Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Vi rekommenderar att du felsöker Apache Spark-program via en fjärranslutning via SSH. Anvisningar finns i Fjärrfelsöka Apache Spark-program i ett HDInsight-kluster med Azure Toolkit for IntelliJ via SSH.
Den här artikeln innehåller stegvisa anvisningar om hur du använder HDInsight Tools i Azure Toolkit for IntelliJ för att skicka ett Spark-jobb på ett HDInsight Spark-kluster och sedan felsöka det via fjärranslutning från din stationära dator. För att slutföra dessa uppgifter måste du utföra följande steg på hög nivå:
- Skapa ett virtuellt Azure-nätverk för plats-till-plats eller punkt-till-plats. Stegen i det här dokumentet förutsätter att du använder ett plats-till-plats-nätverk.
- Skapa ett Spark-kluster i HDInsight som ingår i det virtuella nätverket plats-till-plats.
- Kontrollera anslutningen mellan klusterhuvudnoden och skrivbordet.
- Skapa ett Scala-program i IntelliJ IDEA och konfigurera det sedan för fjärrfelsökning.
- Kör och felsök programmet.
Förutsättningar
- Prenumeration för Azure.
- Ett Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight.
- Oracle Java Development Kit. Du kan installera den från Oracles webbplats.
- IntelliJ IDEA. Den här artikeln använder version 2017.1. Du kan installera den från JetBrains webbplats.
- HDInsight-verktyg i Azure Toolkit for IntelliJ. HDInsight-verktyg för IntelliJ är tillgängliga som en del av Azure Toolkit for IntelliJ. Anvisningar om hur du installerar Azure Toolkit finns i Installera Azure Toolkit for IntelliJ.
- Logga in på din Azure-prenumeration från IntelliJ IDEA. Följ anvisningarna i Använda Azure Toolkit for IntelliJ för att skapa Apache Spark-program för ett HDInsight-kluster.
- Undantagslösning. När du kör Spark Scala-programmet för fjärrfelsökning på en Windows-dator kan du få ett undantag. Det här undantaget förklaras i SPARK-2356 och inträffar på grund av att en WinUtils.exe fil saknas i Windows. Om du vill undvika det här felet måste du ladda ned Winutils.exe till en plats som C:\WinUtils\bin. Lägg till en HADOOP_HOME miljövariabel och ange sedan värdet för variabeln till C\WinUtils.
Steg 1: Skapa ett virtuellt Azure-nätverk
Följ anvisningarna från följande länkar för att skapa ett virtuellt Azure-nätverk och kontrollera sedan anslutningen mellan din stationära dator och det virtuella nätverket:
- Skapa ett virtuellt nätverk med en plats-till-plats-VPN-anslutning med hjälp av Azure-portalen
- Skapa ett virtuellt nätverk med en plats-till-plats-VPN-anslutning med PowerShell
- Konfigurera en punkt-till-plats-anslutning till ett virtuellt nätverk med hjälp av PowerShell
Steg 2: Skapa ett HDInsight Spark-kluster
Vi rekommenderar att du även skapar ett Apache Spark-kluster i Azure HDInsight som är en del av det virtuella Azure-nätverk som du skapade. Använd informationen som är tillgänglig i Skapa Linux-baserade kluster i HDInsight. Som en del av den valfria konfigurationen väljer du det virtuella Azure-nätverk som du skapade i föregående steg.
Steg 3: Kontrollera anslutningen mellan klusterhuvudnoden och skrivbordet
Hämta IP-adressen för huvudnoden. Öppna Ambari-användargränssnittet för klustret. Välj Instrumentpanel på klusterbladet.

I Ambari-användargränssnittet väljer du Värdar.

Du ser en lista över huvudnoder, arbetsnoder och zookeeper-noder. Huvudnoderna har ett hn*-prefix. Välj den första huvudnoden.

I fönstret Sammanfattning längst ned på sidan som öppnas kopierar du IP-adressen för huvudnoden och värdnamnet.

Lägg till IP-adressen och värdnamnet för huvudnoden i värdfilen på den dator där du vill köra och fjärrsöka Spark-jobbet. På så sätt kan du kommunicera med huvudnoden med hjälp av IP-adressen och värdnamnet.
a. Öppna en Anteckningar-fil med utökade behörigheter. På menyn Arkiv väljer du Öppna och letar sedan reda på platsen för värdfilen. På en Windows-dator är platsen C:\Windows\System32\Drivers\etc\hosts.
b) Lägg till följande information i värdfilen :
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netFrån den dator som du har anslutit till det virtuella Azure-nätverket som används av HDInsight-klustret kontrollerar du att du kan pinga huvudnoderna med hjälp av IP-adressen samt värdnamnet.
Använd SSH för att ansluta till klusterhuvudnoden genom att följa anvisningarna i Anslut till ett HDInsight-kluster med hjälp av SSH. Från klusterhuvudnoden pingar du IP-adressen för den stationära datorn. Testa anslutningen till båda IP-adresserna som tilldelats datorn:
- En för nätverksanslutningen
- En för det virtuella Azure-nätverket
Upprepa stegen för den andra huvudnoden.
Steg 4: Skapa ett Apache Spark Scala-program med hdinsight-verktyg i Azure Toolkit for IntelliJ och konfigurera det för fjärrfelsökning
Öppna IntelliJ IDEA och skapa ett nytt projekt. Gör följande i dialogrutan Nytt projekt:

a. Välj HDInsight>Spark på HDInsight (Scala).
b) Välj Nästa.
I nästa dialogrutan Nytt projekt gör du följande och väljer sedan Slutför:
Ange ett projektnamn och en plats.
I listrutan Project SDK väljer du Java 1.8 för Spark 2.x-klustret eller väljer Java 1.7 för Spark 1.x-klustret.
I listrutan Spark-version integrerar guiden Skapa Scala-projekt rätt version för Spark SDK och Scala SDK. Om Sparks klusterversion är äldre än 2.0 väljer du Spark 1.x. Annars väljer du Spark2.x. I det här exemplet används Spark 2.0.2 (Scala 2.11.8).

Spark-projektet skapar automatiskt en artefakt åt dig. Om du vill visa artefakten gör du följande:
a. På menyn Arkiv väljer du Projektstruktur.
b) I dialogrutan Projektstruktur väljer du Artefakter för att visa standardartefakten som skapas. Du kan också skapa en egen artefakt genom att välja plustecknet (+).

Lägg till bibliotek i projektet. Gör följande för att lägga till ett bibliotek:
a. Högerklicka på projektnamnet i projektträdet och välj sedan Öppna modulinställningar.
b) I dialogrutan Projektstruktur väljer du Bibliotek, väljer symbolen (+) och sedan Från Maven.

Punkt c I dialogrutan Ladda ned bibliotek från Maven-lagringsplatsen söker du efter och lägger till följande bibliotek:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Kopiera
yarn-site.xmlochcore-site.xmlfrån klusterhuvudnoden och lägg till dem i projektet. Använd följande kommandon för att kopiera filerna. Du kan använda Cygwin för att köra följandescpkommandon för att kopiera filerna från klusterhuvudnoderna:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Eftersom vi redan har lagt till klusterhuvudnodens IP-adress och värdnamn för värdfilen på skrivbordet kan vi använda
scpkommandona på följande sätt:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Om du vill lägga till dessa filer i projektet kopierar du dem under mappen /src i projektträdet, till exempel
<your project directory>\src.core-site.xmlUppdatera filen för att göra följande ändringar:a. Ersätt den krypterade nyckeln. Filen
core-site.xmlinnehåller den krypterade nyckeln till lagringskontot som är associerat med klustret. I filencore-site.xmlsom du lade till i projektet ersätter du den krypterade nyckeln med den faktiska lagringsnyckeln som är associerad med standardlagringskontot. Mer information finns i Hantera åtkomstnycklar för lagringskonto.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b) Ta bort följande poster från
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>Punkt c Spara filen.
Lägg till huvudklassen för ditt program. I Project Explorer högerklickar du på src, pekar på Ny och väljer sedan Scala-klass.
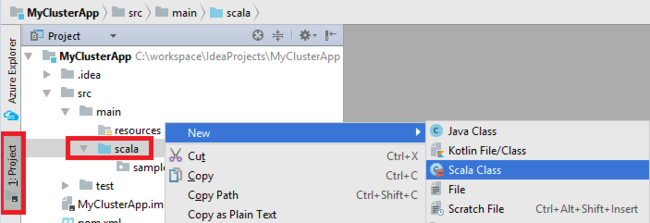
I dialogrutan Skapa ny Scala-klass anger du ett namn, väljer Objekt i rutan Typ och väljer sedan OK.
MyClusterAppMain.scalaKlistra in följande kod i filen. Den här koden skapar Spark-kontexten och öppnar enexecuteJobmetod frånSparkSampleobjektet.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Upprepa steg 8 och 9 för att lägga till ett nytt Scala-objekt med namnet
*SparkSample. Lägg till följande kod i den här klassen. Den här koden läser data från HVAC.csv (tillgänglig i alla HDInsight Spark-kluster). Den hämtar de rader som bara har en siffra i den sjunde kolumnen i CSV-filen och skriver sedan utdata till /HVACOut under standardlagringscontainern för klustret.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Upprepa steg 8 och 9 för att lägga till en ny klass med namnet
RemoteClusterDebugging. Den här klassen implementerar Spark-testramverket som används för att felsöka programmen. Lägg till följande kod iRemoteClusterDebuggingklassen:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Det finns några viktiga saker att notera:
- För
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")kontrollerar du att Spark-sammansättnings-JAR:en är tillgänglig på klusterlagringen på den angivna sökvägen. - För
setJarsanger du platsen där artefakt-JAR:en skapas. Vanligtvis är<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jardet .
- För
Högerklicka på nyckelordet
*RemoteClusterDebuggingitestklassen och välj sedan Skapa RemoteClusterDebugging-konfiguration.
I dialogrutan Skapa RemoteClusterDebugging-konfiguration anger du ett namn för konfigurationen och väljer sedan Typ av test som testnamn. Lämna alla andra värden som standardinställningar. Tryck på Tillämpa och välj sedan OK.

Nu bör du se en listruta för konfiguration av fjärrkörning i menyraden.

Steg 5: Kör programmet i felsökningsläge
Öppna och skapa en brytpunkt bredvid
SparkSample.scalai IntelliJ IDEA-projektetval rdd1. I popup-menyn Skapa brytpunkt för väljer du rad i funktionen executeJob.
Om du vill köra programmet väljer du knappen Felsöka körning bredvid listrutan Fjärrkörningskonfiguration .

När programkörningen når brytpunkten visas en felsökningsflik i det nedre fönstret.

Om du vill lägga till en klocka väljer du ikonen (+).

I det här exemplet bröt programmet innan variabeln
rdd1skapades. Med den här klockan kan vi se de första fem raderna i variabelnrdd. Välj Ange.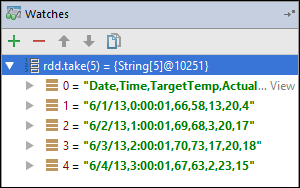
Det du ser i den föregående avbildningen är att du vid körningen kan köra frågor mot terabyte data och felsöka hur programmet fortskrider. I de utdata som visas i föregående bild kan du till exempel se att den första raden i utdata är en rubrik. Baserat på dessa utdata kan du ändra programkoden för att hoppa över rubrikraden om det behövs.
Nu kan du välja ikonen Återuppta program för att fortsätta med programkörningen.

Om programmet har slutförts bör du se utdata som följande:

Nästa steg
Scenarier
- Apache Spark med BI: Utföra interaktiv dataanalys med hjälp av Spark i HDInsight med BI-verktyg
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
Skapa och köra program
- Skapa ett fristående program med hjälp av Scala
- Köra jobb via fjärranslutning på ett Apache Spark-kluster med hjälp av Apache Livy
Verktyg och tillägg
- Använda Azure Toolkit for IntelliJ för att skapa Apache Spark-program för ett HDInsight-kluster
- Använda Azure Toolkit for IntelliJ för att fjärrsöka Apache Spark-program via SSH
- Använda HDInsight-verktyg i Azure Toolkit for Eclipse för att skapa Apache Spark-program
- Använda Apache Zeppelin-notebook-filer med ett Apache Spark-kluster i HDInsight
- Kernels tillgängliga för Jupyter Notebook i ett Apache Spark-kluster för HDInsight
- Använda externa paket med Jupyter Notebooks
- Installera Jupyter på datorn och ansluta till ett HDInsight Spark-kluster