在本教程中,你将基于存储为语义模型(Power BI 数据集)的 Power BI 分析师的工作。 通过在 Microsoft Fabric 的 Synapse 数据科学体验中使用 SemPy (预览版),可以分析 DataFrame 列中的功能依赖关系。 此分析可帮助你发现微妙的数据质量问题,以获得更准确的见解。
本教程介绍如何:
- 应用域知识来构建有关语义模型中功能依赖关系的假设。
- 熟悉与 Power BI 集成的语义链接 Python 库 (SemPy) 的组件,并帮助自动执行数据质量分析。 这些组件包括:
- FabricDataFrame - 使用其他语义信息增强的 pandas 类结构
- 将语义模型从 Fabric 工作区拉取到笔记本中的函数
- 评估函数依赖项假设并识别语义模型中的关系冲突的函数
先决条件
获取 Microsoft Fabric 订阅。 或者,注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左下侧的体验切换器切换到 Fabric。
从导航窗格中选择 工作区 以查找并选择工作区。 这个工作区会成为你的当前工作区。
在工作区中,选择“导入”“报表或分页报表”>“从此计算机”,将“客户盈利率示例.pbix”文件上传到工作区>。
在笔记本中继续操作
本教程随附 powerbi_dependencies_tutorial.ipynb 笔记本。
若要打开本教程随附的笔记本,请按照 为数据科学教程准备系统 中的说明将笔记本导入工作区。
如果要复制并粘贴此页面中的代码,可以 创建新的笔记本。
在开始运行代码之前,请务必将湖屋连接到笔记本。
设置笔记本
使用所需的模块和数据设置笔记本环境。
用于
%pip在笔记本中从 PyPI 安装 SemPy。%pip install semantic-link导入所需的模块。
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
加载和预处理数据
本教程使用标准示例语义模型 客户盈利率样本.pbix。 有关语义模型的说明,请参阅 Power BI 的客户盈利率示例。
使用
fabric.read_table函数将 Power BI 数据加载到 aFabricDataFrame。dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()将
State表加载到 .FabricDataFramestate = fabric.read_table(dataset, "State") state.head()尽管输出类似于 pandas 数据帧,但此代码初始化一个名为“
FabricDataFrame在 pandas 上添加作”的数据结构。检查 . 的
customer数据类型。type(customer)输出显示为
customersempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.customer联接和stateDataFrame对象。customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
识别功能依赖项
函数依赖关系是一对多关系,介于两列或多列中 DataFrame的值之间的一对多关系。 使用这些关系自动检测数据质量问题。
在合并
DataFrame时运行 SemPy 的find_dependencies函数,以确定列值之间的功能依赖关系。dependencies = customer_state_df.find_dependencies() dependencies使用 SemPy 的
plot_dependency_metadata函数可视化依赖项。plot_dependency_metadata(dependencies)
函数依赖关系图显示列
Customer确定列,例如City,Postal Code和Name。该图不显示函数依赖关系
CityPostal Code,可能是因为列之间的关系存在许多冲突。 使用 SemPy 的plot_dependency_violations函数直观显示特定列之间的依赖关系冲突。

探索数据以查找质量问题
使用 SemPy 的
plot_dependency_violations可视化函数绘制图形。customer_state_df.plot_dependency_violations('Postal Code', 'City')
依赖项冲突的绘图显示左侧的值
Postal Code,以及右侧的值City。 如果存在包含这两个值的行,边缘将左侧的Postal Code与右侧的City连接。 边缘使用此类行的计数进行批注。 例如,有两行包含邮政编码 20004,一行包含城市“北塔”,另一行包含城市“华盛顿”。绘图还显示了一些冲突和许多空值。
确认
Postal Code的空值数:customer_state_df['Postal Code'].isna().sum()50 行具有 NA。
Postal Code删除具有空值的行。 然后,使用
find_dependencies函数查找依赖项。 请注意额外的参数verbose=1,该参数可瞥见 SemPy 的内部工作:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)Postal Code和City的条件熵为 0.049。 此值指示存在功能依赖项冲突。 在解决冲突之前,将条件萎缩阈值从默认值0.01提高到0.05,只需查看依赖项即可。 较低的阈值会导致依赖项减少(或更高的选择性)。将条件萎缩的阈值从默认值
0.01提高到0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))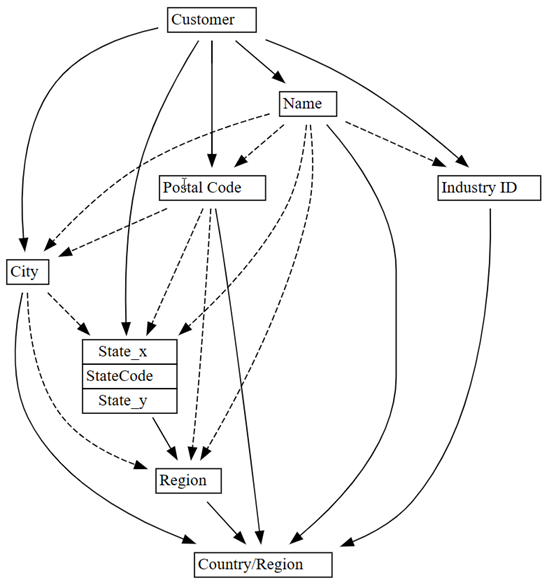
如果应用域知识来确定其他实体的值,则此依赖项关系图似乎准确无误。
探索检测到的更多数据质量问题。 例如,虚线箭头联接
City和Region,指示依赖项只是近似值。 这种近似关系可能意味着存在部分功能依赖关系。customer_state_df.list_dependency_violations('City', 'Region')仔细查看非空
Region值导致冲突的每个情况:customer_state_df[customer_state_df.City=='Downers Grove']结果显示伊利诺伊州和内布拉斯加州的唐纳格罗夫市。 然而,唐纳格罗夫是 伊利诺伊州一个城市,而不是内布拉斯加州。
看看 Fremont 市:
customer_state_df[customer_state_df.City=='Fremont']加利福尼亚有一个名为 Fremont 的城市。 然而,对于得克萨斯州,搜索引擎返回 普雷蒙特,而不是弗里蒙特。
看到
Name和Country/Region之间的依赖关系冲突也是令人怀疑的,它们在最初的依赖关系冲突图中用虚线表示(在删除具有空值的行之前)。customer_state_df.list_dependency_violations('Name', 'Country/Region')一位客户 SDI 设计出现在两个区域-美国和加拿大。 这种情况可能不是语义冲突,只是不常见。 不过,值得仔细看看:
仔细了解客户 SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']进一步检查显示来自不同行业的两个不同的客户具有相同名称。

探索性数据分析和数据清理是迭代的。 你找到的内容取决于你的问题和观点。 语义链接为你提供了从数据获取更多内容的新工具。
相关内容
查看有关语义链接和 SemPy 的其他教程: