Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Gäller för:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-databas i Förhandsversion av Microsoft Fabric
SQL-databas i Förhandsversion av Microsoft Fabric
Funktionen för saknade index är ett enkelt verktyg för att hitta saknade index som avsevärt kan förbättra frågeprestandan. Den här artikeln beskriver hur du använder indexförslag som saknas för att effektivt justera index och förbättra frågeprestanda.
Begränsningar för den saknade indexfunktionen
När frågeoptimeraren genererar en frågeplan analyseras vilka de bästa indexen är för ett visst filtervillkor. Om de bästa indexen inte finns genererar frågeoptimeraren fortfarande en frågeplan med hjälp av de lägsta tillgängliga åtkomstmetoderna, men lagrar även information om dessa index. Med funktionen för saknade index kan du komma åt den informationen om bästa möjliga index så att du kan bestämma om de ska implementeras.
Frågeoptimering är en tidskänslig process, så det finns begränsningar för den saknade indexfunktionen. Begränsningarna omfattar:
- Förslag på saknade index baseras på uppskattningar som gjorts under optimeringen av en enskild fråga, före körning av frågan. Indexförslag som saknas testas eller uppdateras inte när en fråga har körts.
- Den saknade indexfunktionen föreslår endast icke-klustrade diskbaserade radlagringsindex. Unika och filtrerade index föreslås inte.
- Viktiga kolumner föreslås, men förslaget anger ingen ordning för dessa kolumner. Information om hur du beställer kolumner finns i avsnittet Tillämpa indexförslag som saknas i den här artikeln.
- Inkluderade kolumner föreslås, men SQL Server utför ingen kostnads-nyttoanalys när det gäller storleken på det resulterande indexet när ett stort antal inkluderade kolumner föreslås.
- Saknade indexbegäranden kan erbjuda liknande varianter av index i samma tabell och kolumner mellan frågor. Det är viktigt att granska indexförslag och kombinera när det är möjligt.
- Förslag görs inte för triviala frågeplaner.
- Kostnadsinformationen är mindre exakt för frågor som endast rör ojämlikhetspredikat.
- Förslag samlas in för högst 600 indexgrupper som saknas. När det här tröskelvärdet har nåtts samlas inga fler saknade indexgruppsdata in.
På grund av dessa begränsningar behandlas indexförslag som saknas bäst som en av flera informationskällor när indexanalys, design, justering och testning utförs. Indexförslag som saknas är inte recept för att skapa index exakt som föreslås.
Note
Azure SQL Database erbjuder automatisk indexjustering. Automatisk indexjustering använder maskininlärning för att lära sig horisontellt från alla databaser i Azure SQL Database via AI och dynamiskt förbättra sina justeringsåtgärder. Automatisk indexjustering innehåller en verifieringsprocess för att säkerställa en positiv förbättring av arbetsbelastningens prestanda från index som skapats.
Visa indexrekommendationer som saknas
Funktionen för saknade index består av två komponenter:
- Elementet
MissingIndexesi XML:et av exekveringsplaner. På så sätt kan du korrelera index som frågeoptimeraren anser saknas med de frågor som de saknas för. - En uppsättning dynamiska hanteringsvyer (DMV:er) som kan efterfrågas för att returnera information om saknade index. På så sätt kan du visa alla indexrekommendationer som saknas för en databas.
Visa förslag på saknade index i exekveringsplaner
Översikt över körningsplan kan genereras eller hämtas på flera sätt:
- När du skriver eller justerar en fråga kan du använda SQL Server Management Studio (SSMS) för att visa den uppskattade körningsplanen utan att köra frågan, eller köra frågan och visa en faktisk körningsplan.
- Övervaka prestanda med hjälp av Query Store, när det är aktiverat, samlar in körningsplaner.
- Du kan identifiera cachelagrade körningsplaner genom att fråga DMV:er, till exempel sys.dm_exec_text_query_plan.
Du kan till exempel använda följande fråga för att generera saknade indexbegäranden mot AdventureWorks-exempeldatabaserna.
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
Så här genererar och visar du de saknade indexbegäranden:
Öppna SSMS och anslut en session till din kopia av AdventureWorks-exempeldatabaserna.
Klistra in frågan i sessionen och generera en uppskattad körningsplan i SSMS för frågan genom att välja verktygsfältet Visa uppskattad körningsplan . Körningsplanen visas i ett fönster i den aktuella sessionen. En grön Saknat Index-instruktion visas nära toppen av den grafiska planen.

En enda körningsplan kan innehålla flera saknade indexbegäranden, men endast en indexbegäran som saknas kan visas i den grafiska körningsplanen. Ett alternativ för att visa en fullständig lista över saknade index för en exekveringsplan är att visa exekveringsplanens XML.
Högerklicka på körningsplanen och välj Visa XML för körningsplan... i menyn.

XML-koden för körningsplanen öppnas som en ny flik i SSMS.
Note
Endast ett enda indexförslag som saknas visas i menyalternativet Indexinformation saknas... även om flera förslag finns i XML-körningsplanen. Det saknade indexförslaget som visas kanske inte är det som har den högsta uppskattade förbättringen för frågan.
Visa dialogrutan Sök med hjälp av genvägen CTRL+f .
Sök efter
MissingIndex.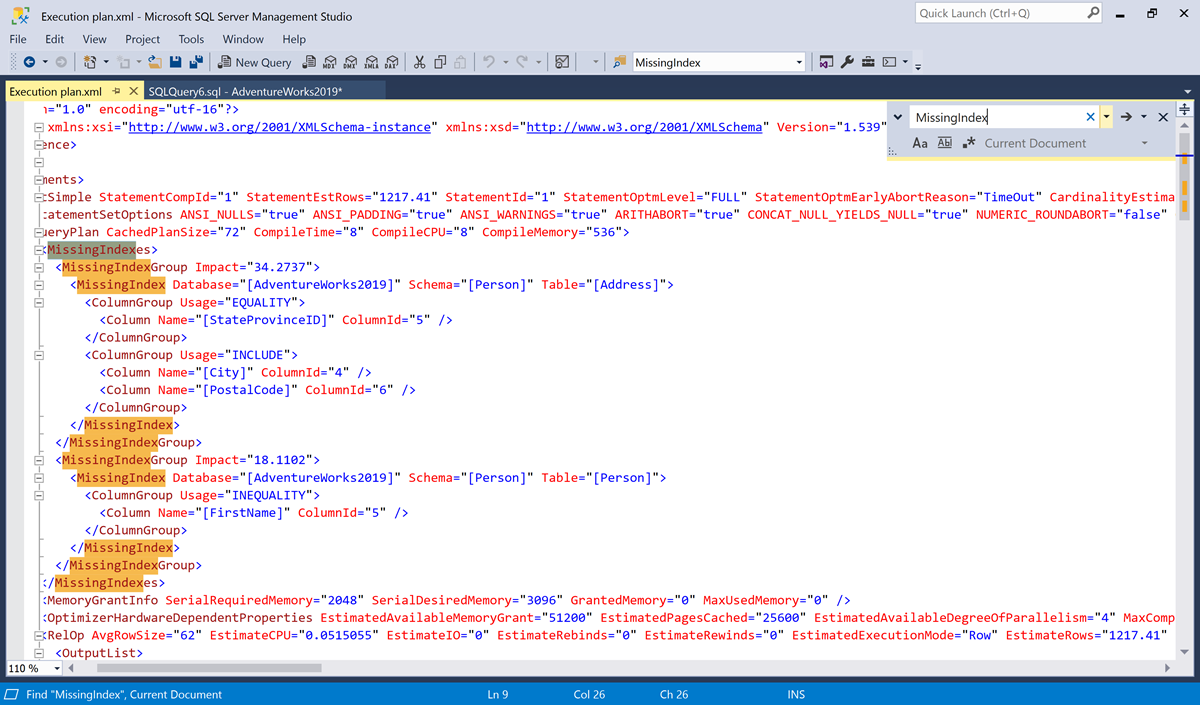
I det här exemplet finns det två
MissingIndexelement.- Det första index som saknas antyder att frågan kan använda ett index i
Person.Addresstabellen som stöder en likhetssökning iStateProvinceIDkolumnen, som innehåller ytterligare två kolumner ochCityPostalCode. Vid tidpunkten för optimeringen trodde frågeoptimeraren att det här indexet skulle kunna minska den uppskattade kostnaden för frågan med 34,2737%. - Det andra indexet som saknas antyder att frågan kan använda ett index i
Person.Persontabellen som stöder en ojämlikhetssökning i kolumnen FirstName. Vid tidpunkten för optimeringen trodde frågeoptimeraren att det här indexet skulle kunna minska den uppskattade kostnaden för frågan med 18,1102%.
- Det första index som saknas antyder att frågan kan använda ett index i


Varje diskbaserad icke-klustrad index i databasen tar plats, lägger till overhead för infogningar, uppdateringar och borttagningar och kan kräva underhåll. Därför är det bästa praxis att granska alla saknade indexbegäranden för en tabell och befintliga index i en tabell innan du lägger till ett index baserat på en frågekörningsplan.
Visa indexförslag som saknas i DMV:er
Du kan hämta information om saknade index genom att köra frågor mot de dynamiska hanteringsobjekt som anges i följande tabell.
| Dynamisk hanteringsvy | Information som returneras |
|---|---|
| sys.dm_db_missing_index_group_stats | Returnerar sammanfattningsinformation om saknade indexgrupper, till exempel de prestandaförbättringar som kan uppnås genom att implementera en specifik grupp med saknade index. |
| sys.dm_db_missing_index_groups | Returnerar information om en specifik grupp med saknade index, till exempel gruppidentifierare och identifierare för alla saknade index som finns i den gruppen. |
| sys.dm_db_missing_index_details | Returnerar detaljerad information om ett index som saknas. Den returnerar till exempel namnet och identifieraren för tabellen där indexet saknas och de kolumner och kolumntyper som ska utgöra det saknade indexet. |
| sys.dm_db_missing_index_columns | Returnerar information om de databastabellkolumner som saknar ett index. |
Följande fråga använder de saknade index-DMV:erna för att generera CREATE INDEX instruktioner. Skapandeinstruktionerna för index här är avsedda att hjälpa dig att skapa en egen DDL när du har granskat alla begäranden för tabellen tillsammans med befintliga index i tabellen.
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
Den här frågan ordnar förslagen efter en kolumn med namnet estimated_improvement. Den uppskattade förbättringen baseras på en kombination av:
- Den uppskattade frågekostnaden för frågor som är associerade med den saknade indexbegäran.
- Den uppskattade effekten av att lägga till indexet. Det här är en uppskattning av hur mycket det icke-klustrade indexet skulle minska sökfrågekostnaden.
- Summan av körningar av frågeoperatorer (sökningar och genomsökningar) som har körts för frågor som är associerade med den saknade indexbegäran. Som vi diskuterar i bevara saknade index med Query Store rensas den här informationen regelbundet.
Note
Skriptet Index-Creation i Microsofts Tiger Toolbox undersöker saknade index-DMV:er och tar automatiskt bort alla redundanta föreslagna index, parsar ut index med låg påverkan och genererar skript för att skapa index för din granskning. Precis som i frågan ovan kör den NOT kommandon för att skapa index. Skriptet Index-Creation är lämpligt för SQL Server och Azure SQL Managed Instance. Överväg att implementera automatisk indexjustering för Azure SQL Database.
Granska begränsningar för den saknade indexfunktionen och hur du tillämpar indexförslag som saknas innan du skapar index, och ändra indexnamnet så att det matchar namngivningskonventionen för databasen.
Bevara saknade index med Query Store
Saknande indexförslag i DMV:er rensas av händelser såsom omstart av instanser, failover-händelser och att ställa en databas offline. När metadata för en tabell ändras tas dessutom all information om tabellen som saknas bort från dessa dynamiska hanteringsobjekt. Ändringar i tabellmetadata kan ske när kolumner läggs till eller tas bort från en tabell, till exempel eller när ett index skapas i en kolumn i en tabell. Om du utför en ALTER INDEX-åtgärd på ett index i en tabell rensas även saknade indexbegäranden för den tabellen.
På samma sätt rensas körningsplaner som lagras i plancachen av händelser som omstarter av instanser, redundans och offlineinställning av en databas. Körningsplaner kan tas bort från cacheminnet till följd av minnestryck och omkompileringar.
Indexförslag som saknas i körningsplaner kan sparas mellan dessa händelser genom att aktivera Övervakningsprestanda med hjälp av Query Store.
Följande fråga hämtar de 20 främsta frågeplanerna som innehåller saknade indexbegäranden från Query Store baserat på en grov uppskattning av de totala logiska läsningarna för frågan. Datan är begränsad till frågekörningar under de senaste 48 timmarna.
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
Tillämpa indexförslag som saknas
Om du vill använda indexförslag som saknas på ett effektivt sätt följer du riktlinjerna för design av icke-klustrade index. När du justerar icke-klustrade index med saknade indexförslag, granska bastabellstrukturen, kombinera index noggrant, överväg ordning på nyckelkolumner och granska inkluderade kolumnförslag.
Granska bastabellstrukturen
Granska tabellens klustrade index innan du skapar icke-grupperade index i en tabell baserat på saknade indexförslag.
Ett sätt att söka efter ett grupperat index är genom att använda den systemlagrade proceduren sp_helpindex. Vi kan till exempel visa en sammanfattning av indexen i tabellen Person.Address genom att köra följande instruktion:
exec sp_helpindex 'Person.Address';
GO
Granska kolumnen index_description. En tabell kan bara ha ett grupperat index. Om ett klustrat index har implementerats för tabellen, kommer index_description att innehålla ordet "klustrad".

Om det inte finns något klustrat index är tabellen en heap. I det här fallet ska du undersöka om tabellen avsiktligt skapades som en heap för att lösa ett specifikt prestandaproblem. De flesta tabeller drar nytta av klustrade index: ofta implementeras tabeller som heaps av misstag. Överväg att implementera ett klustrat index baserat på de klustrade index-designriktlinjerna .
Granska saknade index och befintliga index för överlappning
Index som saknas kan erbjuda liknande varianter av icke-grupperade index i samma tabell och kolumner mellan frågor. Index som saknas kan också likna befintliga index i en tabell. För optimala prestanda är det bäst att undersöka saknade index och befintliga index för överlappning och undvika att skapa duplicerade index.
Skripta ut befintliga index i en tabell
Ett sätt att undersöka definitionen av befintliga index i en tabell är att skripta ut indexen med Object Explorer-information:
- Anslut Object Explorer till din instans eller databas.
- Expandera noden för den aktuella databasen i Object Explorer.
- Öppna och expandera mappen Tables.
- Expandera tabellen som du vill skriva ut index för.
- Välj mappen Index .
- Om informationsfönstret Objektutforskaren inte redan är öppet går du till menyn Visa och väljer Objektutforskarens information eller trycker på F7.
- Markera alla index som visas i fönstret Objektutforskarens information med genvägen CTRL+a.
- Högerklicka var som helst i den valda regionen och välj menyalternativet Skriptindex som, sedan
CREATETill** och Nytt frågeredigerarefönster.

Granska index och kombinera där det är möjligt
Granska de indexrekommendationer som saknas för en tabell som en grupp, tillsammans med definitionerna av befintliga index i tabellen. Kom ihåg att när du definierar index bör i allmänhet likhetskolumner placeras före ojämlikhetskolumnerna, och tillsammans bör de utgöra nyckeln för indexet. För att fastställa en effektiv ordning för likhetskolumnerna beställer du dem baserat på deras selektivitet: lista de mest selektiva kolumnerna först (längst till vänster i kolumnlistan). Unika kolumner är mest selektiva, medan kolumner med många upprepade värden är mindre selektiva.
Inkluderade kolumner ska läggas till i -instruktionen CREATE INDEX med hjälp av INCLUDE -satsen. Ordningen på inkluderade kolumner påverkar inte frågeprestanda. När du kombinerar index kan därför inkluderade kolumner kombineras utan att du behöver bekymra dig om ordning. Läs mer i riktlinjerna för inkluderade kolumner.
Du kan till exempel ha en tabell, Person.Address, med ett befintligt index i nyckelkolumnen StateProvinceID. Du kan se saknade indexrekommendationer för Person.Address tabellen för följande kolumner:
- EQUALITY-filter för
StateProvinceIDochCity - EQUALITY-filter för
StateProvinceIDochCity,INCLUDEPostalCode
Om du ändrar det befintliga indexet så att det matchar den andra rekommendationen skulle ett index med nycklar på StateProvinceID och City inklusive PostalCode, sannolikt uppfylla de frågor som genererade båda indexförslagen.
Kompromisser är vanliga vid indexjustering. Det är troligt att för många datauppsättningar City är kolumnen mer selektiv än StateProvinceID kolumnen. Men om vårt befintliga index på StateProvinceID används kraftigt och andra begäranden till stor del söker på båda StateProvinceID och City, är det lägre omkostnader för databasen i allmänhet att ha ett enda index med båda kolumnerna i nyckeln, vilket leder till StateProvinceID, även om det inte är den mest selektiva kolumnen.
Index kan ändras på flera sätt:
- Du kan använda CREATE INDEX-instruktionen tillsammans med DROP_EXISTING-satsen. Du kanske vill byta namn på indexen efter ändringen så att namnet fortfarande korrekt beskriver indexdefinitionen, beroende på din namngivningskonvention.
- Du kan använda instruktionen DROP INDEX (Transact-SQL) följt av en CREATE INDEX-instruktion.
Indexnycklarnas ordning är viktig när indexförslagen kombineras: City eftersom en inledande kolumn skiljer sig från StateProvinceID en inledande kolumn. Läs mer i riktlinjer för icke-indexdesign.
När du skapar index bör du överväga att använda onlineindexåtgärder när de är tillgängliga.
Index kan avsevärt förbättra frågeprestanda i vissa fall, men index har även kostnader för omkostnader och hantering. Granska allmänna riktlinjer för indexdesign för att utvärdera fördelarna med index innan du skapar dem.
Kontrollera om indexändringen lyckas
Det är viktigt att bekräfta om indexändringarna har lyckats: använder frågeoptimeraren dina index?
Ett sätt att verifiera dina indexändringar är att använda Query Store för att identifiera frågor med saknade indexbegäranden. Observera query_id för frågorna. Använd vyn för Spårade frågor i Query Store för att kontrollera om exekveringsplanerna har ändrats för en fråga och om optimeraren använder det nya eller modifierade indexet. Läs mer om spårade frågor i början med felsökning av frågeprestanda.