Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (aktuell)
Med Batch-slutpunkter kan du distribuera modeller som kör slutsatsdragning över stora mängder data. Dessa slutpunkter förenklar värdmodeller för batchbedömning, så att du kan fokusera på maskininlärning i stället för infrastruktur.
Använd batchslutpunkter för att distribuera modeller när:
- Du använder dyra modeller som tar längre tid att köra slutsatsdragning.
- Du kan dra slutsatser om stora mängder data som distribueras i flera filer.
- Du behöver inte korta svarstider.
- Du kan dra nytta av parallellisering.
Den här artikeln visar hur du använder en batchslutpunkt för att distribuera en maskininlärningsmodell som löser det klassiska MNIST-igenkänningsproblemet (Modified National Institute of Standards and Technology). Den distribuerade modellen utför batchinferens över stora mängder data, till exempel bildfiler. Processen börjar med att skapa en batchdistribution av en modell som skapats med Torch. Den här distributionen blir standard i endpoint. Skapa senare en andra distribution av en modell som skapats med TensorFlow (Keras), testa den andra distributionen och ange den som slutpunktens standarddistribution.
Förutsättningar
Innan du följer stegen i den här artikeln kontrollerar du att du har följande förutsättningar:
En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning.
En Azure Machine Learning-arbetsyta. Om du inte har någon använder du stegen i artikeln Så här hanterar du arbetsytor för att skapa en.
Om du vill utföra följande uppgifter kontrollerar du att du har dessa behörigheter på arbetsytan:
Så här skapar/hanterar du batchslutpunkter och distributioner: Använd ägarrollen, deltagarrollen eller en anpassad roll som tillåter
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Så här skapar du ARM-distributioner i arbetsytans resursgrupp: Använd ägarrollen, deltagarrollen eller en anpassad roll som tillåts
Microsoft.Resources/deployments/writei resursgruppen där arbetsytan distribueras.
Du måste installera följande programvara för att arbeta med Azure Machine Learning:
GÄLLER FÖR:
Azure CLI ml-tillägget v2 (aktuellt)Azure CLI och
mltillägget för Azure Machine Learning.az extension add -n ml
Klona exempellagringsplatsen
Exemplet i den här artikeln baseras på kodexempel som finns på lagringsplatsen azureml-examples . Om du vill köra kommandona lokalt utan att behöva kopiera/klistra in YAML och andra filer klonar du först lagringsplatsen och ändrar sedan kataloger till mappen:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Förbereda systemet
Anslut till din arbetsyta
Anslut först till Azure Machine Learning-arbetsytan där du arbetar.
Om du inte redan har angett standardinställningarna för Azure CLI sparar du standardinställningarna. Kör den här koden för att undvika att ange värdena för din prenumeration, arbetsyta, resursgrupp och plats flera gånger:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Skapa beräkning
Batchslutpunkter körs på beräkningskluster och stöder både Azure Machine Learning-beräkningskluster (AmlCompute) och Kubernetes-kluster. Kluster är en delad resurs, därför kan ett kluster vara värd för en eller flera batchdistributioner (tillsammans med andra arbetsbelastningar, om så önskas).
Skapa en beräkning med namnet batch-cluster, enligt följande kod. Justera efter behov och referera till din beräkning med hjälp av azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Kommentar
Du debiteras inte för beräkningen just nu eftersom klustret ligger kvar på 0 noder tills en batchslutpunkt anropas och ett batchbedömningsjobb skickas. Mer information om beräkningskostnader finns i Hantera och optimera kostnaden för AmlCompute.
Skapa en batchslutpunkt
En batchslutpunkt är en HTTPS-slutpunkt som klienter anropar för att utlösa ett batchbedömningsjobb. Ett batchbedömningsjobb bearbetar flera indata. En batchdistribution är en uppsättning beräkningsresurser som är värdar för modellen som utför batchbedömning (eller batchinferens). En batchslutpunkt kan ha flera batchdistributioner. Mer information om batchslutpunkter finns i Vad är batchslutpunkter?.
Dricks
En av batchdistributionerna fungerar som standarddistribution för slutpunkten. När slutpunkten anropas utför standarddistributionen batchbedömning. Mer information om batchslutpunkter och distributioner finns i batchslutpunkter och batchdistribution.
Namnge slutpunkten. Slutpunktens namn måste vara unikt i en Azure-region eftersom namnet ingår i slutpunktens URI. Det kan till exempel bara finnas en batchslutpunkt med namnet
mybatchendpointiwestus2.Konfigurera batchslutpunkten
Följande YAML-fil definierar en batchslutpunkt. Använd den här filen med CLI-kommandot för att skapa batchslutpunkter.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningI följande tabell beskrivs nyckelegenskaperna för slutpunkten. Det fullständiga YAML-schemat för batchslutpunkten finns i CLI(v2) YAML-schema för batchslutpunkt.
Nyckel beskrivning nameNamnet på batchslutpunkten. Måste vara unikt på Azure-regionnivå. descriptionBeskrivningen av batchslutpunkten. Den här egenskapen är valfri. tagsTaggarna som ska inkluderas i slutpunkten. Den här egenskapen är valfri. Skapa slutpunkten:
Skapa en batchdistribution
En modelldistribution är en uppsättning resurser som krävs för att vara värd för den modell som utför den faktiska inferensen. Om du vill skapa en distribution av en batchmodell behöver du följande:
- En registrerad modell på arbetsytan
- Koden för att poängsätta modellen
- En miljö med modellens beroenden installerade
- De förskapade inställningarna för beräkning och resurser
Börja med att registrera den modell som ska distribueras – en Torch-modell för det populära problemet med sifferigenkänning (MNIST). Batch-distributioner kan bara distribuera modeller som är registrerade på arbetsytan. Du kan hoppa över det här steget om den modell som du vill distribuera redan är registrerad.
Dricks
Modeller är associerade med distributionen i stället för med slutpunkten. Det innebär att en enskild slutpunkt kan hantera olika modeller (eller modellversioner) under samma slutpunkt så länge de olika modellerna (eller modellversionerna) distribueras i olika distributioner.
Nu är det dags att skapa ett bedömningsskript. Batchdistributioner kräver ett bedömningsskript som anger hur en viss modell ska köras och hur indata måste bearbetas. Batch-slutpunkter stöder skript som skapats i Python. I det här fallet distribuerar du en modell som läser bildfiler som representerar siffror och matar ut motsvarande siffra. Bedömningsskriptet är följande:
Kommentar
För MLflow-modeller genererar Azure Machine Learning automatiskt bedömningsskriptet, så du behöver inte ange något. Om din modell är en MLflow-modell kan du hoppa över det här steget. Mer information om hur batchslutpunkter fungerar med MLflow-modeller finns i artikeln Använda MLflow-modeller i batchdistributioner.
Varning
Om du distribuerar en AutoML-modell (Automatiserad maskininlärning) under en batchslutpunkt bör du tänka på att bedömningsskriptet som AutoML endast tillhandahåller fungerar för onlineslutpunkter och inte är utformat för batchkörning. Information om hur du skapar ett bedömningsskript för batchdistributionen finns i Skapa bedömningsskript för batchdistributioner.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Skapa en miljö där batchdistributionen körs. Miljön bör innehålla paketen
azureml-coreochazureml-dataset-runtime[fuse], som krävs av batchslutpunkter, plus eventuella beroenden som koden kräver för att köras. I det här fallet har beroendena avbildats i enconda.yamlfil:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Viktigt!
Paketen
azureml-coreochazureml-dataset-runtime[fuse]krävs av batchdistributioner och bör ingå i miljöberoendena.Ange miljön enligt följande:
Gå till fliken Miljöer på sidomenyn.
Välj Skapa anpassade miljöer>.
Ange namnet på miljön, i det här fallet
torch-batch-env.För Välj miljökälla väljer du Använd befintlig docker-avbildning med valfri conda-fil.
För sökvägen containerregisteravbildning anger du
mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04.Välj Nästa för att gå till avsnittet "Anpassa".
Kopiera innehållet i filen deployment-torch/environment/conda.yaml från GitHub-lagringsplatsen till portalen.
Välj Nästa tills du når sidan Granska.
Välj Skapa och vänta tills miljön är klar.
Varning
Utvalda miljöer stöds inte i batchdistributioner. Du måste ange din egen miljö. Du kan alltid använda basavbildningen av en kurerad miljö som din för att förenkla processen.
Skapa en distributionsdefinition
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoI följande tabell beskrivs de viktigaste egenskaperna för batchdistributionen. Det fullständiga YAML-schemat för batchdistribution finns i YAML-schema för CLI-batchdistribution (v2).
Nyckel beskrivning nameNamnet på distributionen. endpoint_nameNamnet på slutpunkten som distributionen ska skapas under. modelDen modell som ska användas för batchbedömning. Exemplet definierar en infogad modell med hjälp av path. Den här definitionen tillåter att modellfiler laddas upp och registreras automatiskt med ett automatiskt genererat namn och en version. Se modellschemat för fler alternativ. Som bästa praxis för produktionsscenarier bör du skapa modellen separat och referera till den här. Om du vill referera till en befintlig modell använder du syntaxenazureml:<model-name>:<model-version>.code_configuration.codeDen lokala katalogen som innehåller all Python-källkod för att poängsätta modellen. code_configuration.scoring_scriptPython-filen i code_configuration.codekatalogen. Den här filen måste ha eninit()funktion och enrun()funktion.init()Använd funktionen för alla kostsamma eller vanliga förberedelser (till exempel för att läsa in modellen i minnet).init()anropas bara en gång i början av processen. Användrun(mini_batch)för att poängsätta varje post. Värdetmini_batchför är en lista med filsökvägar. Funktionenrun()ska returnera en Pandas DataFrame eller en matris. Varje returnerat element anger en lyckad körning av indataelementetmini_batchi . Mer information om hur du skapar ett bedömningsskript finns i Förstå bedömningsskriptet.environmentMiljön för att poängsätta modellen. I exemplet definieras en infogad miljö med hjälp av conda_fileochimage. Beroendenaconda_fileinstalleras ovanpåimage. Miljön registreras automatiskt med ett automatiskt genererat namn och en version. Se miljöschemat för fler alternativ. Som bästa praxis för produktionsscenarier bör du skapa miljön separat och referera till den här. Om du vill referera till en befintlig miljö använder du syntaxenazureml:<environment-name>:<environment-version>.computeDen beräkning som ska köra batchbedömning. Exemplet använder den batch-clustersom skapades i början och refererar till den med hjälp av syntaxenazureml:<compute-name>.resources.instance_countAntalet instanser som ska användas för varje batchbedömningsjobb. settings.max_concurrency_per_instanceDet maximala antalet parallella scoring_scriptkörningar per instans.settings.mini_batch_sizeAntalet filer som kan bearbetas scoring_scripti ettrun()anrop.settings.output_actionHur utdata ska ordnas i utdatafilen. append_rowsammanfogar allarun()returnerade utdataresultat till en enda fil med namnetoutput_file_name.summary_onlysammanfogar inte utdataresultaten och beräknarerror_thresholdbara .settings.output_file_nameNamnet på batchbedömningsutdatafilen för append_rowoutput_action.settings.retry_settings.max_retriesAntalet maximala försök för en misslyckad scoring_scriptrun().settings.retry_settings.timeoutTidsgränsen i sekunder för en scoring_scriptrun()för bedömning av en minibatch.settings.error_thresholdAntalet fel i indatafilens bedömning som ska ignoreras. Om felantalet för hela indata överskrider det här värdet avslutas batchbedömningsjobbet. I exemplet används -1, vilket anger att valfritt antal fel tillåts utan att batchbedömningsjobbet avslutas.settings.logging_levelLoggdetaljeringsgrad. Värden i ökande verbositet är: WARNING, INFO och DEBUG. settings.environment_variablesOrdlista över miljövariabelns namn/värde-par som ska anges för varje batchbedömningsjobb. Gå till fliken Slutpunkter på sidomenyn.
Välj fliken Batch-slutpunkter>Skapa.
Ge slutpunkten ett namn, i det här fallet
mnist-batch. Du kan konfigurera resten av fälten eller lämna dem tomma.Välj Nästa för att gå till avsnittet "Modell".
Välj modellen mnist-classifier-torch.
Välj Nästa för att gå till sidan "Distribution".
Ge distributionen ett namn.
Kontrollera att Lägg till rad är vald för åtgärden Utdata.
För Namn på utdatafil kontrollerar du att utdatafilen för batchbedömning är den du behöver. Standard är
predictions.csv.För minibatchstorlek justerar du storleken på de filer som ska ingå i varje mini-batch. Den här storleken styr mängden data som ditt bedömningsskript tar emot per batch.
Se till att du ger tillräckligt med tid för distributionen för att poängsätta en viss uppsättning filer för bedömning av tidsgränsen (sekunder). Om du ökar antalet filer måste du vanligtvis också öka tidsgränsvärdet. Dyrare modeller (som de som baseras på djupinlärning) kan kräva höga värden i det här fältet.
För Maximal samtidighet per instans konfigurerar du det antal utförare som du vill ha för varje beräkningsinstans som du får i distributionen. Ett högre tal här garanterar en högre grad av parallellisering, men det ökar också minnesbelastningen på beräkningsinstansen. Justera det här värdet helt och hållet med mini batchstorlek.
När du är klar väljer du Nästa för att gå till sidan Kod + miljö.
För "Välj ett bedömningsskript för slutsatsdragning" bläddrar du för att hitta och väljer bedömningsskriptfilen deployment-torch/code/batch_driver.py.
I avsnittet "Välj miljö" väljer du den miljö som du skapade tidigare torch-batch-env.
Välj Nästa för att gå till sidan "Beräkning".
Välj det beräkningskluster som du skapade i ett tidigare steg.
Varning
Azure Kubernetes-kluster stöds i batchdistributioner, men endast när de skapas med Hjälp av Azure Machine Learning CLI eller Python SDK.
För Antal instanser anger du det antal beräkningsinstanser som du vill använda för distributionen. I det här fallet använder du 2.
Välj Nästa.
Skapa distributionen:
Kör följande kod för att skapa en batchdistribution under batchslutpunkten och ange den som standarddistribution.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultDricks
Parametern
--set-defaultanger den nyligen skapade distributionen som standarddistribution av slutpunkten. Det är ett praktiskt sätt att skapa en ny standarddistribution av slutpunkten, särskilt när du skapar den första distributionen. Som bästa praxis för produktionsscenarier kanske du vill skapa en ny distribution utan att ange den som standard. Kontrollera att distributionen fungerar som förväntat och uppdatera sedan standarddistributionen senare. Mer information om hur du implementerar den här processen finns i avsnittet Distribuera en ny modell .Kontrollera information om batchslutpunkt och distribution.
Välj fliken Batch-slutpunkter .
Välj den batchslutpunkt som du vill visa.
Sidan Information för slutpunkten visar information om slutpunkten tillsammans med alla distributioner som är tillgängliga i slutpunkten.


Köra batchslutpunkter och få åtkomst till resultat
Förstå dataflödet
Innan du kör batchslutpunkten ska du förstå hur data flödar genom systemet:
Indata: Data som ska bearbetas (poäng). Detta omfattar:
- Filer som lagras i Azure Storage (bloblagring, datasjö)
- Mappar med flera filer
- Registrerade datauppsättningar i Azure Machine Learning
Bearbetning: Den distribuerade modellen bearbetar indata i batchar (mini-batchar) och genererar förutsägelser.
Utdata: Resultat från modellen som lagras som filer i Azure Storage. Som standard sparas utdata till arbetsytans standardbloblagring, men du kan ange en annan plats.
Anropa en batchslutpunkt
Om du anropar en batchslutpunkt utlöses ett batchbedömningsjobb. Jobbet name returneras i anropssvaret och övervakar batchpoängberäkningsprocessen. Ange sökvägen för indata så att slutpunkterna kan hitta de data som ska poängsättas. I följande exempel visas hur du startar ett nytt jobb över exempeldata för MNIST-datauppsättningen som lagras i ett Azure Storage-konto.
Du kan köra och anropa en batchslutpunkt med hjälp av Azure CLI, Azure Machine Learning SDK eller REST-slutpunkter. Mer information om de här alternativen finns i Skapa jobb och indata för batchslutpunkter.
Kommentar
Hur fungerar parallellisering?
Batchdistributioner distribuerar arbete på filnivå. Till exempel genererar en mapp med 100 filer och minibatch med 10 filer 10 batchar med 10 filer vardera. Detta sker oavsett filstorlek. Om filerna är för stora för bearbetning i mini-batchar delar du upp dem i mindre filer för att öka parallelliteten eller minska antalet filer per mini-batch. Batchdistributioner tar för närvarande inte hänsyn till skevhet i filstorleksfördelningen.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Batch-slutpunkter stöder läsning av filer eller mappar som finns på olika platser. Mer information om vilka typer som stöds och hur du anger dem finns i Komma åt data från batchslutpunktsjobb.
Övervaka körningsframsteg för batchjobb
Batchbedömningsjobb tar tid att bearbeta alla indata.
Följande kod kontrollerar jobbstatusen och matar ut en länk till Azure Machine Learning-studio för ytterligare information.
az ml job show -n $JOB_NAME --web

Kontrollera resultat för batchbedömning
Jobbutdata lagras i molnlagring, antingen i arbetsytans standardbloblagring eller i den lagring du angav. Information om hur du ändrar standardvärdena finns i Konfigurera utdataplatsen. Med följande steg kan du visa bedömningsresultaten i Azure Storage Explorer när jobbet har slutförts:
Kör följande kod för att öppna batchbedömningsjobbet i Azure Machine Learning-studio. Jobbstudiolänken ingår också i svaret för
invoke, som värdet förinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webVälj
batchscoringsteget i diagrammet för jobbet.Välj fliken Utdata + loggar och välj sedan Visa datautdata.
Från Datautdata väljer du ikonen för att öppna Storage Explorer.

Bedömningsresultaten i Storage Explorer liknar följande exempelsida:



Konfigurera utdataplatsen
Som standardinställning lagras batchpoängresultat i arbetsytans standardbloblager i en mapp med namn efter arbetet (en systemgenererad GUID). Konfigurera utdataplatsen när batchslutpunkten anropas.
Använd output-path för att konfigurera valfri mapp i ett Azure Machine Learning-registrerat datalager. Syntaxen --output-path för är densamma som --input när du anger en mapp, dvs azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. . Använd --set output_file_name=<your-file-name> för att konfigurera ett nytt namn på utdatafilen.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)


Varning
Du måste använda en unik utdataplats. Om utdatafilen finns misslyckas batchbedömningsjobbet.
Viktigt!
Till skillnad från indata kan utdata endast lagras i Azure Machine Learning-datalager som körs på bloblagringskonton.
Skriva över distributionskonfigurationen för varje jobb
När du anropar en batchslutpunkt kan du skriva över vissa inställningar för att använda beräkningsresurser på bästa sätt och förbättra prestandan. Den här funktionen är användbar när du behöver olika inställningar för olika jobb utan att permanent ändra distributionen.
Vilka inställningar kan åsidosättas?
Du kan konfigurera följande inställningar per jobb:
| Inställning | När man ska använda | Exempelscenario |
|---|---|---|
| Antal instanser | När du har olika datavolymer | Använd fler instanser för större datamängder (10 instanser för 1 miljon filer jämfört med 2 instanser för 100 000 filer). |
| Mini-batchstorlek | När du behöver balansera dataflöde och minnesanvändning | Använd mindre batchar (10–50 filer) för stora bilder och större batchar (100–500 filer) för små textfiler. |
| Maximalt antal återförsök | När datakvaliteten varierar | Högre återförsök (5–10) för brusdata. lägre återförsök (1–3) för rena data |
| Tidsgräns | När bearbetningstiden varierar beroende på datatyp | Längre tidsgräns (300-talet) för komplexa modeller. kortare timeout (30-talet) för enkla modeller |
| Tröskelvärde för fel | När du behöver olika feltoleransnivåer | Strikt tröskelvärde (-1) för kritiska jobb; överseende tröskelvärde (10%) för experimentella jobb |
Så här åsidosätter du inställningar
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Lägga till distributioner till en slutpunkt
När du har en batchslutpunkt med en distribution kan du fortsätta att förfina din modell och lägga till nya distributioner. Batch-slutpunkter fortsätter att hantera standarddistributionen medan du utvecklar och distribuerar nya modeller under samma slutpunkt. Distributioner påverkar inte varandra.
I det här exemplet lägger du till en andra distribution som använder en modell som skapats med Keras och TensorFlow för att lösa samma MNIST-problem.
Lägga till en andra distribution
Skapa en miljö för batchdistributionen. Inkludera eventuella beroenden som koden behöver köra. Lägg till biblioteket
azureml-core, eftersom det krävs för batchdistributioner. Följande miljödefinition innehåller de bibliotek som krävs för att köra en modell med TensorFlow.Kopiera innehållet i filen deployment-keras/environment/conda.yaml från GitHub-lagringsplatsen till portalen.
Välj Nästa tills du kommer till sidan Granska.
Välj Skapa och vänta tills miljön är klar att användas.
Conda-filen som används ser ut så här:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Skapa ett bedömningsskript för modellen:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Skapa en distributionsdefinition
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvVälj Nästa för att fortsätta till sidan "Kod + miljö".
För Välj ett bedömningsskript för slutsatsdragning bläddrar du till att välja bedömningsskriptfilen deployment-keras/code/batch_driver.py.
För Välj miljö väljer du den miljö som du skapade i ett tidigare steg.
Välj Nästa.
På sidan Beräkning väljer du det beräkningskluster som du skapade i ett tidigare steg.
För Antal instanser anger du det antal beräkningsinstanser som du vill använda för distributionen. I det här fallet använder du 2.
Välj Nästa.
Skapa distributionen:
Kör följande kod för att skapa en batchdistribution under batchslutpunkten och ange den som standarddistribution.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMEDricks
Parametern
--set-defaultsaknas i det här fallet. Som bästa praxis för produktionsscenarier skapar du en ny distribution utan att ange den som standard. Kontrollera det sedan och uppdatera standarddistributionen senare.
Testa en batchdistribution som inte är standard
Om du vill testa den nya icke-standarddistributionen måste du känna till namnet på den distribution som du vill köra.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Observera --deployment-name används för att ange vilken distribution som ska köras. Med den här parametern kan du utföra invoke en icke-standarddistribution utan att uppdatera standarddistributionen av batchslutpunkten.
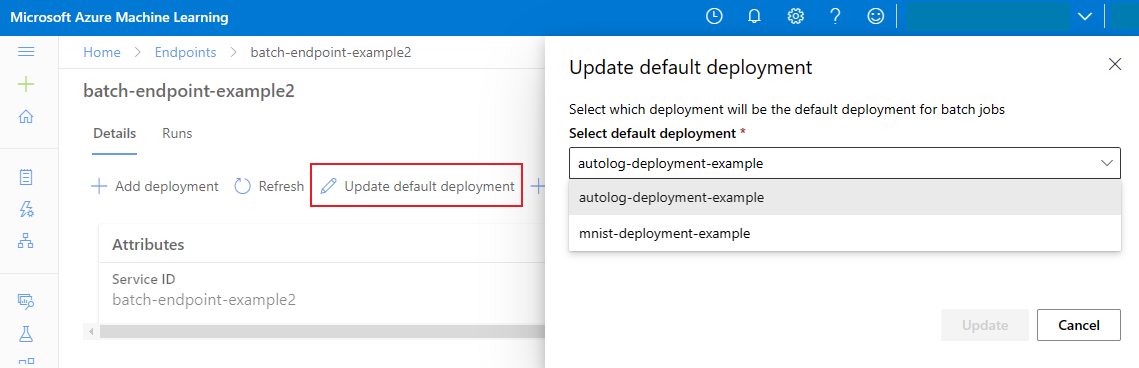
Uppdatera standarddistributionen av batchar
Även om du kan anropa en specifik distribution i en slutpunkt vill du vanligtvis anropa själva slutpunkten och låta slutpunkten bestämma vilken distribution som ska användas – standarddistributionen. Du kan ändra standarddistributionen (och därmed ändra modellen som betjänar distributionen) utan att ändra ditt kontrakt med användaren som anropar slutpunkten. Använd följande kod för att uppdatera standarddistributionen:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Ta bort batchslutpunkten och distributionen
Om du inte behöver den gamla batchdistributionen tar du bort den genom att köra följande kod. Flaggan --yes bekräftar borttagningen.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Kör följande kod för att ta bort batchslutpunkten och dess underliggande distributioner. Batchbedömningsjobb tas inte bort.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes