Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I den här självstudien får du lära dig hur du skapar ett Apache Hadoop-kluster , på begäran, i Azure HDInsight med hjälp av Azure Data Factory. Sedan använder du datapipelines i Azure Data Factory för att köra Hive-jobb och ta bort klustret. I slutet av den här självstudien får du lära dig hur operationalize du kör ett stordatajobb där klusterskapande, jobbkörning och klusterborttagning utförs enligt ett schema.
Den här handledningen omfattar följande moment:
- Skapa ett Azure Storage-konto
- Förstå Azure Data Factory-aktivitet
- Skapa en datafabrik med Hjälp av Azure-portalen
- Skapa länkade tjänster
- Skapa en processkedja
- Utlösa en pipeline
- Övervaka en pipeline
- Verifiera resultatet
Om du inte har en Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
PowerShell Az-modulen har installerats.
En tjänsthuvudman för Microsoft Entra. När du har skapat tjänstens huvudregistrering måste du hämta program-ID:t och autentiseringsnyckeln med hjälp av anvisningarna i den länkade artikeln. Du kommer behöva dessa värden senare i handledningen. Kontrollera också att tjänstehuvudnamnet är medlem i Bidragsgivarrollen för prenumerationen eller resursgruppen där klustret skapas. Anvisningar om hur du hämtar nödvändiga värden och tilldelar rätt roller finns i Skapa ett Microsoft Entra-tjänsthuvudnamn.
Skapa preliminära Azure-objekt
I det här avsnittet skapar du olika objekt som ska användas för det HDInsight-kluster som du skapar på begäran. Det skapade lagringskontot innehåller hiveQL-exempelskriptet, partitionweblogs.hql, som du använder för att simulera ett Apache Hive-exempeljobb som körs i klustret.
Det här avsnittet använder ett Azure PowerShell-skript för att skapa lagringskontot och kopiera över de filer som krävs i lagringskontot. Azure PowerShell-exempelskriptet i det här avsnittet utför följande uppgifter:
- Loggar in på Azure.
- Skapar en Azure-resursgrupp.
- Konfigurerar ett Azure Storage-konto.
- Skapar en blobcontainer i lagringskontot
- Kopierar HiveQL-exempelskriptet (partitionweblogs.hql) till blobcontainern. Exempelskriptet är redan tillgängligt i en annan offentlig blobcontainer. PowerShell-skriptet nedan gör en kopia av dessa filer till det Azure Storage-konto som skapas.
Skapa lagringskonto och kopiera filer
Viktigt!
Ange namn för Azure-resursgruppen och azure-lagringskontot som skapas av skriptet. Skriv ned resursgruppsnamn, lagringskontonamn och lagringskontonyckel som matas ut av skriptet. Du behöver dem i nästa avsnitt.
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "East US"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
Verifiera lagringskonto
- Logga in på Azure-portalen.
- Från vänster går du till Alla tjänster>Allmänna>resursgrupper.
- Välj det resursgruppsnamn som du skapade i PowerShell-skriptet. Använd filtret om du har för många resursgrupper i listan.
- I översiktsvyn visas en resurs i listan om du inte delar resursgruppen med andra projekt. Den resursen är lagringskontot med det namn som du angav tidigare. Välj namnet på lagringskontot.
- Välj panelen Containrar .
- Välj containern adfgetstarted . Du ser en mapp med namnet
hivescripts. - Öppna mappen och se till att den innehåller exempelskriptfilen partitionweblogs.hql.
Förstå Azure Data Factory-aktiviteten
Azure Data Factory samordnar och automatiserar förflyttning och omvandling av data. Azure Data Factory kan skapa ett HDInsight Hadoop-kluster just-in-time för att bearbeta en indatasektor och ta bort klustret när bearbetningen är klar.
I Azure Data Factory kan en datafabrik ha en eller flera datapipelines. En datapipeline har en eller flera aktiviteter. Det finns två typer av aktiviteter:
- Dataförflyttningsaktiviteter. Du använder dataförflyttningsaktiviteter för att flytta data från ett källdatalager till ett måldatalager.
- Datatransformeringsaktiviteter. Du använder datatransformeringsaktiviteter för att transformera/bearbeta data. HDInsight Hive Activity är en av de transformeringsaktiviteter som stöds av Data Factory. Du använder Hive-transformationsaktiviteten i denna handledning.
I den här artikeln konfigurerar du Hive-aktiviteten för att skapa ett HDInsight Hadoop-kluster på begäran. När aktiviteten körs för att bearbeta data händer följande:
Ett Hadoop-kluster i HDInsight skapas automatiskt i rätt tid så att du kan bearbeta delen.
Indata bearbetas genom att ett HiveQL-skript körs i klustret. I den här handledningen utför HiveQL-skriptet som är associerat med Hive-aktiviteten följande åtgärder:
- Använder den befintliga tabellen (hivesampletable) för att skapa en annan tabell HiveSampleOut.
- Fyller i HiveSampleOut-tabellen med endast specifika kolumner från den ursprungliga hivesampletable.
HDInsight Hadoop-klustret tas bort när bearbetningen är klar och klustret är inaktivt under den konfigurerade tiden (inställningen timeToLive). Om nästa delskiva av data är tillgänglig för bearbetning inom denna inaktiva timeToLive-tid används samma kluster för att bearbeta delskivan.
Skapa en datafabrik
Logga in på Azure-portalen.
Gå till
+ Create a resource>Analytics>Data Factory på den vänstra menyn.
Ange eller välj följande värden för panelen Ny datafabrik :
Fastighet Värde Namn Ange ett namn för datafabriken. Det här namnet måste vara globalt unikt. Utgåva Lämna på V2. Subscription Välj din Azure-prenumeration. Resursgrupp Välj den resursgrupp som du skapade med hjälp av PowerShell-skriptet. Plats Platsen anges automatiskt till den plats som du angav när du skapade resursgruppen tidigare. För den här självstudien är platsen inställd på Östra USA. Aktivera GIT Avmarkera den här rutan. 
Välj Skapa. Det kan ta mellan 2 och 4 minuter att skapa en datafabrik.
När datafabriken har skapats får du ett meddelande om att distributionen lyckades med knappen Gå till resurs . Välj Gå till resurs för att öppna standardvyn Data Factory.
Välj Författare och övervaka för att starta Azure Data Factory-redigerings- och övervakningsportalen.

Skapa länkade tjänster
I det här avsnittet skapar du två länkade tjänster i datafabriken.
- En länkad Azure Storage-tjänst som länkar ditt Azure Storage-konto till datafabriken. Den här lagringen används av HDInsight-kluster på begäran. Den innehåller också Hive-skriptet som körs i klustret.
- En länkad HDInsight-tjänst på begäran. Azure Data Factory skapar automatiskt ett HDInsight-kluster och kör Hive-skriptet. HDInsight-klustret tas bort när det har varit inaktivt under en förinställd tid.
Skapa en länkad Azure Storage-tjänst
I den vänstra rutan på sidan Kom igång väljer du ikonen Författare .

Välj Anslutningar i fönstrets nedre vänstra hörn och välj sedan +Nytt.

I dialogrutan Ny länkad tjänst väljer du Azure Blob Storage och sedan Fortsätt.

Ange följande värden för den länkade lagringstjänsten:
Fastighet Värde Namn Ange HDIStorageLinkedService.Azure-prenumeration Välj din prenumeration i listrutan. Lagringskontonamn Välj det Azure Storage-konto som du skapade som en del av PowerShell-skriptet. Välj Testa anslutning och om det lyckas väljer du Skapa.

Skapa en på begäran länkad HDInsight-tjänst
Välj knappen +Ny igen för att skapa ytterligare en länkad tjänst.
I fönstret Ny länkad tjänst väljer du fliken Beräkning .
Välj Azure HDInsight och välj sedan Fortsätt.

I fönstret Ny länkad tjänst anger du följande värden och lämnar resten som standard:
Fastighet Värde Namn Ange HDInsightLinkedService.Typ Välj HDInsight på begäran. Länkad Azure Storage-tjänst Välj HDIStorageLinkedService.Klustertyp Välj hadoop Tid att leva Ange hur länge du vill att HDInsight-klustret ska vara tillgängligt innan det tas bort automatiskt. Tjänstens huvudnamn-ID Ange applikations-ID för Microsoft Entra-tjänstens huvudkonto som du skapade som ett av förkraven. Tjänstehuvudnyckel Ange autentiseringsnyckeln för Microsoft Enteras serviceprincipal. Klusternamnprefix Ange ett värde som ska prefixas för alla klustertyper som skapas av datafabriken. Subscription Välj din prenumeration i listrutan. Välj resursgrupp Välj den resursgrupp som du skapade som en del av PowerShell-skriptet som du använde tidigare. Operativsystemtyp/SSH-klusteranvändarnamn Ange ett SSH-användarnamn, vanligtvis sshuser.Operativsystemtyp/SSH-klusterlösenord Ange ett lösenord för SSH-användaren Operativsystemtyp/Klusteranvändarnamn Ange ett klusteranvändarnamn, vanligtvis admin.Operativsystemtyp/klusterlösenord Ange ett lösenord för klusteranvändaren. Välj sedan Skapa.

Skapa en processkedja
+ Välj knappen (plus) och välj sedan Pipeline.
Skapa en pipeline i Azure Data Factory.
I verktygslådan Aktiviteter expanderar du HDInsight och drar Hive-aktiviteten till pipelinedesignytan. På fliken Allmänt anger du ett namn för aktiviteten.

Kontrollera att du har valt Hive-aktiviteten och välj fliken HDI-kluster . I listrutan LÄNKAD HDInsight-tjänst väljer du den länkade tjänst som du skapade tidigare, HDInsightLinkedService, för HDInsight.

Välj fliken Skript och slutför följande steg:
För Länkad skripttjänst väljer du HDIStorageLinkedService i listrutan. Det här värdet är den lagringslänkade tjänst som du skapade tidigare.
För Filsökväg väljer du Bläddra i lagring och navigerar till den plats där hive-exempelskriptet är tillgängligt. Om du körde PowerShell-skriptet tidigare bör den här platsen vara
adfgetstarted/hivescripts/partitionweblogs.hql.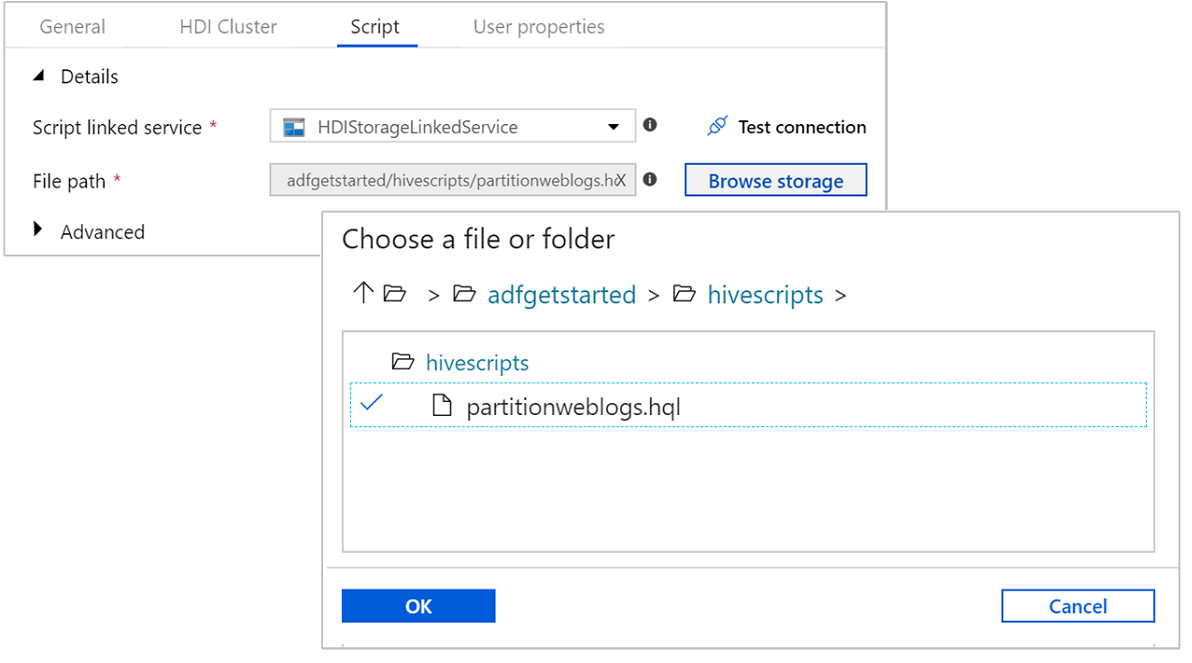
Under Avancerade>parametrar väljer du
Auto-fill from script. Det här alternativet letar efter parametrar i Hive-skriptet som behöver värden vid exekvering.I textrutan värde lägger du till den befintliga mappen i formatet
wasbs://adfgetstarted@<StorageAccount>.blob.core.windows.net/outputfolder/. Sökvägen är skiftlägeskänslig. I den här sökvägen lagras utdata från skriptet. Schematwasbsär nödvändigt eftersom lagringskonton nu har säker överföring som krävs aktiverad som standard.
Välj Verifiera för att verifiera pipelinen. Klicka på knappen >> (högerpil) för att stänga verifieringsfönstret.

Välj slutligen Publicera alla för att publicera artefakterna till Azure Data Factory.

Utlösa en pipeline
I verktygsfältet på designerytan väljer du Lägg till utlösare>nu.

Välj OK i popup-sidofältet.
Övervaka en pipeline
Växla till fliken Övervaka till vänster. En pipelinekörning visas i listan Pipeline Runs (Pipelinekörningar). Observera statusen för körningen under kolumnen Status .

Välj Uppdatera för att uppdatera statusen.
Du kan också välja ikonen Visa aktivitetskörningar för att se aktivitetskörningen som är associerad med pipelinen. I skärmbilden nedan ser du bara en aktivitetskörning eftersom det bara finns en aktivitet i pipelinen som du skapade. Om du vill växla tillbaka till föregående vy väljer du Pipelines längst upp på sidan.

Verifiera resultatet
Om du vill verifiera utdata går du till det lagringskonto som du använde för den här självstudien i Azure-portalen. Du bör se följande mappar eller containrar:
Du ser en adfgerstarted/outputfolder som innehåller utdata från Hive-skriptet som kördes som en del av pipelinen.
Du ser en container för adfhdidatafactory-linked-service-name-timestamp<><>. Den här containern är standardlagringsplatsen för HDInsight-klustret som skapades som en del av pipelinekörningen.
Du ser en adfjobs-container som har Azure Data Factory jobb-loggar.

Rensa resurser
När HDInsight-klustret skapas på begäran behöver du inte uttryckligen ta bort HDInsight-klustret. Klustret tas bort baserat på den konfiguration som du angav när du skapade pipelinen. Även när klustret har tagits bort fortsätter lagringskontona som är associerade med klustret att finnas kvar. Det här beteendet är avsiktligt så att du kan hålla dina data intakta. Men om du inte vill spara data kan du ta bort lagringskontot som du skapade.
Du kan också ta bort hela resursgruppen som du skapade för den här självstudien. Den här processen tar bort lagringskontot och Azure Data Factory som du skapade.
Ta bort resursgruppen
Logga in på Azure-portalen.
Välj Resursgrupper i det vänstra fönstret.
Välj det resursgruppsnamn som du skapade i PowerShell-skriptet. Använd filtret om du har för många resursgrupper i listan. Resursgruppen öppnas.
På panelen Resurser ska du ha standardlagringskontot och datafabriken listade såvida du inte delar resursgruppen med andra projekt.
Välj Ta bort resursgrupp. Om du gör det tas lagringskontot och data som lagras i lagringskontot bort.

Ange resursgruppens namn för att bekräfta borttagningen och välj sedan Ta bort.
Nästa steg
I den här artikeln har du lärt dig hur du använder Azure Data Factory för att skapa HDInsight-kluster på begäran och köra Apache Hive-jobb. Gå vidare till nästa artikel för att lära dig hur du skapar HDInsight-kluster med anpassad konfiguration.