你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本快速入门介绍如何使用 Web 工具在 Azure Synapse 中创建无服务器 Apache Spark 池。 然后,你将了解如何连接到 Apache Spark 池,并针对文件和表运行 Spark SQL 查询。 Apache Spark 使用内存中处理实现快速数据分析和群集计算。 有关 Azure Synapse 中的 Spark 的信息,请参阅 概述:Azure Synapse 上的 Apache Spark。
重要
无论是否使用 Spark 实例,Spark 实例的计费都按分钟进行比例计算。 在使用完 Spark 实例后,请务必关闭 Spark 实例,或设置短超时。 有关详细信息,请参阅本文的“ 清理资源 ”部分。
如果没有 Azure 订阅, 请在开始之前创建一个免费帐户。
先决条件
- 需要一个 Azure 订阅。 如果需要, 请创建免费的 Azure 帐户
- Synapse Analytics 工作区
- 无服务器 Apache Spark 池
登录到 Azure 门户
登录到 Azure 门户。
如果没有 Azure 订阅,请在开始之前 创建一个免费的 Azure 帐户 。
创建笔记本
笔记本是支持各种编程语言的交互式环境。 通过笔记本,可以与数据交互、将代码与 markdown、文本合并并执行简单的可视化效果。
从要使用的 Azure Synapse 工作区的 Azure 门户视图中,选择 “启动 Synapse Studio”。
Synapse Studio 启动后,选择“ 开发”。 然后选择“”+图标以添加新资源。
在此处,选择 “笔记本”。 使用自动生成的名称创建并打开一个新笔记本。

在 “属性” 窗口中,提供笔记本的名称。
在工具栏上,单击“ 发布”。
如果工作区中只有一个 Apache Spark 池,则默认处于选中状态。 如果没有选择,请使用下拉列表选择正确的 Apache Spark 池。
单击“ 添加代码”。 默认语言为
Pyspark. 你将使用 Pyspark 和 Spark SQL 的组合,因此默认选择是好的。 其他支持的语言是 Scala 和 .NET for Spark。接下来,创建一个简单的 Spark DataFrame 对象以便进行操作。 在本例中,你将从代码创建它。 有三行和三列:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()现在,使用以下方法之一运行单元格:
按 Shift + Enter。
选择单元格左侧的蓝色播放图标。
选择工具栏上的 “运行所有 ”按钮。
如果 Apache Spark 池实例尚未运行,则会自动启动它。 可以在正在运行的单元格下方以及笔记本底部的状态面板中看到 Apache Spark 池实例状态。 根据池的大小,开始时间应为 2-5 分钟。 代码完成运行后,单元格下方的信息会显示运行和执行所花费的时间。 在输出单元格中,您可以看到结果。
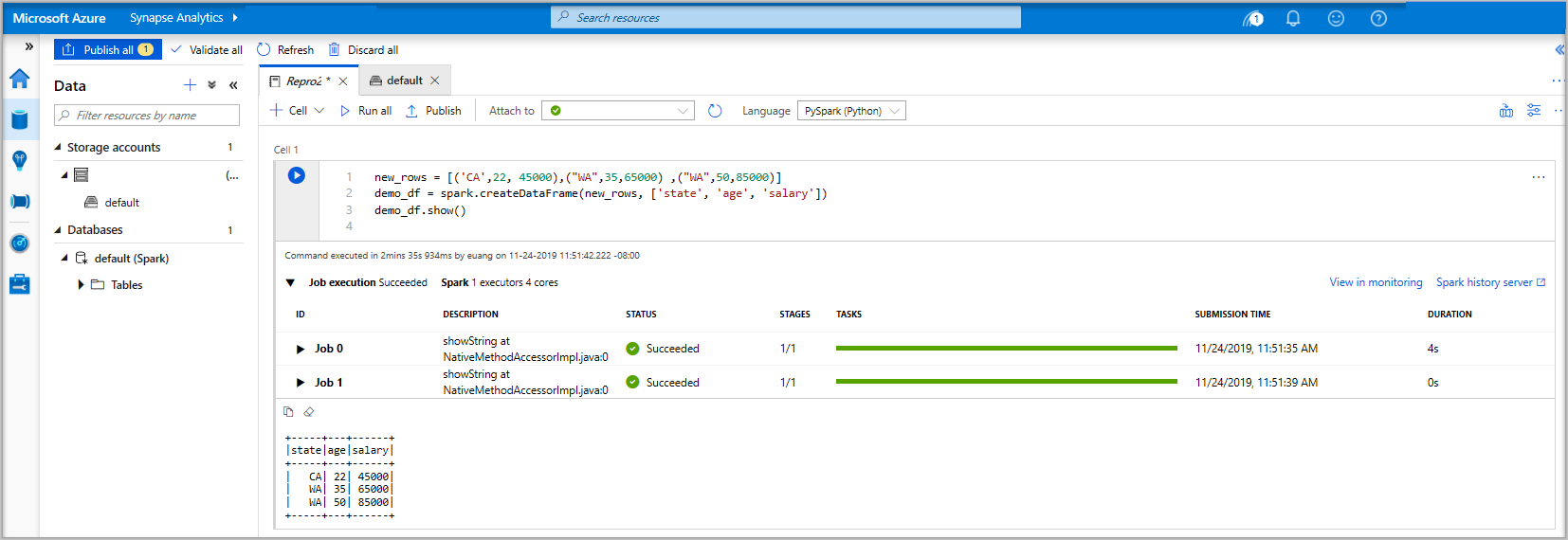
数据现在存在于数据帧中,您可以通过多种不同的方式来使用这些数据。 在本快速入门的余下部分,需要以不同的格式使用这些数据。
在另一个单元格中输入以下代码并运行它,这会创建 Spark 表、CSV 和 Parquet 文件,其中包含数据的副本:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')如果使用存储浏览器,就可以看到上述两种不同文件写入方法的影响。 如果未指定文件系统,则使用默认值,在本例
default>user>trusted-service-user>demo_df中。 数据将保存到指定文件系统的位置。请注意,在“csv”和“parquet”格式中,写入操作时会创建一个目录,其中包含许多分区文件。


运行 Spark SQL 语句
结构化查询语言(SQL)是查询和定义数据的最常用且广泛使用的语言。 Spark SQL 作为 Apache Spark 的扩展,用于处理结构化数据,使用熟悉的 SQL 语法。
将以下代码粘贴到空单元格中,然后运行代码。 该命令列出池中的表。
%%sql SHOW TABLES将 Notebook 与 Azure Synapse Apache Spark 池配合使用时,可以获得一个预设
sqlContext,可用于使用 Spark SQL 运行查询。%%sql告知笔记本使用预设sqlContext来运行查询。 默认情况下,该查询从所有 Azure Synapse Apache Spark 池附带的系统表中检索前 10 行。运行另一个查询以查看
demo_df中的数据。%%sql SELECT * FROM demo_df该代码生成两个输出单元格,一个包含数据结果,另一个显示作业视图。
默认情况下,结果视图显示网格。 但是,网格下方有一个视图切换器,允许视图在网格视图和图形视图之间切换。

在 视图 切换器中,选择 “图表”。
从最右侧选择 “视图选项” 图标。
在 “图表类型 ”字段中,选择“条形图”。
在 X 轴列字段中,选择“state”。
在 Y 轴列字段中,选择“工资”。
在 “聚合 ”字段中,选择“AVG”。
选择应用。

可以获取运行 SQL 的相同体验,但无需切换语言。 为此,可以将上述 SQL 单元格替换为此 PySpark 单元格,输出体验是相同的,因为使用了 显示 命令:
display(spark.sql('SELECT * FROM demo_df'))对于前面执行的每个单元,可以选择转到“History Server”和“监视”。 单击链接将转到用户体验的不同部分。
注释
某些 Apache Spark 官方文档 依赖于使用 Spark 控制台,该控制台在 Synapse Spark 上不可用。 请改用 笔记本 或 IntelliJ 体验。
清理资源
Azure Synapse 将数据保存在 Azure Data Lake Storage 中。 可以安全地让 Spark 实例在不使用时关闭它。 只要无服务器 Apache Spark 池正在运行,即使未使用,也会向你收费。
由于资源池的费用比存储费用高很多,因此在不使用 Spark 实例时,让 Spark 实例关闭是有经济意义的。
若要确保 Spark 实例已关闭,请结束任何连接的会话(笔记本)。 达到 Apache Spark 池中指定的 空闲时间 时,池将关闭。 还可以从笔记本底部的状态栏中选择 结束会话 。
后续步骤
本快速入门介绍了如何创建无服务器 Apache Spark 池并运行基本的 Spark SQL 查询。