你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
重要
仅为方便起见,提供非英语翻译。 有关绑定版本,请参阅本文档的 EN-US 版本。
本文详细介绍了 Azure AI 语音合成如何处理、使用和存储您提供的数据。 作为重要提醒,您需自行负责使用和实施此技术,并需获取所有必要的权限,包括(如适用),从语音及虚拟形象的参与者处(以及如适用,您的个人语音集成用户)获取许可,以处理他们的语音、图像、肖像和/或其他数据,用于开发合成语音和/或虚拟人物。
你还负责获取用于在文字转语音服务中输入内容所必需的任何许可证、许可或其他权利,以生成音频、图像和/或视频输出。 某些司法管辖区可能会对某些类别数据(如生物识别数据)的收集、处理和存储施加特殊的法律要求,并强制向用户披露合成语音、图像和/或视频的使用。 在使用文本转语音处理和存储任何类型的数据之前,以及(如果适用)创建自定义神经语音、个人语音或自定义虚拟形象模型,必须确保符合可能适用于你的所有法律要求。
文本转语音服务处理哪些数据?
预生成的神经语音和预生成的头像处理以下类型的数据:
- 用于语音合成的文本输入。 这是你选择的文本并将其发送到语音服务,以使用一组预生成的神经语音生成音频输出,或生成预生成的虚拟形象,该虚拟形象用于表达从预生成或自定义神经语音生成的音频。
录制的发音人确认声明文件。 客户需要上传由配音演员说出的特定录制声明,其中他们确认您将使用他们的声音来创建合成语音。
注释
准备录制脚本时,请确保包含发音人需要录制的必要确认声明。 可 在此处找到多种语言的语句。 确认语句的语言必须与录音训练数据的语言相同。
训练数据(包括音频文件和相关文本脚本)。 这包括来自配音演员的录音,他们已经同意将其声音用于模型训练以及相关的文本转录。 在自定义神经语音专业项目中,可以提供自己的音频文本听录,或使用语音工作室中提供的自动语音识别听录功能生成音频的文本听录。 录音和文本听录文件都将用作语音模型训练数据。 在自定义神经语音简化版项目中,系统会要求你在Speech Studio中录制朗读Microsoft定义的脚本的语音。 个性化语音功能不需要文本记录。
文本作为测试脚本。 可以通过生成语音合成音频示例来上传自己的基于文本的脚本来评估和测试自定义神经语音模型的质量。 这不适用于个人语音功能。
用于语音合成的文本输入。 这是你选择的文本并将其发送到语音服务,以使用自定义神经语音生成音频输出。
文本转语音服务如何处理数据?
预生成的神经语音
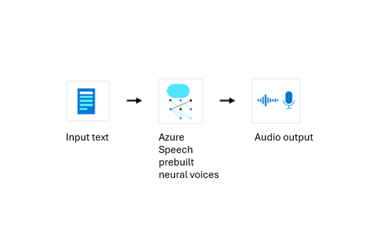
下图演示了如何使用预生成的神经语音对数据进行处理以合成。 输入为文本,输出为音频。 请注意,输入文本和输出音频内容都不会存储在Microsoft日志中。
神经网络自定义语音
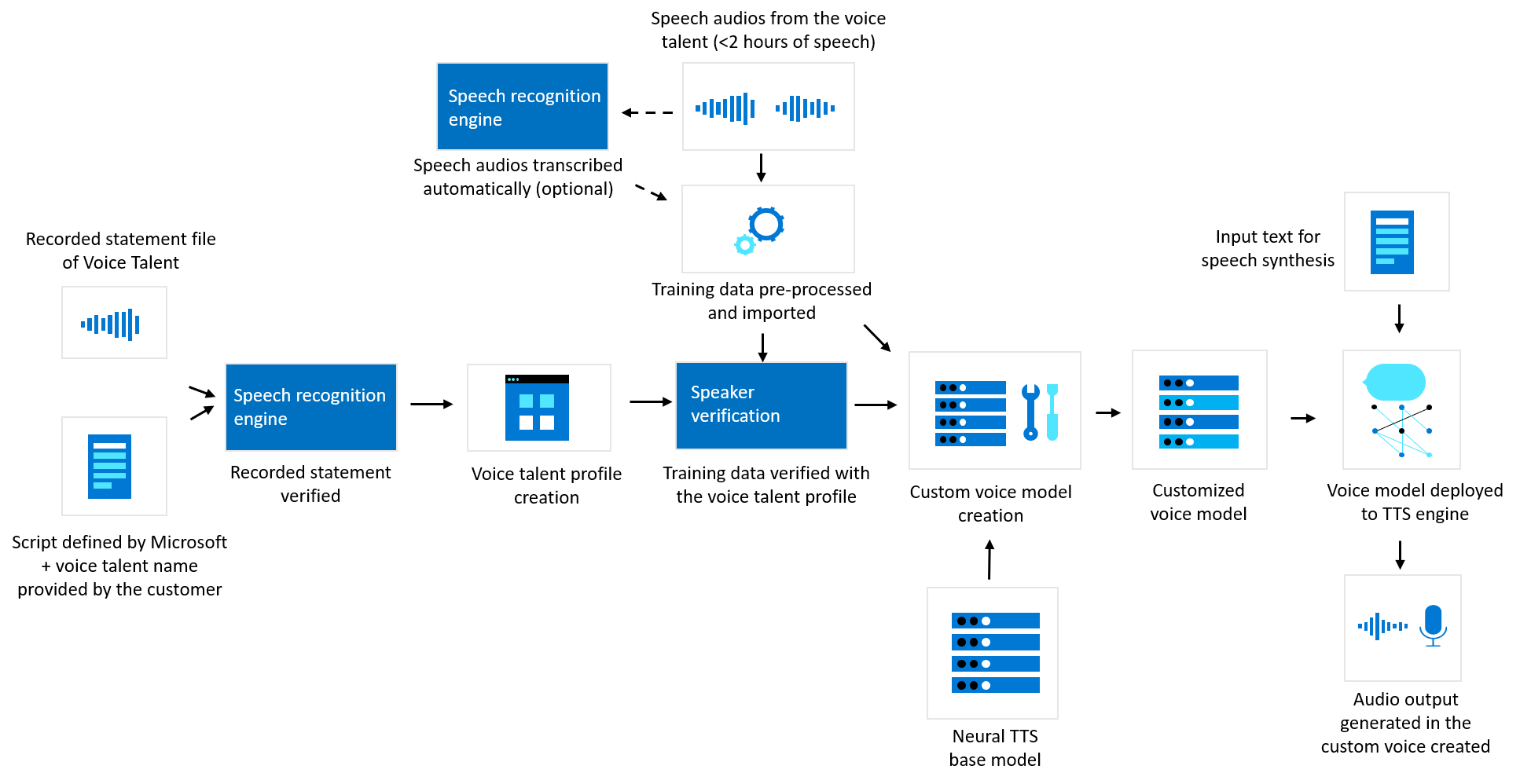
下图演示了如何为自定义神经语音处理数据。 此图涵盖三种不同类型的处理:Microsoft 如何在自定义神经语音模型训练之前验证语音人才录制的确认语句文件、如何Microsoft使用训练数据创建自定义神经语音模型,以及文本转语音如何处理文本输入以生成音频内容。
文本转语音虚拟形象
下图展示了你的数据如何被处理,以便与预构建的文本转语音虚拟形象合成。 虚拟形象内容生成工作流中有三个组件:文本分析器、TTS 音频合成器和 TTS 虚拟形象视频合成器。 若要生成头像视频,文本首先输入到文本分析器中,该分析器以音素序列的形式提供输出。 然后,TTS 音频合成器预测输入文本的声学特征并合成语音。 这两部分由文本转语音模型提供。 接下来,神经文本转语音的虚拟人偶模型会根据声学特征预测唇形同步的图像,从而生成合成视频。
![]()
视频翻译(预览版)
下图演示了如何使用视频翻译处理数据。 客户将视频作为视频翻译的输入上传,提取对话音频,语音转文本会将音频转录为文本内容。 然后,文本内容将翻译为目标语言内容,并使用文本转语音功能将翻译的音频与原始视频内容合并为视频输出。

录制的确认声明验证
Microsoft要求客户将音频文件上传到 Speech Studio,其中包含语音人才的录制声明,确认客户将使用其语音创建合成语音。 Microsoft可以使用 Microsoft的语音转文本和语音识别 技术将此录制的确认语句转录为文本,并验证录制内容是否与Microsoft提供的预定义脚本匹配。 此确认声明和您随音频提供的人才信息用于创建语音资料库。 启动神经网络定制声音训练时,必须将训练数据与相关的发音人资料关联。
Microsoft 还可使用 Azure AI 说话人验证功能处理来自录制的发音人确认声明文件和随机训练数据集音频的生物识别声音签名,以确认确认声明录制内容和训练数据录制内容中的声音签名与合理的置信度匹配。 语音签名也可以称为“语音模板”或“语音打印”,是一个数字矢量,表示从说话人的录音中提取的单个语音特征。 此技术保护措施旨在帮助防止滥用自定义神经语音,例如,阻止客户使用录音训练语音模型,并使用模型欺骗某人的声音,而无需知情或同意。
语音签名由Microsoft仅用于说话人验证,或者出于其他需要调查滥用服务的情况。
Microsoft产品和服务数据保护附录(“DPA”)规定了客户和Microsoft对与 Azure 相关的客户数据和个人数据的处理和安全的义务,并通过参考客户企业协议来纳入 Azure 服务企业协议。 本部分中Microsoft数据处理受数据保护附录的“合法利益业务运营”部分的约束。
训练自定义神经语音模型
客户提交到 Speech Studio 的训练数据(语音音频)是使用自动化工具进行质量检查的预处理,包括数据格式检查、发音评分、噪音检测、脚本映射等。然后将训练数据导入到自定义语音平台的模型训练组件。 在训练过程中,训练数据(语音音频和文本听录)被分解为语音声学和文本的细粒度映射,例如一系列音素。 通过进一步复杂的机器学习建模,该服务生成一个声音模型,然后可用于生成与声音演示者类似的音频,甚至可以根据训练数据的录音以不同语言生成。 语音模型是一种文本转语音计算机模型,可以模拟特定扬声器的独特声乐特征。 它以二进制格式表示一组参数,这些参数不可读且不包含音频录制。
客户的训练数据仅用于开发客户的自定义语音模型,Microsoft 不会使用这些数据来训练或改进任何 Microsoft 的语音合成模型。
语音合成/音频内容生成
创建语音模型后,可以使用它通过文本到语音服务创建音频内容,并采用两种不同的选项。
对于实时语音合成,可以通过 TTS SDK 或 RESTful API 将输入文本发送到语音服务。 文本转语音处理输入文本,并将输出音频内容文件实时返回到发出请求的应用程序。
对于长音频(批量合成)的异步合成,可以通过 长音频 API 将输入文本文件提交到语音批处理服务,以异步创建超过 10 分钟的音频(例如音频书籍或讲座)。 与使用文本转语音 API 执行的合成不同,长音频 API 不会实时返回响应。 音频以异步方式创建,可以在从批处理合成服务获取合成文件时访问和下载合成的音频文件。
还可以使用自定义语音模型通过无代码 音频内容创建工具生成音频内容,并选择在 Azure 存储中使用该工具保存文本输入或输出音频内容。
神经网络定制声音精简版的数据处理(预览版)
自定义神经语音精简版是公共预览版中的项目类型,可用于在 Speech Studio 上录制 20-50 个语音示例,并创建用于演示和评估的轻型自定义神经语音模型。 录制脚本和测试脚本均由Microsoft预定义。 仅当你申请并获得对自定义神经语音的完全访问权限(受适用条款的约束)时,才能更广泛地部署和使用你使用自定义神经语音 lite 创建的合成语音模型。
通过 Speech Studio 提交的合成语音和相关录音将在 90 天内自动删除,除非你获得对自定义神经语音的完全访问权限,并选择部署合成语音,在这种情况下,你将控制其保留期。 如果配音员希望在 90 天前删除合成语音和相关录音,他们可以直接在门户中删除它们,或联系其企业执行此作。
此外,在部署使用自定义神经语音精简项目创建的任何合成语音模型之前,语音人才必须提供一个额外的录音,他们确认合成语音将用于演示和评估以外的其他用途。
个人语音 API 的数据处理(预览版)
个人语音允许客户使用简短的人声样本创建合成语音。 上述口头确认声明文件是应用程序中使用集成的每个用户所必需的。 Microsoft可以使用 Azure AI 说话人验证,从每个用户的录制语音声明文件及其录制的训练样本(即提示)中处理生物识别语音签名,以合理的置信度确认确认声明录音中的语音签名与训练数据录音中的语音签名是否匹配。
训练示例将用于创建语音模型。 然后,可以使用语音模型通过 API 使用提供给服务的文本输入生成语音,无需进行额外的部署。
数据存储和保留
所有文本转语音服务
语音合成的文本输入: Microsoft不会保留或存储您通过实时语音合成API提供的文本。 通过用于文本转语音的 长音频 API 或文本到语音头像批处理 API 提供的脚本存储在 Azure 存储中,以处理批处理合成请求。 可以随时通过 删除 API 删除输入文本。
输出音频和视频内容: Microsoft不存储使用实时合成 API 生成的音频或视频内容。 如果使用视频翻译或 长音频 API 进行文本转语音头像批处理 API,输出音频或视频内容将存储在 Azure 存储中。 这些音频或视频可以通过删除操作随时删除。
录制的确认声明和说话人验证数据:语音签名由Microsoft仅用于说话人验证,或者出于其他原因调查滥用服务所必需的。 将仅在执行说话人验证所需的时间内保留声音签名,这种验证可能不时发生。 Microsoft 可能会要求您进行此验证,然后才允许您在 Speech Studio 中创建或重新创建自定义神经语音模型,或在必要时采取其他措施。 Microsoft将保留录制的确认声明语音文件和配音人员的配置文件数据,以维持Azure AI语音的安全性和完整性。
自定义神经语音模型:虽然您保留对自定义神经语音模型的独占使用权限,但Microsoft可以在必要的情况下独立保留这些模型的副本。 Microsoft可以使用自定义神经语音模型来保护 Microsoft Azure AI 服务的安全性和完整性。
Microsoft将保护并存储每个语音人才录制的确认语句和自定义神经语音模型的副本,该模型具有与其他 Azure 服务相同的高级安全性。 在 Microsoft 信任中心了解详细信息。
训练数据: 提交语音人才的语音训练数据,以便通过 Speech Studio 生成语音模型,该模型将默认保留在 Azure 存储中,并将其存储在 Azure 存储中(有关详细信息,请参阅 REST 数据的 Azure 存储加密 )。 可以通过 Speech Studio 访问和删除用于生成语音模型的任何训练数据。
可以通过 BYOS 管理训练数据的 存储(自带存储)。 使用此存储方法,只能出于语音模型训练的目的访问训练数据,否则将通过 BYOS 存储。
注释
个人语音不支持 BYOS。 数据将存储在由 Microsoft 管理的 Azure 存储中。 你可以访问和删除用于通过 API 生成语音模型的任何训练数据(提示音频)。 Microsoft可以根据需要独立保留个人语音模型的副本。 Microsoft可以使用个人语音模型来保护 Microsoft Azure AI 服务的安全性和完整性。