Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO: All API Management tiers
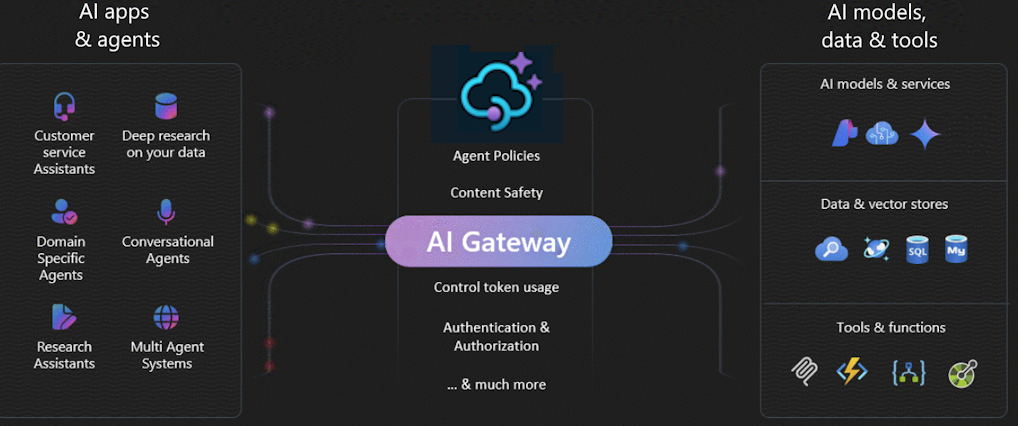
The AI gateway in Azure API Management is a set of capabilities that help you manage your AI backends effectively. These capabilities help you manage, secure, scale, monitor, and govern large language model (LLM) deployments, AI APIs, and Model Context Protocol (MCP) servers that back your intelligent apps and agents.
Use the AI gateway to manage a wide range of AI endpoints, including:
- Azure AI Foundry and Azure OpenAI in Azure AI Foundry Models deployments
- Azure AI Model Inference API deployments
- Remote MCP servers
- OpenAI-compatible models and endpoints hosted by non-Microsoft providers
- Self-hosted models and endpoints
Note
The AI gateway, including MCP server capabilities, extends API Management's existing API gateway; it isn't a separate offering. Related governance and developer features are in Azure API Center.
Why use an AI gateway?
AI adoption in organizations involves several phases:
- Defining requirements and evaluating AI models
- Building AI apps and agents that need access to AI models and services
- Operationalizing and deploying AI apps and backends to production
As AI adoption matures, especially in larger enterprises, the AI gateway helps address key challenges, helping to:
- Authenticate and authorize access to AI services
- Load balance across multiple AI endpoints
- Monitor and log AI interactions
- Manage token usage and quotas across multiple applications
- Enable self-service for developer teams
Traffic mediation and control
With the AI gateway, you can:
- Quickly import and configure OpenAI-compatible or passthrough LLM endpoints as APIs
- Manage models deployed in Azure AI Foundry or providers such as Amazon Bedrock
- Govern chat completions, responses, and real-time APIs
- Expose your existing REST APIs as MCP servers, and support passthrough to MCP servers
For example, to onboard a model deployed in AI Foundry or another provider, API Management provides streamlined wizards to import the schema and set up authentication to the AI endpoint by using a managed identity, removing the need for manual configuration. Within the same user-friendly experience, you can preconfigure policies for API scalability, security, and observability.

More information:
- Import an AI Foundry API
- Import a language model API
- Expose a REST API as an MCP server
- Expose and govern an existing MCP server
Scalability and performance
One of the main resources in generative AI services is tokens. Azure AI Foundry and other providers assign quotas for your model deployments as tokens-per-minute (TPM). You distribute these tokens across your model consumers, such as different applications, developer teams, or departments within the company.
If you have a single app connecting to an AI service backend, you can manage token consumption with a TPM limit that you set directly on the model deployment. However, when your application portfolio grows, you might have multiple apps calling single or multiple AI service endpoints. These endpoints can be pay-as-you-go or Provisioned Throughput Units (PTU) instances. You need to make sure that one app doesn't use the whole TPM quota and block other apps from accessing the backends they need.
Token rate limiting and quotas
Configure a token limit policy on your LLM APIs to manage and enforce limits per API consumer based on the usage of AI service tokens. With this policy, you can set a TPM limit or a token quota over a specified period, such as hourly, daily, weekly, monthly, or yearly.
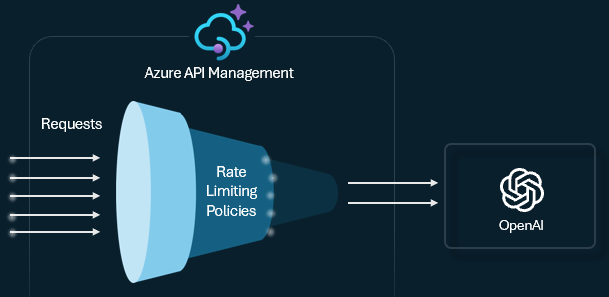
This policy provides flexibility to assign token-based limits on any counter key, such as subscription key, originating IP address, or an arbitrary key defined through a policy expression. The policy also enables precalculation of prompt tokens on the Azure API Management side, minimizing unnecessary requests to the AI service backend if the prompt already exceeds the limit.
The following basic example demonstrates how to set a TPM limit of 500 per subscription key:
<llm-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</llm-token-limit>
More information:
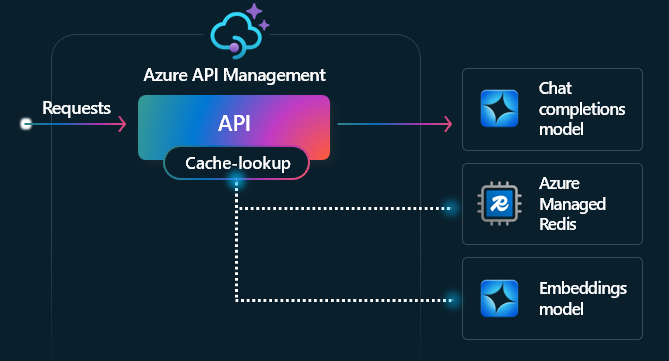
Semantic caching
Semantic caching is a technique that improves the performance of LLM APIs by caching the results (completions) of previous prompts and reusing them by comparing the vector proximity of the prompt to prior requests. This technique reduces the number of calls made to the AI service backend, improves response times for end users, and can help reduce costs.
In API Management, enable semantic caching by using Azure Managed Redis or another external cache compatible with RediSearch and onboarded to Azure API Management. By using the Embeddings API, the llm-semantic-cache-store and llm-semantic-cache-lookup policies store and retrieve semantically similar prompt completions from the cache. This approach ensures completions reuse, resulting in reduced token consumption and improved response performance.
More information:
- Set up an external cache in Azure API Management
- Enable semantic caching for AI APIs in Azure API Management
Native scaling features in API Management
API Management also provides built-in scaling features to help the gateway handle high volumes of requests to your AI APIs. These features include automatic or manual addition of gateway scale units and addition of regional gateways for multiregion deployments. Specific capabilities depend on the API Management service tier.
More information:
Note
While API Management can scale gateway capacity, you also need to scale and distribute traffic to your AI backends to accommodate increased load (see the Resiliency section). For example, to take advantage of geographical distribution of your system in a multiregion configuration, you should deploy backend AI services in the same regions as your API Management gateways.
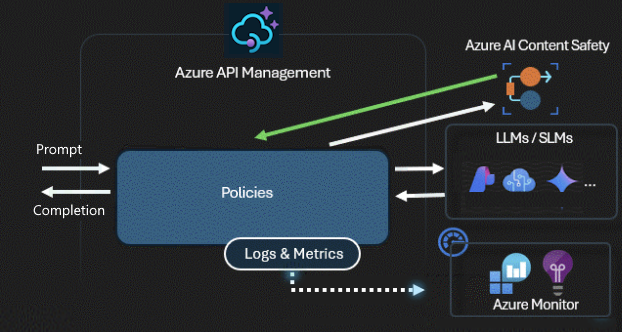
Security and safety
An AI gateway secures and controls access to your AI APIs. With the AI gateway, you can:
- Use managed identities to authenticate to Azure AI services, so you don't need API keys for authentication
- Configure OAuth authorization for AI apps and agents to access APIs or MCP servers by using API Management's credential manager
- Apply policies to automatically moderate LLM prompts by using Azure AI Content Safety
More information:
- Authenticate and authorize access to Azure OpenAI APIs
- About API credentials and credential manager
- Enforce content safety checks on LLM requests
Resiliency
One challenge when building intelligent applications is ensuring that the applications are resilient to backend failures and can handle high loads. By configuring your LLM endpoints with backends in Azure API Management, you can balance the load across them. You can also define circuit breaker rules to stop forwarding requests to AI service backends if they're not responsive.
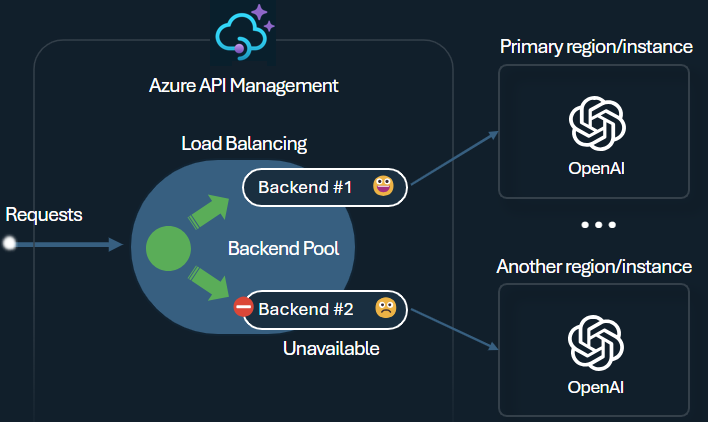
Load balancer
The backend load balancer supports round-robin, weighted, priority-based, and session-aware load balancing. You can define a load distribution strategy that meets your specific requirements. For example, define priorities within the load balancer configuration to ensure optimal utilization of specific Azure AI Foundry endpoints, particularly those purchased as PTU instances.
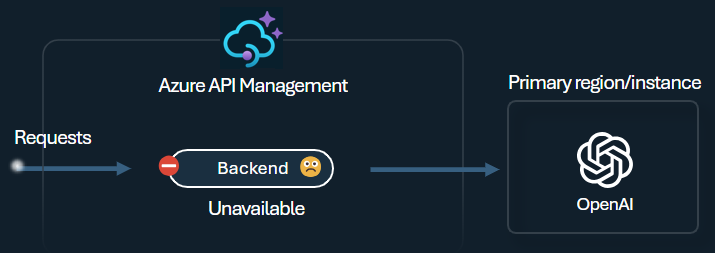
Circuit breaker
The backend circuit breaker features dynamic trip duration, applying values from the Retry-After header provided by the backend. This feature ensures precise and timely recovery of the backends, maximizing the utilization of your priority backends.
More information:
Observability and governance
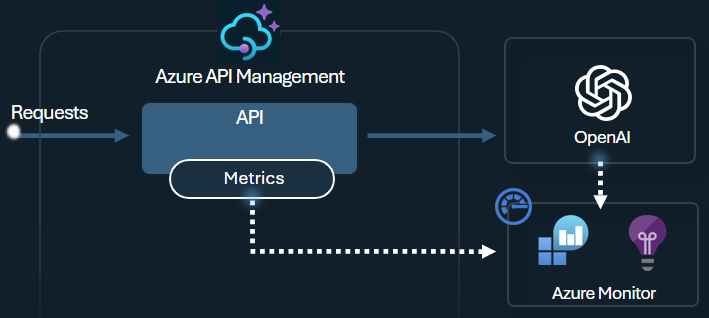
API Management provides comprehensive monitoring and analytics capabilities to track token usage patterns, optimize costs, ensure compliance with your AI governance policies, and troubleshoot issues with your AI APIs. Use these capabilities to:
- Log prompts and completions to Azure Monitor
- Track token metrics per consumer in Application Insights
- View the built-in monitoring dashboard
- Configure policies with custom expressions
- Manage token quotas across applications
For example, you can emit token metrics with the llm-emit-token-metric policy and add custom dimensions you can use to filter the metric in Azure Monitor. The following example emits token metrics with dimensions for client IP address, API ID, and user ID (from a custom header):
<llm-emit-token-metric namespace="llm-metrics">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</llm-emit-token-metric>
Also, enable logging for LLM APIs in Azure API Management to track token usage, prompts, and completions for billing and auditing. After you enable logging, you can analyze the logs in Application Insights and use a built-in dashboard in API Management to view token consumption patterns across your AI APIs.

More information:
Developer experience
Use the AI gateway and Azure API Center to streamline development and deployment of your AI APIs and MCP servers. In addition to the user-friendly import and policy configuration experiences for common AI scenarios in API Management, you can take advantage of:
- Easy registration of APIs and MCP servers in an organizational catalog in Azure API Center
- Self-service API and MCP server access through developer portals in API Management and API Center
- API Management policy toolkit for customization
- API Center Copilot Studio connector to extend the capabilities of AI agents
More information:
- Register and discover MCP servers in API Center
- Synchronize APIs and MCP servers between API Management and API Center
- API Management developer portal
- API Center portal
- Azure API Management policy toolkit
- API Center Copilot Studio connector
Early access to AI gateway features
As an API Management customer, you can get early access to new features and capabilities through the AI Gateway release channel. This access lets you try out the latest AI gateway innovations before they're generally available and provide feedback to help shape the product.
More information:
Labs and code samples
- AI gateway capabilities labs
- AI gateway workshop
- Azure OpenAI with API Management (Node.js)
- Python sample code
Architecture and design
- AI gateway reference architecture using API Management
- AI hub gateway landing zone accelerator
- Designing and implementing a gateway solution with Azure OpenAI resources
- Use a gateway in front of multiple Azure OpenAI deployments