ||
| Nonunique | Klustrade indexnycklar och unikgörare (när de finns) läggs till nyckelkolumner | |
| Unique | Klustrade indexnycklar och unika identifierare (om tillämpligt) har lagts till i inkluderade kolumner. |
Databasmotorn lagrar aldrig en viss kolumn mer än en gång i ett icke-grupperat index. Den indexnyckelordning som anges av användaren när de skapar ett icke-grupperat index respekteras alltid: alla radlokaliserarkolumner som behöver läggas till i nyckeln för ett icke-grupperat index läggs till i slutet av nyckeln, efter de kolumner som anges i indexdefinitionen. Grupperade indexnyckelradspositionerare i ett icke-grupperat index kan användas vid frågebearbetning, oavsett om de uttryckligen anges i indexdefinitionen eller läggs till implicit.
Följande exempel visar hur radlokaliserare implementeras i icke-grupperade index:
| Klustrerad index | Icke-illustrerad indexdefinition | Icke-grupperad indexdefinition med radlokaliserare | Explanation |
|---|---|---|---|
Unikt grupperat index med nyckelkolumner (A, B, C) |
Nonunique nonclustered index med nyckelkolumner (B, A) och inkluderade kolumner (E, G) |
Nyckelkolumner (B, A, C) och inkluderade kolumner (E, G) |
Det icke-klustrade indexet är icke-unikt, så radlokaliseraren måste finnas i indexnycklarna. Kolumner B och A från radlokaliseraren finns redan, så endast kolumn C läggs till. Kolumnen C läggs till i slutet av nyckelkolumnlistan. |
Unikt klustrat index med nyckelkolumn (A) |
Icke-unikt icke-klustrat index med nyckelkolumner (B, C) och inkluderad kolumn (A) |
Nyckelkolumner (B, C, A) |
Det icke-klustrade indexet är icke-unikt, så radlokaliseraren läggs till i nyckeln. Kolumnen A har inte redan angetts som en nyckelkolumn, så den läggs till i slutet av nyckelkolumnlistan. Kolumnen A finns nu i nyckeln, så du behöver inte lagra den som en inkluderad kolumn. |
Unikt klustrat index med nyckelkolumn (A, B) |
Unikt icke-grupperat index med nyckelkolumn (C) |
Nyckelkolumn (C) och inkluderade kolumner (A, B) |
Det icke-klustrade indexet är unikt, så radlokaliseraren läggs till i de inkluderade kolumnerna. |
Icke-grupperade index har en rad i sys.partitioner för varje partition som används av indexet, med index_id > 1. Som standard har ett icke-grupperat index en enda partition. När ett icke-grupperat index har flera partitioner har varje partition en B+-trädstruktur som innehåller indexraderna för den specifika partitionen. Om ett icke-grupperat index till exempel har fyra partitioner finns det fyra B+-trädstrukturer, en i varje partition.
Beroende på datatyperna i det icke-grupperade indexet har varje icke-grupperad indexstruktur en eller flera allokeringsenheter där du kan lagra och hantera data för en specifik partition. Varje icke-grupperat index har minst en IN_ROW_DATA allokeringsenhet per partition som lagrar indexets B+-trädsidor. Det icke-grupperade indexet har också en LOB_DATA allokeringsenhet per partition om det innehåller stora objektkolumner (LOB), till exempel nvarchar(max). Dessutom har den en ROW_OVERFLOW_DATA allokeringsenhet per partition om den innehåller kolumner med variabel längd som överskrider radstorleksgränsen på 8 060 byte.
Följande bild visar strukturen för ett icke-grupperat index i en enda partition.
Använda inkluderade kolumner i icke-grupperade index
Förutom nyckelkolumner kan ett icke-grupperat index också ha icke-nyckelkolumner lagrade på lövnivån. Dessa icke-nyckelkolumner kallas inkluderade kolumner och anges i INCLUDE-klausulen i CREATE INDEX-satsen.
Ett index med inkluderade icke-nyckelkolumner kan avsevärt förbättra frågeprestandan när det täcker frågan, det vill s.v.s. när alla kolumner som används i frågan finns i indexet antingen som nyckelkolumner eller icke-nyckelkolumner. Prestandavinster uppnås eftersom databasmotorn kan hitta alla kolumnvärden i indexet. Bastabellen används inte, vilket resulterar i färre disk-I/O-åtgärder.
Om en kolumn måste hämtas av en fråga, men inte används i frågepredikat, sammansättningar och sorteringar, lägger du till den som en inkluderad kolumn och inte som en nyckelkolumn. Detta har följande fördelar:
Inkluderade kolumner kan använda datatyper som inte tillåts som indexnyckelkolumner.
Inkluderade kolumner beaktas inte av databasmotorn vid beräkning av antalet indexnyckelkolumner eller indexnyckelstorlek. Med inkluderade kolumner begränsas du inte av den maximala nyckelstorleken på 900 byte. Du kan skapa bredare index som täcker fler frågor.
När du flyttar en kolumn från indexnyckeln till inkluderade kolumner tar indexbyggandet mindre tid eftersom sorteringsoperationen för indexet blir snabbare.
Om tabellen har ett grupperat index läggs kolumnen eller kolumnerna som definierats i den klustrade indexnyckeln automatiskt till i varje icke-unikt icke-grupperat index i tabellen. Du behöver inte specificera dem varken i den icke-klustrade indexnyckeln eller som inkluderade kolumner.
Riktlinjer för index med inkluderade kolumner
Tänk på följande riktlinjer när du utformar icke-klustrade index med inkluderade kolumner:
Inkluderade kolumner kan bara definieras i icke-grupperade index i tabeller eller indexerade vyer.
Alla datatyper tillåts förutom text, ntextoch bild.
Beräknade kolumner som är deterministiska och antingen exakta eller oprecisa kan inkluderas kolumner. Mer information finns i Index över beräknade kolumner.
Precis som med nyckelkolumner kan beräknade kolumner som härletts från bild-, ntext- och textdatatyper inkluderas kolumner så länge datatypen för den beräknade kolumnen tillåts i en inkluderad kolumn.
Kolumnnamn kan inte anges i både
INCLUDElistan och i nyckelkolumnlistan.Kolumnnamn kan inte upprepas i
INCLUDElistan.Minst en nyckelkolumn måste definieras i ett index. Det maximala antalet inkluderade kolumner är 1 023. Det här är det maximala antalet tabellkolumner minus 1.
Oavsett förekomsten av inkluderade kolumner måste indexnyckelkolumner följa de befintliga indexstorleksbegränsningarna på högst 16 nyckelkolumner och en total indexnyckelstorlek på 900 byte.
Utforma rekommendationer för index med inkluderade kolumner
Överväg att designa om icke-grupperade index med en stor indexnyckelstorlek så att endast kolumner som används i frågepredikat, sammansättningar och sorteringar är nyckelkolumner. Gör alla andra kolumner som ingår i frågan till icke-nyckelkolumner. På så sätt har du alla kolumner som behövs för att täcka frågan, men själva indexnyckeln är liten och effektiv.
Anta till exempel att du vill utforma ett index för att täcka följande fråga.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
För att täcka frågan måste varje kolumn definieras i indexet. Även om du kan definiera alla kolumner som nyckelkolumner blir nyckelstorleken 334 byte. Eftersom den enda kolumn som används som sökvillkor är PostalCode kolumnen, med en längd på 30 byte, skulle en bättre indexdesign definieras PostalCode som nyckelkolumn och inkludera alla andra kolumner som icke-nyckelkolumner.
Följande instruktion skapar ett index med inkluderade kolumner för att täcka frågan.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Om du vill verifiera att indexet täcker frågan skapar du indexet och visar sedan den uppskattade körningsplanen. Om körningsplanen visar en Index Seek-operator för IX_Address_PostalCode-indexet, omfattas frågan av indexet.
Prestandaöverväganden för index med inkluderade kolumner
Undvik att skapa index med ett mycket stort antal inkluderade kolumner. Även om indexet kan täckas för fler frågor, minskas prestandafördelarna eftersom:
Färre indexrader får plats på en sida. Detta ökar diskens I/O och minskar cacheeffektiviteten.
Mer diskutrymme krävs för att lagra indexet. Att lägga till varchar(max), nvarchar(max), varbinary(max)eller xml-datatyper i inkluderade kolumner kan i synnerhet avsevärt öka diskutrymmeskraven. Det beror på att kolumnvärdena kopieras till indexbladets nivå. Därför finns de i både indexet och bastabellen.
Dataändringsprestandan minskar eftersom många kolumner måste ändras både i bas-tabellen och i det icke-klustrade indexet.
Du måste avgöra om vinsterna i frågeprestanda uppväger minskningen av prestanda för dataändringar och ökningen av diskutrymmeskraven.
Designriktlinjer för unikt index
Ett unikt index garanterar att indexnyckeln inte innehåller några duplicerade värden. Det går bara att skapa ett unikt index när unikhet är en egenskap hos själva data. Om du till exempel vill se till att värdena i kolumnen i NationalIDNumber tabellen är unika skapar du en HumanResources.Employee begränsning för EmployeeID kolumnen när den primära nyckeln är UNIQUE.NationalIDNumber Villkoret avvisar alla försök att införa rader med dubbla nationella ID-nummer.
Med unika index med flera kolumner garanterar indexet att varje kombination av värden i indexnyckeln är unik. Om till exempel ett unikt index skapas på en kombination av LastName, FirstNameoch MiddleName kolumner, kan inga två rader i tabellen ha samma värden för dessa kolumner.
Både klustrade och icke-grupperade index kan vara unika. Du kan skapa ett unikt grupperat index och flera unika icke-grupperade index i samma tabell.
Fördelarna med unika index är:
- Affärsregler som kräver att data är unika tillämpas.
- Ytterligare information som är användbar för frågeoptimeraren finns.
Att skapa en PRIMARY KEY- eller UNIQUE-begränsning skapar automatiskt ett unikt index för de angivna kolumnerna. Det finns inga betydande skillnader mellan att skapa en UNIQUE begränsning och att skapa ett unikt index oberoende av en begränsning. Datavalidering sker på samma sätt och frågeoptimeraren skiljer inte mellan ett unikt index som skapats av en begränsning eller skapats manuellt. Du bör dock skapa en UNIQUE eller PRIMARY KEY begränsning för kolumnen när tillämpningen av affärsregler är målet. Genom att göra detta är indexets mål tydligt.
Unika indexöverväganden
Det går inte att skapa ett unikt index,
UNIQUEen begränsning ellerPRIMARY KEYett villkor om det finns dubbletter av nyckelvärden i data.Om data är unikt och du vill säkerställa unikhet, ger skapandet av ett unikt index istället för ett icke-unikt index på samma kombination av kolumner ytterligare information för frågeoptimeraren, vilket kan skapa effektivare körplaner. I det här fallet rekommenderas att du skapar en
UNIQUEbegränsning eller ett unikt index.Ett unikt icke-grupperat index kan innehålla icke-nyckelkolumner. Mer information finns i Använda inkluderade kolumner i icke-grupperade index.
Till skillnad från en
PRIMARY KEYbegränsning kan enUNIQUEbegränsning eller ett unikt index skapas med en nullbar kolumn i indexnyckeln. I syfte att framtvinga unikhet anses två NULL:er vara lika. Det innebär till exempel att kolumnen i ett unikt index med en kolumn endast kan vara NULL för en rad i tabellen.
Designriktlinjer för filtrerat index
Ett filtrerat index är ett optimerat icke-grupperat index, särskilt lämpligt för frågor som kräver en liten delmängd data i tabellen. Den använder ett filterpredikat i indexdefinitionen för att indexera en del rader i tabellen. Ett väldesignat filtrerat index kan förbättra frågeprestanda, minska kostnaderna för indexuppdatering och minska kostnaderna för indexlagring jämfört med ett fulltabellindex.
Filtrerade index kan ge följande fördelar jämfört med fullständiga tabellindex:
Förbättrad frågeprestanda och plankvalitet
Ett väldesignat filtrerat index förbättrar frågeprestandan och utförandeplanens kvalitet eftersom det är mindre än ett icke-klustrat index över hela tabellen. Ett filtrerat index har filtrerad statistik som är mer exakt än fulltabellstatistik eftersom de endast täcker raderna i det filtrerade indexet.
Minskade kostnader för indexuppdatering
Ett index uppdateras endast när DML-instruktioner (Data Manipulation Language) påverkar data i indexet. Ett filtrerat index minskar kostnaderna för indexuppdatering jämfört med ett icke-grupperat index med fullständiga tabeller eftersom det är mindre och uppdateras endast när data i indexet påverkas. Det är möjligt att ha ett stort antal filtrerade index, särskilt när de innehåller data som påverkas sällan. På samma sätt, om ett filtrerat index endast innehåller de data som påverkas ofta, minskar indexets mindre storlek kostnaden för att uppdatera statistik.
Minskade kostnader för indexlagring
Om du skapar ett filtrerat index kan du minska disklagringen för icke-klustrade index när ett fullständigt tabellindex inte behövs. Du kanske kan ersätta ett icke-grupperat index med en fullständig tabell med flera filtrerade index utan att avsevärt öka lagringskraven.
Filtrerade index är användbara när kolumner innehåller väldefinierade delmängder av data. Exempel är:
Kolumner som innehåller många NULLL:er.
Heterogena kolumner som innehåller datakategorier.
Kolumner som innehåller intervall med värden, till exempel belopp, tid och datum.
Minskade uppdateringskostnader för filtrerade index är mest märkbara när antalet rader i indexet är litet jämfört med ett fulltabellindex. Om det filtrerade indexet innehåller de flesta raderna i tabellen kan det kosta mer att underhålla än ett fullständigt tabellindex. I det här fallet bör du använda ett fulltabellindex i stället för ett filtrerat index.
Filtrerade index definieras i en tabell och stöder endast enkla jämförelseoperatorer. Om du behöver ett filteruttryck som har komplex logik eller refererar till flera tabeller bör du skapa en indexerad beräknad kolumn eller en indexerad vy.
Designöverväganden för filtrerat index
För att kunna utforma effektiva filtrerade index är det viktigt att förstå vilka frågor ditt program använder och hur de relaterar till delmängder av dina data. Några exempel på data som har väldefinierade underuppsättningar är kolumner med många NULL:er, kolumner med heterogena kategorier av värden och kolumner med distinkta värden.
Följande designöverväganden ger flera scenarier för när ett filtrerat index kan ge fördelar jämfört med fulltabellindex.
Filtrerade index för delmängder av data
När en kolumn bara har några relevanta värden för frågor kan du skapa ett filtrerat index för delmängden av värden. Om kolumnen till exempel till största delen är NULL och frågan bara kräver icke-NULL-värden kan du skapa ett filtrerat index som innehåller icke-NULL-raderna.
Exempeldatabasen AdventureWorks har till exempel en Production.BillOfMaterials tabell med 2 679 rader. Kolumnen EndDate har bara 199 rader som innehåller ett värde som inte är NULL och de övriga 2 480 raderna innehåller NULL. Följande filtrerade index omfattar frågor som returnerar kolumnerna som definierats i indexet och som endast kräver rader med ett värde som inte är NULL för EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
Det filtrerade indexet FIBillOfMaterialsWithEndDate är giltigt för följande fråga.
Visa den uppskattade körningsplanen för att bestämma om frågeoptimeraren använde det filtrerade indexet.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Mer information om hur du skapar filtrerade index och hur du definierar det filtrerade indexpredikatuttrycket finns i Skapa filtrerade index.
Filtrerade index för heterogena data
När en tabell har heterogena datarader kan du skapa ett filtrerat index för en eller flera datakategorier.
Till exempel tilldelas de produkter som anges i Production.Product tabellen var och en till en ProductSubcategoryID, som i sin tur är associerade med produktkategorierna Cyklar, Komponenter, Kläder eller Tillbehör. Dessa kategorier är heterogena eftersom deras kolumnvärden i Production.Product tabellen inte är nära korrelerade. Till exempel har kolumnerna Color, ReorderPoint, ListPrice, Weight, Classoch Style unika egenskaper för varje produktkategori. Anta att det finns frekventa frågor för tillbehör, som har underkategorier mellan 27 och 36 inklusive. Du kan förbättra prestandan för frågor för tillbehör genom att skapa ett filtrerat index för underkategorierna tillbehör enligt följande exempel.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
Det filtrerade indexet FIProductAccessories täcker följande fråga eftersom frågeresultatet finns i indexet och frågeplanen inte kräver åtkomst till bastabellen. Frågepredikatuttrycket ProductSubcategoryID = 33 är till exempel en delmängd av det filtrerade indexpredikatet ProductSubcategoryID >= 27 och ProductSubcategoryID <= 36, ProductSubcategoryID kolumnerna och ListPrice i frågepredikatet är båda nyckelkolumnerna i indexet, och namnet lagras på lövnivån för indexet som en inkluderad kolumn.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Nyckel och inkluderade kolumner i filtrerade index
Det är bästa praxis att lägga till ett litet antal kolumner i en filtrerad indexdefinition, endast efter behov för frågeoptimeraren att välja det filtrerade indexet för frågekörningsplanen. Frågeoptimeraren kan välja ett filtrerat index för frågan oavsett om det täcker frågan eller inte. Det är dock mer troligt att frågeoptimeraren väljer ett filtrerat index om det täcker frågan.
I vissa fall täcker ett filtrerat index frågan utan att inkludera kolumnerna i det filtrerade indexuttrycket som nyckel eller inkluderade kolumner i den filtrerade indexdefinitionen. Följande riktlinjer förklarar när en kolumn i det filtrerade indexuttrycket ska vara en nyckel eller inkluderad kolumn i den filtrerade indexdefinitionen. Exemplen refererar till det filtrerade indexet som FIBillOfMaterialsWithEndDate skapades tidigare.
En kolumn i det filtrerade indexuttrycket behöver inte vara en nyckel eller inkluderad kolumn i den filtrerade indexdefinitionen om det filtrerade indexuttrycket motsvarar frågepredikatet och frågan inte returnerar kolumnen i det filtrerade indexuttrycket med frågeresultatet. Omfattar till exempel FIBillOfMaterialsWithEndDate följande fråga eftersom frågepredikatet motsvarar filteruttrycket och EndDate inte returneras med frågeresultatet. Indexet FIBillOfMaterialsWithEndDate behöver EndDate inte som en nyckel eller inkluderad kolumn i den filtrerade indexdefinitionen.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
En kolumn i det filtrerade indexuttrycket ska vara en nyckel eller inkluderad kolumn i den filtrerade indexdefinitionen om frågepredikatet använder kolumnen i en jämförelse som inte motsvarar det filtrerade indexuttrycket. Är till exempel FIBillOfMaterialsWithEndDate giltigt för följande fråga eftersom den väljer en delmängd rader från det filtrerade indexet. Den täcker dock inte följande fråga eftersom EndDate används i jämförelsen EndDate > '20040101', som inte motsvarar det filtrerade indexuttrycket. Frågeprocessorn kan inte köra den här frågan utan att undersöka värdena EndDateför . Därför bör EndDate vara en nyckel eller inkluderad kolumn i definitionen av det filtrerade indexet.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
En kolumn i det filtrerade indexuttrycket ska vara en nyckel eller inkluderad kolumn i den filtrerade indexdefinitionen om kolumnen finns i frågeresultatuppsättningen.
FIBillOfMaterialsWithEndDate omfattar till exempel inte följande fråga eftersom den returnerar kolumnen EndDate i frågeresultatet. Därför bör EndDate vara en nyckel eller inkluderad kolumn i definitionen av det filtrerade indexet.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Den klustrade indexnyckeln i tabellen behöver inte vara en nyckel eller inkluderad kolumn i den filtrerade indexdefinitionen. Den klustrade indexnyckeln inkluderas automatiskt i alla icke-grupperade index, inklusive filtrerade index.
Datakonverteringsoperatorer i filterpredikatet
Om jämförelseoperatorn som anges i det filtrerade indexuttrycket för det filtrerade indexet resulterar i en implicit eller explicit datakonvertering uppstår ett fel om konverteringen sker till vänster om en jämförelseoperator. En lösning är att skriva det filtrerade indexuttrycket med datakonverteringsoperatorn (CAST eller CONVERT) till höger om jämförelseoperatorn.
I följande exempel skapas en tabell med kolumner med olika datatyper.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
I följande filtrerade indexdefinition konverteras kolumnen b implicit till en heltalsdatatyp för att jämföra den med konstanten 1. Detta genererar felmeddelandet 10611 eftersom konverteringen sker till vänster om operatorn i det filtrerade predikatet.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
Lösningen är att konvertera konstanten till höger så att den är av samma typ som kolumnen b, vilket visas i följande exempel:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Om du flyttar datakonverteringen från vänster sida till höger om en jämförelseoperator kan det ändra innebörden av konverteringen. I föregående exempel, när operatorn CONVERT lades till på höger sida, ändrades jämförelsen från en int-jämförelse till en varbinär jämförelse.
Kolumnlagringsindexarkitektur
Ett kolumnlagringsindex är en teknik för att lagra, hämta och hantera data med hjälp av ett kolumnformat med namnet columnstore. Mer information finns i Columnstore-index: översikt.
För versionsinformation och för att ta reda på vad som är nytt, besök Nyheter i kolumnlagringsindex.
Genom att känna till dessa grunder blir det lättare att förstå andra artiklar om kolumnarkiv som förklarar hur man effektivt använder denna teknik.
Datalagring använder columnstore och rowstore
När vi diskuterar kolumnlagringsindex använder vi termerna rowstore och columnstore för att framhäva formatet för datalagringen. Kolumnlagringsindex använder båda typerna av lagring.

Ett kolumnlager är data som är logiskt ordnade som en tabell med rader och kolumner och som lagras fysiskt i ett kolumnmässigt dataformat.
Ett kolumnlagringsindex lagrar fysiskt de flesta data i kolumnlagringsformat. I kolumnlagringsformat komprimeras och dekomprimeras data som kolumner. Du behöver inte ta bort andra värden på varje rad som inte begärs av frågan. Det gör att det går snabbt att skanna en hel kolumn i en stor tabell.
Ett radlager är data som är logiskt ordnade som en tabell med rader och kolumner och som sedan lagras fysiskt i ett radvist dataformat. Detta har varit det traditionella sättet att lagra relationstabelldata, till exempel ett grupperat B+-trädindex eller en heap.
Ett columnstore-index lagrar även fysiskt vissa rader i ett radlagringsformat som kallas deltastore. Deltastore, även kallat delta rowgroups, är en plats för rader som är för få för att kvalificera sig för komprimering till kolumnlagringen. Varje deltaradgrupp implementeras som ett grupperat B+-trädindex, som är ett radarkiv.
Åtgärder utförs på radgrupper och kolumnsegment
Kolumnlagringsindexet grupperar rader i hanterbara enheter. Var och en av dessa enheter kallas för en radgrupp. För bästa prestanda är antalet rader i en radgrupp tillräckligt stort för att förbättra komprimeringsförhållandet och tillräckligt litet för att dra nytta av minnesåtgärder.
Till exempel utför columnstore-indexet dessa åtgärder på radgrupper:
Komprimerar radgrupper till kolumnlagringen. Komprimering utförs på varje kolumnsegment i en radgrupp.
Sammanfogar radgrupper under en
ALTER INDEX ... REORGANIZEåtgärd, inklusive borttagning av borttagna data.Återskapar alla radgrupper under en
ALTER INDEX ... REBUILDåtgärd.Rapporter om radgruppshälsa och fragmentering i dynamiska hanteringsvyer (DMV:er).
Deltastore består av en eller flera radgrupper som kallas delta rowgroups. Varje deltaradgrupp är ett grupperat B+-trädindex som lagrar små massinläsningar och infogningar tills radgruppen innehåller 1 048 576 rader. Vid detta tillfälle aktiveras en process som kallas tuple-mover, vilken automatiskt komprimerar en stängd radgrupp och omvandlar den till kolumnarkivet.
Mer information om status för radgrupper finns i sys.dm_db_column_store_row_group_physical_stats.
Tip
Om du har för många små radgrupper minskar indexkvaliteten för kolumnlagring. En omorganiseringsåtgärd sammanfogar mindre radgrupper, enligt en intern tröskelprincip som avgör hur du tar bort borttagna rader och kombinerar komprimerade radgrupper. Efter en sammanslagning förbättras indexkvaliteten.
I SQL Server 2019 (15.x) och senare versioner får tuppelflyttaren hjälp av en bakgrundssammanslagning som automatiskt komprimerar mindre öppna delta-radgrupper som har funnits under en tid enligt ett internt tröskelvärde, eller sammanfogar komprimerade radgrupper varifrån ett stort antal rader har tagits bort.
Varje kolumn har några av sina värden i varje radgrupp. Dessa värden kallas kolumnsegment. Varje radgrupp innehåller ett kolumnsegment för varje kolumn i tabellen. Varje kolumn har ett kolumnsegment i varje radgrupp.

När kolumnlagringsindexet komprimerar en radgrupp komprimeras varje kolumnsegment separat. Om du vill avkomprimera en hel kolumn behöver kolumnlagringsindexet bara avkomprimera ett kolumnsegment från varje radgrupp.
Små belastningar och infogningar går till deltastore
Ett columnstore-index förbättrar kolumnlagringskomprimering och prestanda genom att komprimera minst 102 400 rader i taget till kolumnlagringsindexet. För att komprimera rader i bulk ackumulerar kolumnlagringsindexet små datavolymer och införs i deltalagret. Deltastore-åtgärderna hanteras i bakgrunden. För att returnera frågeresultat kombinerar det klustrade kolumnlagringsindexet frågeresultat från både kolumnarkivet och deltaarkivet.
Rader går till deltalagret när de är:
Infogad med instruktionen
INSERT INTO ... VALUES.I slutet av en massladdning och de är färre än 102 400.
Updated. Varje uppdatering implementeras som en borttagning och en infogning.
Deltastore lagrar också en lista över ID:n för borttagna rader som har markerats som borttagna men ännu inte fysiskt borttagna från kolumnarkivet.
När deltaradgrupper är fulla komprimeras de till columnstore.
Grupperade kolumnlagringsindex samlar in upp till 1 048 576 rader i varje deltaradgrupp innan radgruppen komprimeras till kolumnarkivet. Detta förbättrar komprimering av kolumnlagringsindexet. När en deltaradgrupp når det maximala antalet rader övergår den från OPEN till CLOSED tillstånd. En bakgrundsprocess med namnet tuple-mover söker efter stängda radgrupper. Om processen hittar en stängd radgrupp komprimerar den radgruppen och lagrar den i kolumnarkivet.
När en deltaradgrupp har komprimerats övergår den befintliga deltaradgruppen till TOMBSTONE-tillstånd som senare kommer att tas bort av tuppelflyttaren när det inte längre finns någon referens till den, och den nya komprimerade radgruppen markeras som COMPRESSED.
Mer information om status för radgrupper finns i sys.dm_db_column_store_row_group_physical_stats.
Du kan tvinga delta rowgroups till kolumnarkivet genom att använda ALTER INDEX för att återskapa eller omorganisera indexet. Om det uppstår minnestryck under komprimering kan kolumnlagringsindexet minska antalet rader i den komprimerade radgruppen.
Varje tabellpartition har egna radgrupper och deltaradgrupper
Begreppet partitionering är detsamma i ett grupperat index, en heap och ett columnstore-index. Partitionering av en tabell delar upp tabellen i mindre grupper med rader enligt ett intervall med kolumnvärden. Det används ofta för att hantera data. Du kan till exempel skapa en partition för varje år med data och sedan använda partitionsväxling för att arkivera gamla data till billigare lagring.
Radgrupper definieras alltid i en tabellpartition. När ett columnstore-index partitioneras har varje partition sina egna komprimerade radgrupper och deltaradgrupper. En icke-partitionerad tabell innehåller en partition.
Tip
Överväg att använda tabellpartitionering om du behöver ta bort data från kolumnarkivet. Att växla ut och trunkera partitioner som inte längre behövs är en effektiv strategi för att ta bort data utan att införa fragmentering i kolumnarkivet.
Varje partition kan ha flera deltaradgrupper
Varje partition kan ha fler än en deltaradgrupper. När kolumnlagringsindexet behöver lägga till data i en deltaradgrupp och deltaradgruppen är låst av en annan transaktion, försöker kolumnlagringsindexet hämta ett lås på en annan deltaradgrupp. Om det inte finns några delta rowgroups tillgängliga skapar kolumnlagringsindexet en ny deltaradgrupp. En tabell med 10 partitioner kan till exempel enkelt ha 20 eller fler deltaradgrupper.
Kombinera columnstore- och rowstore-index i samma tabell
Ett icke-grupperat index innehåller en kopia av en del eller alla rader och kolumner i den underliggande tabellen. Indexet definieras som en eller flera kolumner i tabellen och har ett valfritt villkor som filtrerar raderna.
Du kan skapa ett updatable nonclustered columnstore index på en radlagringstabell. Kolumnlagringsindexet lagrar en kopia av data så att du behöver extra lagringsutrymme. Data i kolumnlagringsindexet komprimeras dock till en mycket mindre storlek än vad radlagringstabellen kräver. Genom att göra detta kan du köra analyser på kolumnlagringsindexet och OLTP-arbetsbelastningarna på radlagringsindexet samtidigt. Kolumnlagringen uppdateras när data ändras i radlagringstabellen, så båda indexen fungerar mot samma data.
En radlagringstabell kan ha ett icke-grupperat kolumnlagringsindex. Mer information finns i Columnstore-index – designvägledning.
Du kan ha ett eller flera icke-klustrade radlagringsindex i en klustrad kolumnlagringstabell. Genom att göra detta kan du utföra effektiva tabellsökningar på det underliggande kolumnarkivet. Andra alternativ blir också tillgängliga. Du kan till exempel framtvinga unikhet med hjälp av ett UNIQUE villkor för radlagringstabellen. När ett icke-substantivt värde inte kan infogas i radlagringstabellen infogar inte heller databasmotorn värdet i kolumnarkivet.
Prestandaöverväganden för icke-klustrade kolumnlager
Definitionen av det icke-klustrade kolumnlagringsindexet stöder att använda ett filtrervillkor. För att minimera prestandaeffekten av att lägga till ett kolumnlagringsindex använder du ett filteruttryck för att skapa ett icke-klustrat kolumnlagringsindex på endast den datadelmängd som krävs för analys.
En minnesoptimerad tabell kan ha ett kolumnlagringsindex. Du kan skapa den när tabellen skapas eller lägga till den senare med ALTER TABLE.
Mer information finns i Columnstore-index – frågeprestanda.
Designriktlinjer för minnesoptimerad hashindex
När du använderIn-Memory OLTP måste alla minnesoptimerade tabeller ha minst ett index. För en minnesoptimerad tabell är varje index också minnesoptimerad. Hash-index är en av de möjliga indextyperna i en minnesoptimerad tabell. För mer information, se Index över Memory-Optimized-tabeller.
Minnesoptimerad hashindexarkitektur
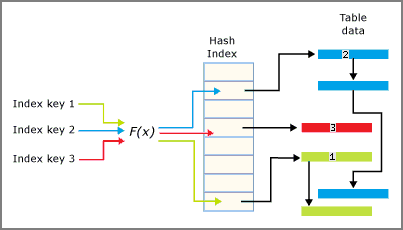
Ett hash-index består av en matris med pekare och varje element i matrisen kallas för en hash-bucket.
- Varje bucket är 8 byte, som används för att lagra minnesadressen för en länklista med nyckelposter.
- Varje post är ett värde för en indexnyckel, plus adressen till motsvarande rad i den underliggande minnesoptimerade tabellen.
- Varje element pekar på nästa element i en länklista med element, alla kopplade till den nuvarande bucketen.
Antalet bucketar måste anges när indexet skapas:
- Desto lägre förhållande mellan bucketar och tabellrader eller distinkta värden, desto längre är den genomsnittliga bucketlänklistan.
- Korta länklistor fungerar snabbare än långa länklistor.
- Det maximala antalet bucketar i hash-index är 1 073 741 824.
Tip
Information om hur du fastställer rätt BUCKET_COUNT för dina data finns i Konfigurera antalet hashindex bucketar.
Hash-funktionen tillämpas på indexnyckelkolumnerna och resultatet av funktionen avgör vilken bucket som nyckeln hamnar i. Varje bucket har en pekare till rader vars hashade nyckelvärden mappas till den bucketen.
Hashfunktionen som används för hash-index har följande egenskaper:
- Databasmotorn har en hash-funktion som används för alla hash-index.
- Hash-funktionen är deterministisk. Samma indatanyckelvärde mappas alltid till samma bucket i hash-indexet.
- Flera indexnycklar kan mappas till samma hash-bucket.
- Hash-funktionen är balanserad, vilket innebär att fördelningen av indexnyckelvärden över hash-bucketar vanligtvis följer en Poisson- eller klockkurvafördelning, inte en platt linjär fördelning.
- Poisson-distribution är inte en jämn fördelning. Indexnyckelvärden är inte jämnt fördelade i hash-bucketarna.
- Om två indexnycklar mappas till samma hash-bucket uppstår en hash-kollision. Ett stort antal hashkollisioner kan ha en prestandaeffekt på läsåtgärder. Ett realistiskt mål är att 30 procent av bucketarna ska innehålla två olika nyckelvärden.
Samspelet mellan hash-indexet och bucketarna sammanfattas i följande bild.
Konfigurera antalet hash-index bucketar
Antalet hash-index bucketar anges vid indexskapandetiden och kan ändras med hjälp av syntaxen ALTER TABLE...ALTER INDEX REBUILD .
I de flesta fall bör antalet bucketar vara mellan 1 och 2 gånger antalet distinkta värden i indexnyckeln.
Du kanske inte alltid kan förutsäga hur många värden en viss indexnyckel har. Prestanda är vanligtvis fortfarande bra om BUCKET_COUNT värdet ligger inom 10 gånger från det faktiska antalet nyckelvärden, och överskattning är i allmänhet bättre än att underskatta.
För få hinkar kan ha följande nackdelar:
- Fler hashkollisioner av distinkta nyckelvärden.
- Varje distinkt värde tvingas dela samma bucket med ett annat distinkt värde.
- Den genomsnittliga kedjelängden per hink växer.
- Ju längre bucketkedjan är, desto långsammare blir hastigheten för likhetssökningar i indexet.
För många hinkar kan ha följande nackdelar:
- Ett för högt antal hinkar kan resultera i fler tomma hinkar.
- Tomma bucketar påverkar prestandan för fullständiga indexgenomsökningar. Om genomsökningar utförs regelbundet bör du överväga att välja ett bucketantal nära antalet distinkta indexnyckelvärden.
- Tomma bucketar använder minne, men varje bucket använder bara 8 byte.
Note
Att lägga till fler bucketar gör ingenting för att minska sammanlänkningen av poster som delar ett duplicerat värde. Värdedupliceringshastigheten används för att avgöra om ett hashindex eller ett icke-grupperat index är lämplig indextyp, inte för att beräkna antalet bucketar.
Prestandaöverväganden för hash-index
Prestanda för ett hash-index är:
- Utmärkt när predikatet
WHEREi -satsen anger ett exakt värde för varje kolumn i hash-indexnyckeln. Ett hashindex övergår till en genomsökning vid ett olikhetspredikat. - Dåligt när predikatet
WHEREi satsen söker efter ett intervall med värden i indexnyckeln. - Dåligt när predikatet
WHEREi -satsen anger ett specifikt värde för den första kolumnen i en hash-indexnyckel för två kolumner, men anger inte något värde för andra kolumner i nyckeln.
Tip
Predikatet måste innehålla alla kolumner i hash-indexnyckeln. Hash-indexet kräver hela nyckeln för att söka i indexet.
Om ett hash-index används och antalet unika indexnycklar är mer än 100 gånger mindre än radantalet kan du överväga att antingen öka till ett större antal bucketar för att undvika stora radkedjor eller använda ett icke-grupperat index i stället.
Skapa ett hash-index
Tänk på följande när du skapar ett hash-index:
- Ett hash-index kan bara finnas i en minnesoptimerad tabell. Den kan inte finnas i en diskbaserad tabell.
- Ett hash-index är inte unikt som standard, men kan deklareras som unikt.
I följande exempel skapas ett unikt hashindex:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Radversioner och sophantering i minnesoptimerade tabeller
När en rad påverkas av en UPDATE instruktion i en minnesoptimerad tabell skapar tabellen en uppdaterad version av raden. Under uppdateringstransaktionen kan andra sessioner läsa den äldre versionen av raden och därmed undvika den prestandaminskning som är associerad med ett radlås.
Hash-indexet kan också ha olika versioner av dess poster för att hantera uppdateringen.
Senare, när de äldre versionerna inte längre behövs, traverserar en GC-tråd bucketarna och deras länklistor för att rensa bort gamla poster. GC-tråden fungerar bättre om länklistens kedjelängder är korta. Mer information, se In-Memory OLTP-sophantering.
Designriktlinjer för minnesoptimerade icke-grupperade index
Förutom hash-index är icke-grupperade index de andra möjliga indextyperna i en minnesoptimerad tabell. För mer information, se Index över Memory-Optimized-tabeller.
Minnesoptimerad icke-klustrad indexarkitektur
Icke-klustrade index i minnesoptimerade tabeller implementeras med hjälp av en datastruktur som kallas Bw-tree, som ursprungligen föreställdes och beskrevs av Microsoft Research året 2011. Ett Bw-träd är en lås- och låsfri variant av ett B-träd. Mer information finns i The Bw-tree: A B-tree for New Hardware Platforms.
På hög nivå kan Bw-trädet tolkas som en karta över sidor ordnade efter sid-ID (PidMap), en möjlighet att allokera och återanvända sid-ID:n (PidAlloc) och en uppsättning sidor som är länkade i sidkartan och till varandra. Dessa tre högnivåunderkomponenter utgör den grundläggande interna strukturen för ett Bw-träd.
Strukturen liknar ett normalt B-träd i den meningen att varje sida har en uppsättning nyckelvärden som är ordnade och det finns nivåer i indexet som var och en pekar på en lägre nivå och lövnivåerna pekar på en datarad. Det finns dock flera skillnader.
Precis som med hash-index kan flera datarader länkas ihop för att stödja versionshantering. Sidpekarna mellan nivåerna är logiska sid-ID:er, som är förskjutningar till en sidmappningstabell, som i sin tur har den fysiska adressen för varje sida.
Det finns inga uppdateringar på plats av indexsidor. Nya delta-sidor har introducerats för detta ändamål.
- Ingen låsning krävs för siduppdateringar.
- Indexsidor är inte en fast storlek.
Nyckelvärdet på varje sida på icke-bladnivå är det högsta värdet som det underordnade objektet som det pekar på innehåller, och varje rad innehåller även sidans logiska sid-ID. På bladsidorna, tillsammans med nyckelvärdet, finns den fysiska adressen för dataraden.
Punktsökningar liknar B-träd, men eftersom sidorna bara är länkade i en riktning, följer databasmotorn högersidpekare. Varje icke-bladsida har det högsta värdet hos sitt underordnade, i stället för det lägsta värdet som i ett B-träd.
Om en sida på lövnivå måste ändras ändrar inte databasmotorn själva sidan. I stället skapar databasmotorn en deltapost som beskriver ändringen och lägger till den på föregående sida. Sedan uppdateras även sidkartans tabelladress för den föregående sidan till adressen för deltaposten som nu blir den fysiska adressen för den här sidan.
Det finns tre olika åtgärder som kan krävas för att hantera strukturen för ett Bw-träd: konsolidering, delning och sammanslagning.
Deltakonsolidering
En lång kedja med deltaposter kan så småningom försämra sökprestanda eftersom det kan kräva lång kedjegenomgång vid sökning genom ett index. Om en ny deltapost läggs till i en kedja som redan har 16 element konsolideras ändringarna i deltaposterna till den refererade indexsidan och sidan återskapas sedan, inklusive de ändringar som anges av den nya deltaposten som utlöste konsolideringen. Den nyligen återskapade sidan har samma sid-ID men en ny minnesadress.
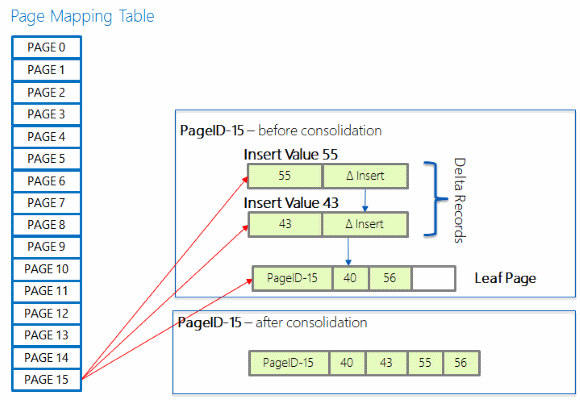
Dela upp sida
En indexsida i Bw-tree växer efter behov från att lagra en enskild rad till att lagra högst 8 kB. När indexsidan växer till 8 kB får en ny infogning av en enskild rad indexsidan att delas. För en intern sida innebär detta att det inte finns mer utrymme för att lägga till ytterligare ett nyckelvärde och pekare. För en bladsida innebär det att raden skulle vara för stor för att få plats på sidan när alla deltaposter har införlivats. Statistik i sidhuvudet för en bladsida håller reda på hur mycket utrymme som krävs för att sammanfoga deltaposterna. Den här informationen justeras när varje ny deltapost läggs till.
En delningsåtgärd utförs i två atomiska steg. I följande diagram antas det att en bladnivåsida tvingar fram en delning eftersom en nyckel med värdet 5 infogas, och det finns en icke-bladnivåsida som pekar mot slutet av den aktuella bladnivåsidan (nyckelvärde 4).

Steg 1: Allokera två nya sidor P1 och P2, och dela upp raderna från den gamla P1 sidan på dessa nya sidor, inklusive den nyligen infogade raden. Ett nytt fack i tabellen för sidmappning används för att lagra den fysiska adressen för sidan P2. Sidor P1 och P2 är inte tillgängliga för några samtidiga åtgärder ännu. Dessutom anges den logiska pekaren från P1 till P2 . I ett atomärt steg uppdaterar du sedan tabellen för sidmappning för att ändra pekaren från gammal P1 till ny P1.
Steg 2: Icke-bladsidan pekar på P1 men det finns ingen direkt pekare från en icke-bladsida till P2.
P2 kan endast nås via P1. Om du vill skapa en pekare från en icke-bladsida till P2, allokera en ny icke-bladsida (intern indexsida), kopiera alla rader från den gamla icke-bladsidan och lägg till en ny rad som pekar på P2. När detta är klart uppdaterar du tabellen för sidmappning i ett atomiskt steg för att ändra pekaren från den gamla icke-bladsidan till den nya icke-bladsidan.
Sammanfoga sida
När en DELETE åtgärd resulterar i att en sida har mindre än 10 procent av den maximala sidstorleken (8 KB), eller med en enda rad på sidan, sammanfogas den sidan med en sammanhängande sida.
När en rad tas bort från en sida läggs en deltapost för borttagningen till. Dessutom görs en kontroll för att avgöra om indexsidan (icke-bladsida) kvalificerar sig för sammanslagning. Den här kontrollen verifierar om återstående utrymme efter borttagning av raden är mindre än 10 procent av den maximala sidstorleken. Om den kvalificerar sig utförs sammanfogningen i tre atomsteg.
Anta att en DELETE åtgärd tar bort nyckelvärdet 10 i följande bild.

Steg 1: En deltasida som representerar nyckelvärdet 10 (blå triangel) skapas och dess pekare på sidan nonleaf Pp1 är inställd på den nya deltasidan. Dessutom skapas en särskild merge-delta-sida (grön triangel) och den länkas till deltasidan. I det här skedet är båda sidorna (deltasidan och merge-delta-sidan) inte synliga för någon samtidig transaktion. I ett atomärt steg uppdateras pekaren till bladnivåsidan P1 i sidmappningstabellen så att den pekar på sammanslagnings-deltasidan. Efter detta steg leder posten för nyckelvärdet 10 i Pp1 nu till sidan merge-delta.
Steg 2: Raden som representerar nyckelvärdet 7 på sidan Pp1 nonleaf måste tas bort och posten för nyckelvärdet 10 uppdateras så att den pekar på P1. För att göra detta allokeras en ny icke-af-sida Pp2 och alla rader från Pp1 kopieras, förutom raden som representerar nyckelvärdet 7. Sedan uppdateras raden för nyckelvärdet 10 så att den pekar på sidan P1. När detta är klart, uppdateras i ett atomärt steg posten i sidmappningstabellen som pekar på Pp1 så att den pekar på Pp2.
Pp1 kan inte längre nås.
Steg 3: Bladnivåsidorna P2 och P1 sammanfogas och deltasidorna tas bort. För att göra detta allokeras en ny sida P3 och raderna från P2 och P1 sammanfogas, och ändringarna på deltasidan inkluderas i den nya P3. I ett atomärt steg uppdateras sidmappningstabellposten som pekar på sidan P1 så att den pekar på sidan P3.
Prestandaöverväganden för minnesoptimerade icke-grupperade index
Prestandan för ett icke-grupperat index är bättre än med hash-index när du kör frågor mot en minnesoptimerad tabell med olikhetspredikat.
En kolumn i en minnesoptimerad tabell kan ingå i både ett hash-index och ett icke-grupperat index.
När en nyckelkolumn i ett icke-grupperat index har många duplicerade värden kan prestanda försämras för uppdateringar, infogningar och borttagningar. Ett sätt att förbättra prestanda i den här situationen är att lägga till en kolumn som har bättre selektivitet i indexnyckeln.
Indexmetadata
Om du vill undersöka indexmetadata som indexdefinitioner, egenskaper och datastatistik använder du följande systemvyer:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Föregående vyer gäller för alla indextyper. För columnstore-index använder du dessutom följande vyer:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
För kolumnlagringsindex lagras alla kolumner i metadata som inkluderade kolumner. Kolumnlagringsindexet har inga nyckelkolumner.
För index på minnesoptimerade tabeller använder du dessutom följande vyer:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Relaterat innehåll
- SKAPA INDEX (Transact-SQL)
- Optimera indexunderhåll för att förbättra frågeprestanda och minska resursförbrukningen
- Partitionerade tabeller och index
- Index för Memory-Optimized-tabeller
- Columnstore-indexar: översikt
- Indexar på beräknade kolumner
- Justera icke-klustrade index med förslag på saknade index