Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Använd HDInsight Tools i Azure Toolkit for Eclipse för att utveckla Apache Spark-program som skrivits i Scala och skicka dem till ett Azure HDInsight Spark-kluster direkt från Eclipse IDE. Du kan använda plugin-programmet HDInsight Tools på några olika sätt:
- Utveckla och skicka ett Scala Spark-program i ett HDInsight Spark-kluster.
- För att få åtkomst till dina Azure HDInsight Spark-klusterresurser.
- Utveckla och köra ett Scala Spark-program lokalt.
Förutsättningar
Apache Spark-kluster i HDInsight. Anvisningar finns i Skapa Apache Spark-kluster i Azure HDInsight.
Eclipse IDE. Den här artikeln använder Eclipse IDE för Java-utvecklare.
Installera nödvändiga plugin-program
Installera Azure-verktygssats för Eclipse
Installationsinstruktioner finns i Installera Azure Toolkit for Eclipse.
Installera Scala-plugin-programmet
När du öppnar Eclipse identifierar HDInsight Tools automatiskt om du har installerat Scala-plugin-programmet. Välj OK för att fortsätta och följ sedan anvisningarna för att installera plugin-programmet från Eclipse Marketplace. Starta om IDE när installationen är klar.

Bekräfta insticksprogram
Gå till Hjälp>Eclipse Marketplace....
Välj fliken Installerad .
Du bör se minst:
- Azure Toolkit för Eclipse-versionen<>.
- Scala IDE< version>.
Logga in på din Azure-prenumeration
Starta Eclipse IDE.
Gå till Fönstret>Visa vy>övrigt...>Logga in...
I dialogrutan Visa vy navigerar du till Azure>Azure Explorer och väljer sedan Öppna.

Högerklicka på Azure-noden i Azure Explorer och välj sedan Logga in.
I dialogrutan Azure-inloggning väljer du autentiseringsmetod, väljer Logga in och slutför inloggningsprocessen.

När du har loggat in visas alla Azure-prenumerationer som är associerade med autentiseringsuppgifterna i dialogrutan Dina prenumerationer . Stäng dialogrutan genom att trycka på Välj .

Från Azure Explorer går du till Azure>HDInsight för att se HDInsight Spark-kluster under din prenumeration.

Du kan ytterligare expandera en klusternamnnod för att se de resurser (till exempel lagringskonton) som är associerade med klustret.

Länka ett kluster
Du kan länka ett normalt kluster med hjälp av det hanterade användarnamnet för Ambari. På samma sätt kan du för ett domänanslutet HDInsight-kluster länka med hjälp av domänen och användarnamnet, till exempel user1@contoso.com.
Högerklicka på HDInsight i Azure Explorer och välj Länka ett kluster.

Ange klusternamn, användarnamn och lösenord och välj sedan OK. Ange valfritt lagringskonto, lagringsnyckel och välj sedan lagringscontainer för att det ska fungera i lagringsutforskaren i den vänstra trädvyn.
Länka ny HDInsight-kluster dialogruta.
Anmärkning
Vi använder den länkade lagringsnyckeln, användarnamnet och lösenordet om klustret både loggade i Azure-prenumerationen och länkade ett kluster.

När det aktuella fokuset ligger på Lagringsnyckel måste du använda Ctrl+TAB för att fokusera på nästa fält i dialogrutan.
Du kan se det länkade klustret under HDInsight. Nu kan du skicka ett program till det här länkade klustret.

Du kan också ta bort länken till ett kluster från Azure Explorer.

Konfigurera ett Spark Scala-projekt för ett HDInsight Spark-kluster
Från Eclipse IDE-arbetsytan väljer du Fil>nytt>projekt....
I guiden Nytt projekt väljer du HDInsight Project>Spark på HDInsight (Scala). Välj sedan Nästa.

I dialogrutan Nytt HDInsight Scala-projekt anger du följande värden och väljer sedan Nästa:
- Ange ett namn för projektet.
- I JRE-området kontrollerar du att Använd en körningsmiljö JRE är inställd på JavaSE-1.7 eller senare.
- I området Spark-bibliotek kan du välja Använd Maven för att konfigurera Spark SDK-alternativet . Vårt verktyg integrerar rätt version för Spark SDK och Scala SDK. Du kan också välja alternativet Lägg till Spark SDK manuellt , ladda ned och lägga till Spark SDK manuellt.

I nästa dialogruta granskar du informationen och väljer sedan Slutför.
Skapa ett Scala-program för ett HDInsight Spark-kluster
Från Package Explorer expanderar du projektet som du skapade tidigare. Högerklicka på src, välj Nytt>annat....
I dialogrutan Välj en guide väljer du Scala-guider>Scala-objekt. Välj sedan Nästa.
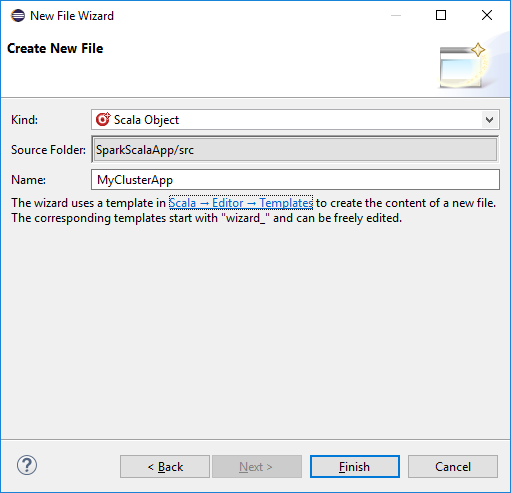
I dialogrutan Skapa ny fil anger du ett namn för objektet och väljer sedan Slutför. En textredigerare öppnas.
Ersätt det aktuella innehållet med koden nedan i textredigeraren:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Kör programmet på ett HDInsight Spark-kluster:
a. Högerklicka på projektnamnet i Paketutforskaren och välj sedan Skicka Spark-program till HDInsight.
b) I dialogrutan Spark-sändning anger du följande värden och väljer sedan Skicka:
Som Klusternamn väljer du det HDInsight Spark-kluster som du vill köra programmet på.
Välj en artefakt från Eclipse-projektet eller välj en från en hårddisk. Standardvärdet beror på det objekt som du högerklickar på från Package Explorer.
I listrutan Main class name (Huvudklassnamn) visar inmatningsguiden alla objektnamn från ditt projekt. Välj eller ange en som du vill köra. Om du har valt en artefakt från en hårddisk måste du ange huvudklassnamnet manuellt.
Eftersom programkoden i det här exemplet inte kräver några kommandoradsargument eller referens-JAR:er eller filer kan du lämna de återstående textrutorna tomma.

Fliken Spark-uppgift bör börja visa förloppet. Du kan stoppa programmet genom att välja den röda knappen i fönstret Spark Submission. Du kan också visa loggarna för den här specifika programkörningen genom att välja jordglobsikonen (som anges av den blå rutan i bilden).

Få åtkomst till och hantera HDInsight Spark-kluster med hjälp av HDInsight-verktyg i Azure Toolkit for Eclipse
Du kan utföra olika åtgärder med hjälp av HDInsight Tools, inklusive åtkomst till jobbutdata.
Få åtkomst till jobbvyn
I Azure Explorer expanderar du HDInsight, sedan Spark-klusternamnet och väljer sedan Jobb.

Välj noden Jobb . Om Java-versionen är lägre än 1,8 påminner HDInsight Tools automatiskt om att du installerar plugin-programmet E(fx)clipse . Välj OK för att fortsätta och följ sedan guiden för att installera den från Eclipse Marketplace och starta om Eclipse.

Öppna jobbvyn från noden Jobb . På den högra panelen visar fliken Spark Job View alla applikationer som kördes på klustret. Välj namnet på programmet som du vill se mer information för.

Du kan sedan vidta någon av följande åtgärder:
Hovra över jobbdiagrammet. Den visar grundläggande information om det körande jobbet. Välj jobbdiagrammet så kan du se de faser och den information som varje jobb genererar.

Välj fliken Logg för att visa loggar som används ofta, inklusive Driver Stderr, Driver Stdout och Directory Info.

Öppna användargränssnittet för Spark-historik och Apache Hadoop YARN-användargränssnittet (på programnivå) genom att välja hyperlänkarna överst i fönstret.
Få åtkomst till lagringscontainern för klustret
I Azure Explorer expanderar du HDInsight-rotnoden för att se en lista över HDInsight Spark-kluster som är tillgängliga.
Expandera klusternamnet för att se lagringskontot och standardlagringscontainern för klustret.

Välj namnet på lagringscontainern som är associerat med klustret. Dubbelklicka på mappen HVACOut i den högra rutan. Öppna en av delfilerna för att se utdata för programmet.
Få åtkomst till Spark-historikservern
I Azure Explorer högerklickar du på ditt Spark-klusternamn och väljer sedan Öppna Spark-historikgränssnittet. När du uppmanas att göra det anger du autentiseringsuppgifterna för administratören för klustret. Du angav dessa när du tillhandahöll klustret.
På instrumentpanelen för Spark-historikservern använder du programnamnet för att leta efter det program som du precis har kört. I föregående kod anger du programnamnet med hjälp
val conf = new SparkConf().setAppName("MyClusterApp")av . Så ditt Spark-programnamn var MyClusterApp.
Starta portalen Apache Ambari
Högerklicka på ditt Spark-klusternamn i Azure Explorer och välj sedan Öppna klusterhanteringsportalen (Ambari).
När du uppmanas att göra det anger du autentiseringsuppgifterna för administratören för klustret. Du angav dessa när du förberedde klustret.
Hantera Azure-prenumerationer
Som standard listar HDInsight-verktyget i Azure Toolkit for Eclipse Spark-klustren från alla dina Azure-prenumerationer. Om det behövs kan du ange de prenumerationer som du vill komma åt klustret för.
Högerklicka på Azure-rotnoden i Azure Explorer och välj sedan Hantera prenumerationer.
I dialogrutan avmarkerar du kryssrutorna för den prenumeration som du inte vill komma åt och väljer sedan Stäng. Du kan också välja Logga ut om du vill logga ut från din Azure-prenumeration .
Köra ett Spark Scala-program lokalt
Du kan använda HDInsight Tools i Azure Toolkit for Eclipse för att köra Spark Scala-program lokalt på din arbetsstation. Dessa program behöver vanligtvis inte åtkomst till klusterresurser, till exempel en lagringscontainer, och du kan köra och testa dem lokalt.
Förutsättning
När du kör det lokala Spark Scala-programmet på en Windows-dator kan du få ett undantag enligt beskrivningen i SPARK-2356. Det här undantaget beror på attWinUtils.exe saknas i Windows.
För att lösa det här felet behöver du Winutils.exe till en plats som C:\WinUtils\bin och sedan lägga till miljövariabeln HADOOP_HOME och ange värdet för variabeln till C\WinUtils.
Köra ett lokalt Spark Scala-program
Starta Eclipse och skapa ett projekt. I dialogrutan Nytt projekt gör du följande val och väljer sedan Nästa.
I guiden Nytt projekt väljer du HDInsight Project>Spark på HDInsight Local Run Sample (Scala). Välj sedan Nästa.

Om du vill ange projektinformation följer du steg 3 till och med 6 från det tidigare avsnittet Konfigurera ett Spark Scala-projekt för ett HDInsight Spark-kluster.
Mallen lägger till en exempelkod (LogQuery) under mappen src som du kan köra lokalt på datorn.

Högerklicka på LogQuery.scala och välj Kör som>1 Scala-program. Utdata som detta visas på fliken Konsol :

Läsa-endast-rollen
När användare skickar jobb till ett kluster med endast läsbehörighet krävs Ambari-autentiseringsuppgifter för detta.
Länka kluster från sammanhangsmenyn
Logga in med rollkontot endast för läsare.
Från Azure Explorer expanderar du HDInsight för att visa HDInsight-kluster som finns i din prenumeration. Klustren som är märkta "Role:Reader" har bara läsarbehörighet.

Högerklicka på klustret med endast läsbehörighet. Välj Länka det här klustret från snabbmenyn för att länka kluster. Ange Ambari-användarnamnet och lösenordet.

Om klustret har länkats uppdateras HDInsight. Klustrets etapp kommer att länkas.

Länka kluster genom att expandera noden Jobb
Klicka på Noden Jobb . Fönstret Nekad åtkomst till klusterjobb öppnas.
Klicka på Länka det här klustret för att länka klustret.
HDInsight Spark-kluster i Azure Explorer9.
Länka kluster från Spark-sändningsfönstret
Skapa ett HDInsight-projekt.
Högerklicka på paketet. Välj sedan Skicka Spark-program till HDInsight.

Välj ett kluster som har endast läsarens behörighet för Klusternamn. Varningsmeddelandet visas. Du kan klicka på Länka det här klustret för att länka klustret.

Visa lagringskonton
För kluster med behörighet endast som läsare, klicka på noden Lagringskonton, så visas fönstret Nekad lagringsåtkomst.


För länkade kluster klickar du på noden Lagringskonton , fönstret Nekad lagringsåtkomst visas.

Kända problem
När du använder Länka ett kluster föreslår jag att du anger autentiseringsuppgifter för lagring.

Det finns två lägen för att skicka jobben. Om lagringsautentiseringsuppgifter tillhandahålls används batchläge för att skicka jobbet. Annars används interaktivt läge. Om klustret är upptaget kan du få felet nedan.


Se även
Scenarier
- Apache Spark med BI: Utföra interaktiv dataanalys med Spark i HDInsight med BI-verktyg
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att analysera byggnadstemperaturen med hjälp av HVAC-data
- Apache Spark med Machine Learning: Använda Spark i HDInsight för att förutsäga resultat av livsmedelsinspektion
- Analys av webbplatsloggar med Apache Spark i HDInsight
Skapa och köra program
- Skapa ett fristående program med hjälp av Scala
- Köra jobb via fjärranslutning på ett Apache Spark-kluster med hjälp av Apache Livy
Verktyg och tillägg
- Använda Azure Toolkit for IntelliJ för att skapa och skicka Spark Scala-program
- Använd Azure Toolkit for IntelliJ för att felsöka Apache Spark-applikationer via VPN
- Använd Azure Toolkit for IntelliJ för att felsöka Apache Spark-applikationer via SSH
- Använd Apache Zeppelin-notebooks med ett Apache Spark-kluster på HDInsight
- Kernels tillgängliga för Jupyter Notebook i Apache Spark-kluster för HDInsight
- Använda externa paket med Jupyter Notebooks
- Installera Jupyter på datorn och ansluta till ett HDInsight Spark-kluster