Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL-database in Microsoft Fabric Preview
SQL-database in Microsoft Fabric Preview
Het ontwerpen van efficiënte indexen is essentieel voor het bereiken van goede database- en toepassingsprestaties. Een gebrek aan indexen, over-indexering of slecht ontworpen indexen zijn de belangrijkste bronnen van problemen met databaseprestaties.
In deze handleiding worden de indexarchitectuur en basisprincipes beschreven en worden aanbevolen procedures geboden om effectieve indexen te ontwerpen om te voldoen aan de behoeften van uw toepassingen.
Zie Indexen voor meer informatie over beschikbare indextypen.
In deze handleiding worden de volgende typen indexen behandeld:
| Primaire opslagindeling | Indextype |
|---|---|
| Schijfgebaseerde rijopslag | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Gegroepeerde columnstore | |
| Niet-geclusterde columnstore | |
| Memory-optimized | |
| Hash | |
| Geoptimaliseerd voor geheugen, niet-geclusterd |
Zie XML-indexen (SQL Server) en selectieve XML-indexen (SXI) voor informatie over XML-indexen.
Zie Overzicht van ruimtelijke indexen voor meer informatie over ruimtelijke indexen.
Zie Full-Text Indexen vullen voor informatie over indexen in volledige tekst.
Basisbeginselen van indexen
Denk aan een gewoon boek: aan het einde van het boek is er een index waarmee u snel informatie in het boek kunt vinden. De index is een gesorteerde lijst met trefwoorden en naast elk trefwoord is een set paginanummers die verwijzen naar de pagina's waar elk trefwoord kan worden gevonden.
Een rowstore-index is vergelijkbaar: het is een geordende lijst met waarden en voor elke waarde zijn er aanwijzingen naar de gegevenspagina's waar deze waarden zich bevinden. De index zelf wordt ook opgeslagen op pagina's, ook wel indexpagina's genoemd. Als in een normaal boek de index meerdere pagina's beslaat en u de aanwijzers moet vinden naar alle pagina's die het woord SQL bevatten, moet u bijvoorbeeld bladeren vanaf het begin van de index totdat u de indexpagina met het trefwoord SQLzoekt. Van daaruit volgt u de aanwijzingen naar alle boekpagina's. Dit kan verder worden geoptimaliseerd als u aan het begin van de index één pagina maakt die een alfabetische lijst bevat met elke letter. Bijvoorbeeld: "A tot en met D - pagina 121", "E tot en met G - pagina 122" enzovoort. Deze extra pagina elimineert de stap van bladeren door de index om het beginpunt te vinden. Een dergelijke pagina bestaat niet in gewone boeken, maar bestaat wel in een rowstore-index. Deze enkele pagina wordt de hoofdpagina van de index genoemd. De hoofdpagina is de beginpagina van de structuur die door een index wordt gebruikt. Na de structuuranalogie worden de eindpagina's met aanwijzers naar de werkelijke gegevens aangeduid als 'bladpagina's' van de boom.
Een index is een on-disk- of in-memory structuur die is gekoppeld aan een tabel of weergave waarmee rijen uit de tabel of weergave sneller worden opgehaald. Een rowstore-index bevat sleutels die zijn gebaseerd op de waarden in een of meer kolommen in de tabel of weergave. Voor rijopslagindexen worden deze sleutels opgeslagen in een structuurstructuur (B+-structuur) waarmee de database-engine de rijen kan vinden die zijn gekoppeld aan de sleutelwaarden snel en efficiënt.
In een rijopslagindex worden gegevens logisch opgeslagen als een tabel met rijen en kolommen, en fysiek opgeslagen in een gegevensindeling met de naam rowstore1. Er is een alternatieve manier om gegevenskolommen op te slaan, ook wel columnstore genoemd.
Het ontwerp van de juiste indexen voor een database en de bijbehorende workload is een complexe taak tussen querysnelheid, indexupdatekosten en opslagkosten. Beperkte rijstore-indexen op basis van schijven of indexen met weinig kolommen in de indexsleutel vereisen minder opslagruimte en een kleinere overhead voor updates. Brede indexen kunnen daarentegen meer query's verbeteren. Mogelijk moet u experimenteren met verschillende ontwerpen voordat u de meest efficiënte set indexen kunt vinden. Naarmate de toepassing zich ontwikkelt, moeten indexen mogelijk veranderen om optimale prestaties te behouden. Indexen kunnen worden toegevoegd, gewijzigd en verwijderd zonder dat dit van invloed is op het databaseschema of het toepassingsontwerp. Daarom moet u niet aarzelen om te experimenteren met verschillende indexen.
De queryoptimalisatiefunctie in de database-engine kiest meestal de meest effectieve indexen om een query uit te voeren. Als u wilt zien welke indexen de queryoptimalisatie gebruikt voor een specifieke query, selecteert u in SQL Server Management Studio in het menu Queryde optie Geschat uitvoeringsplan weergeven of Werkelijke uitvoeringsplan opnemen.
Gebruik van indexen is niet altijd gelijk aan goede prestaties en goede prestaties met efficiënt indexgebruik. Als het gebruik van een index altijd de beste prestaties heeft geleverd, is de taak van de queryoptimalisatie eenvoudig. In werkelijkheid kan een onjuiste indexkeuze minder dan optimale prestaties veroorzaken. Daarom is de taak van de queryoptimalisatie om een index of een combinatie van indexen te selecteren, alleen wanneer de prestaties worden verbeterd en om geïndexeerd ophalen te voorkomen wanneer dit de prestaties belemmert.
Een veelvoorkomende ontwerpfout is het maken van veel indexen speculatief om de optimalisatiekeuzen te geven. De resulterende overindexering vertraagt wijzigingen van gegevens en kan gelijktijdigheidsproblemen veroorzaken.
1 Rowstore is de traditionele manier om relationele tabelgegevens op te slaan. Rowstore verwijst naar een tabel waarin de onderliggende indeling voor gegevensopslag een heap, een B+-structuur (geclusterde index) of een tabel is die is geoptimaliseerd voor geheugen. Rijopslag op schijf sluit geheugen-geoptimaliseerde tabellen uit.
Indexontwerptaken
De volgende taken vormen onze aanbevolen strategie voor het ontwerpen van indexen:
Inzicht in de kenmerken van de database en de toepassing.
In een OLTP-database (Online Transaction Processing) met frequente gegevenswijzigingen die een hoge doorvoer moeten behouden, zijn een paar smalle rowstore-indexen die zijn gericht op de meest kritieke query's een goed initiële indexontwerp. Voor extreem hoge doorvoer kunt u overwegen om tabellen en indexen te gebruiken die zijn geoptimaliseerd voor geheugen en een ontwerp zonder vergrendel- en grendelsystemen bieden. Voor meer informatie zie richtlijnen voor geheugen-geoptimaliseerd niet-geclusterd indexontwerp en richtlijnen voor hash-indexontwerp in deze handleiding.
Voor een OLAP-database (analytics of datawarehousing) die zeer grote gegevenssets snel moet verwerken, zou het met name geschikt zijn om geclusterde columnstore-indexen te gebruiken. Zie Columnstore-indexen: overzicht of Columnstore-indexarchitectuur in deze handleiding voor meer informatie.
Inzicht in de kenmerken van de meest gebruikte query's.
Als u bijvoorbeeld weet dat een veelgebruikte query twee of meer tabellen samenvoegt, kunt u de set indexen voor deze tabellen bepalen.
Verkrijg inzicht in de verdeling van gegevens in de kolommen die worden gebruikt in de query-predicaten.
Een index kan bijvoorbeeld handig zijn voor kolommen met veel afzonderlijke gegevenswaarden, maar minder voor kolommen met veel dubbele waarden. Voor kolommen met veel NULL's of kolommen met goed gedefinieerde subsets van gegevens kunt u een gefilterde index gebruiken. Zie De richtlijnen voor het ontwerpen van gefilterde indexen in deze handleiding voor meer informatie.
Bepalen welke indexopties de prestaties kunnen verbeteren.
Het maken van een geclusterde index op een bestaande grote tabel kan bijvoorbeeld profiteren van de
ONLINEindexoptie. MetONLINEde optie kan gelijktijdige activiteit op de onderliggende gegevens worden voortgezet terwijl de index wordt gemaakt of opnieuw wordt opgebouwd. Het gebruik van rij- of paginagegevenscompressie kan de prestaties verbeteren door de I/O- en geheugenvoetafdruk van de index te verminderen. Zie CREATE INDEX voor meer informatie.Bekijk bestaande indexen in de tabel om te voorkomen dat dubbele of zeer vergelijkbare indexen worden gemaakt.
Het is vaak beter om een bestaande index te wijzigen dan om een nieuwe, maar meestal dubbele index te maken. U kunt bijvoorbeeld een of twee extra opgenomen kolommen toevoegen aan een bestaande index in plaats van een nieuwe index met deze kolommen te maken. Dit is met name relevant wanneer u niet-geclusterde indexen afstemt met ontbrekende indexsuggesties of als u Database Engine Tuning Advisor gebruikt, waarbij u vergelijkbare variaties van indexen op dezelfde tabel en kolommen kunt bieden.
Algemene richtlijnen voor indexontwerp
Als u de kenmerken van uw database, query's en tabelkolommen begrijpt, kunt u in eerste instantie optimale indexen ontwerpen en het ontwerp aanpassen naarmate uw toepassingen zich ontwikkelen.
Overwegingen voor databases
Houd rekening met de volgende databaserichtlijnen wanneer u een index ontwerpt:
Veel indexen op een tabel beïnvloeden de prestaties van
INSERT,UPDATE,DELETEenMERGEinstructies, omdat gegevens in indexen mogelijk moeten worden gewijzigd wanneer gegevens in de tabel veranderen. Als een kolom bijvoorbeeld in verschillende indexen wordt gebruikt en u eenUPDATEinstructie uitvoert waarmee de gegevens van die kolom worden gewijzigd, moet elke index met die kolom ook worden bijgewerkt.Vermijd over-indexering van sterk bijgewerkte tabellen en houd indexen smal, dat wil gezegd, met zo weinig mogelijk kolommen.
U kunt meer indexen hebben voor tabellen met weinig gegevenswijzigingen, maar grote hoeveelheden gegevens. Voor dergelijke tabellen kan een verscheidenheid aan indexen helpen bij het uitvoeren van queryprestaties, terwijl de overhead voor indexupdates acceptabel blijft. Maak echter geen indexen speculatief. Bewaak het indexgebruik en verwijder ongebruikte indexen in de loop van de tijd.
Het indexeren van kleine tabellen is mogelijk niet optimaal omdat het langer kan duren voordat de database-engine de index doorkruist die zoekt naar gegevens dan om een basistabelscan uit te voeren. Daarom kunnen indexen voor kleine tabellen nooit worden gebruikt, maar moeten ze nog steeds worden bijgewerkt omdat de gegevens in de tabel worden bijgewerkt.
Indexen in weergaven kunnen aanzienlijke prestatieverbeteringen opleveren wanneer de weergave aggregaties en/of joins bevat. Voor meer informatie, zie Geïndexeerde weergaven maken.
Databases op primaire replica's in Azure SQL Database genereren automatisch aanbevelingen voor de prestaties van Database Advisor voor indexen. U kunt desgewenst automatische indexafstemming inschakelen.
Query Store helpt bij het identificeren van query's met suboptimale prestaties en biedt een geschiedenis van queryuitvoeringsplannen waarmee u de indexen kunt zien die door de optimizer zijn geselecteerd. U kunt deze gegevens gebruiken om wijzigingen in indexafstemming het meest impactvol te maken door u te richten op de meest frequente en resourcegebruikte query's.
Overwegingen bij query's
Houd bij het ontwerpen van een index rekening met de volgende queryrichtlijnen:
Maak niet-geclusterde indexen voor de kolommen die vaak worden gebruikt in predicaten en join-expressies in query's. Dit zijn uw SARGable kolommen. U moet echter voorkomen dat u onnodige kolommen toevoegt aan indexen. Het toevoegen van te veel indexkolommen kan nadelig zijn voor de schijfruimte en de prestaties van indexupdates.
De term SARGable in relationele databases verwijst naar een Search ARGumentable-predicaat dat een index kan gebruiken om de uitvoering van de query te versnellen. Zie de architectuur en ontwerphandleiding voor SQL Server- en Azure SQL-indexen voor meer informatie.
Tip
Zorg er altijd voor dat de indexen die u maakt, daadwerkelijk worden gebruikt door de queryworkload. Verwijder ongebruikte indexen.
Indexgebruiksstatistieken zijn beschikbaar in sys.dm_db_index_usage_stats en sys.dm_db_index_operational_stats.
Het dekken van indexen kan de queryprestaties verbeteren, omdat alle gegevens die nodig zijn om te voldoen aan de vereisten van de query binnen de index zelf bestaan. Alleen de indexpagina's en niet de gegevenspagina's van de tabel of geclusterde index zijn vereist om de aangevraagde gegevens op te halen; daarom vermindert u de totale schijf-I/O. Bijvoorbeeld een query van kolommen
AenBop een tabel met een samengestelde index die is gemaakt op kolommenAB, enCkan de opgegeven gegevens alleen uit de index ophalen.Note
Een dekkingsindex is een niet-geclusterde index die voldoet aan alle gegevenstoegang door een query rechtstreeks zonder toegang tot de basistabel.
Dergelijke indexen hebben alle benodigde SARGable kolommen in de indexsleutel en niet-SARGable kolommen als opgenomen kolommen. Dit betekent dat alle kolommen die nodig zijn voor de query, in de
WHERE,JOINenGROUP BYcomponenten, of in deSELECTofUPDATEcomponenten, aanwezig zijn in de index.Er is mogelijk veel minder I/O om de query uit te voeren, als de index smal genoeg is in vergelijking met de rijen en kolommen in de tabel zelf, wat betekent dat het een kleine subset van alle kolommen is.
Overweeg om indexen te behandelen bij het ophalen van een klein deel van een grote tabel en waarbij dat kleine gedeelte wordt gedefinieerd door een vast predicaat.
Vermijd het maken van een bedekte index met te veel kolommen, omdat dit het voordeel ervan vermindert terwijl u databaseopslag, I/O en geheugenvoetafdruk vergroot.
Schrijf query's die zoveel mogelijk rijen in één instructie invoegen of wijzigen in plaats van meerdere query's te gebruiken om dezelfde rijen bij te werken. Dit vermindert de overhead voor indexupdates.
Overwegingen voor kolommen
Houd rekening met de volgende kolomrichtlijnen wanneer u een index ontwerpt:
Houd de lengte van de indexsleutel kort, met name voor geclusterde indexen.
Kolommen die van de gegevenstypen ntext, tekst, afbeelding, varchar(max), nvarchar(max), varbinary(max), json en vectorgegevenstypen zijn, kunnen niet worden opgegeven als indexsleutelkolommen. Kolommen met deze gegevenstypen kunnen echter aan een niet-geclusterde index worden toegevoegd als niet-sleutel (opgenomen) indexkolommen. Zie de sectie Opgenomen kolommen gebruiken in niet-geclusterde indexen in deze handleiding voor meer informatie.
Bekijk de uniekheid van kolommen. Een unieke index in plaats van een niet-unique index op dezelfde sleutelkolommen biedt aanvullende informatie voor de queryoptimalisatie die de index nuttiger maakt. Zie de richtlijnen voor het ontwerpen van unieke indexen in deze handleiding voor meer informatie.
Gegevensdistributie in de kolom onderzoeken. Het maken van een index op een kolom met veel rijen maar weinig verschillende waarden, verbetert mogelijk de prestaties van query's niet, zelfs niet als de index wordt gebruikt door de query-optimizer. Als analogie, een fysieke telefoonlijst alfabetisch gesorteerd op familienaam, versnelt het vinden van een persoon niet als alle mensen in de stad Smith of Jones worden genoemd. Zie Statistieken voor meer informatie over gegevensdistributie.
Overweeg gefilterde indexen te gebruiken voor kolommen met goed gedefinieerde subsets, bijvoorbeeld kolommen met veel NULL's, kolommen met waardencategorieën en kolommen met verschillende waardenbereiken. Een goed ontworpen gefilterde index kan de queryprestaties verbeteren, de kosten voor indexupdates verlagen en de opslagkosten verlagen door een kleine subset van alle rijen in de tabel op te slaan als die subset relevant is voor veel query's.
Houd rekening met de volgorde van de indexsleutelkolommen als de sleutel meerdere kolommen bevat. De kolom die in een gelijkheid (
=), ongelijkheid (>,>=,<,<=) uitdrukkingBETWEENof bij een join-operatie in het querypredicaat wordt gebruikt, moet als eerste worden geplaatst. Aanvullende kolommen moeten worden geordend op basis van hun niveau van onderscheid, dat wil zeggen, van het meest onderscheidend tot het minst onderscheidend.Als de index bijvoorbeeld is gedefinieerd als
LastName,FirstName, is de index handig wanneer het querypredicaat in deWHEREclausule isWHERE LastName = 'Smith'ofWHERE LastName = Smith AND FirstName LIKE 'J%'. De optimalisatiefunctie voor query's zou echter niet de index gebruiken voor een query waarop alleenWHERE FirstName = 'Jane'wordt gezocht, of de index zou de prestaties van een dergelijke query niet verbeteren.Overweeg berekende kolommen te indexeren als ze zijn opgenomen in querypredicaten. Zie Indexen voor berekende kolommenvoor meer informatie.
Indexkenmerken
Nadat u hebt vastgesteld dat een index geschikt is voor een query, kunt u het type index selecteren dat het beste bij uw situatie past. Indexkenmerken zijn onder andere:
- Geclusterd of niet-geclusterd
- Uniek of niet-zelfstandig
- Eén kolom of meerdere kolommen
- Oplopende of aflopende volgorde voor de sleutelkolommen in de index
- Alle rijen of gefilterd voor niet-geclusterde indexen
- Columnstore of Rowstore
- Hash of niet geclusterd voor tabellen die zijn geoptimaliseerd voor geheugen
Plaatsing van indexen in bestandsgroepen of partitieschema's
Wanneer u uw strategie voor indexontwerp ontwikkelt, moet u rekening houden met de plaatsing van de indexen op de bestandsgroepen die aan de database zijn gekoppeld.
Standaard worden indexen opgeslagen in dezelfde bestandsgroep als de basistabel (geclusterde index of heap) waarop de index wordt gemaakt. Andere configuraties zijn mogelijk, waaronder:
Maak niet-geclusterde indexen op een andere bestandsgroep dan de bestandsgroep van de basistabel.
Geclusterde en niet-geclusterde indexen partitioneren om meerdere bestandsgroepen te omvatten.
Voor niet-gepartitioneerde tabellen is de eenvoudigste methode meestal het beste: maak alle tabellen in dezelfde bestandsgroep en voeg zoveel gegevensbestanden toe aan de bestandsgroep als nodig is om alle beschikbare fysieke opslag te gebruiken.
Er kunnen meer geavanceerde benaderingen voor indexplaatsing worden overwogen wanneer gelaagde opslag beschikbaar is. U kunt bijvoorbeeld een bestandsgroep maken voor veelgebruikte tabellen met bestanden op snellere schijven en een bestandsgroep voor archieftabellen op tragere schijven.
U kunt een tabel met een geclusterde index van de ene bestandsgroep naar de andere verplaatsen door de geclusterde index te verwijderen en een nieuw bestandsgroep- of partitieschema op te geven in de MOVE TO component van de DROP INDEX instructie of door de CREATE INDEX instructie met de DROP_EXISTING component te gebruiken.
Gepartitioneerde indexen
U kunt ook overwegen om schijfgebaseerde heaps, geclusterde en niet-geclusterde indexen te partitioneren in meerdere bestandsgroepen. Gepartitioneerde indexen worden horizontaal gepartitioneerd (per rij), op basis van een partitiefunctie. De partitiefunctie definieert hoe elke rij wordt toegewezen aan een partitie op basis van de waarden van een bepaalde kolom die u aanwijst, de partitioneringskolom genoemd. Een partitieschema geeft de toewijzing van een set partities aan een bestandsgroep aan.
Het partitioneren van een index kan de volgende voordelen bieden:
Maak grote databases beter beheerbaar. OLAP-systemen kunnen bijvoorbeeld partitiebewuste ETL implementeren die het bulksgewijs toevoegen en verwijderen van gegevens aanzienlijk vereenvoudigt.
Zorg ervoor dat bepaalde typen query's, zoals langlopende analytische query's, sneller worden uitgevoerd. Wanneer query's een gepartitioneerde index gebruiken, kan de database-engine meerdere partities tegelijk verwerken en partities overslaan (elimineren) die niet nodig zijn voor de query.
Waarschuwing
Partitionering verbetert zelden de queryprestaties in OLTP-systemen, maar het kan een aanzienlijke overhead veroorzaken als een transactionele query toegang moet hebben tot veel partities.
Zie Gepartitioneerde tabellen en indexen voor meer informatie.
Ontwerprichtlijnen voor sorteervolgorde van de index
Overweeg bij het definiëren van indexen of elke indexsleutelkolom in oplopende of aflopende volgorde moet worden opgeslagen. Oplopend is de standaardwaarde. De syntaxis van de CREATE INDEX, CREATE TABLE, en ALTER TABLE verklaringen ondersteunt de trefwoorden ASC (oplopend) en DESC (aflopend) op afzonderlijke kolommen in indexen en beperkingen.
Het opgeven van de volgorde waarin sleutelwaarden in een index worden opgeslagen, is handig wanneer query's die naar de tabel verwijzen, componenten bevatten ORDER BY die verschillende richtingen opgeven voor de sleutelkolom of -kolommen in die index. In deze gevallen kan de index de noodzaak voor een sorteeroperator in het queryplan verwijderen.
De kopers in de inkoopafdeling Adventure Works Cycles moeten bijvoorbeeld de kwaliteit evalueren van producten die ze kopen bij leveranciers. De kopers zijn het meest geïnteresseerd in het vinden van producten die door leveranciers worden verzonden met een hoog afwijzingspercentage.
Zoals wordt weergegeven in de volgende query op basis van de AdventureWorks-voorbeelddatabase, moet de RejectedQty kolom in de Purchasing.PurchaseOrderDetail tabel in aflopende volgorde (groot naar klein) worden gesorteerd en moet de ProductID kolom in oplopende volgorde (klein tot groot) worden gesorteerd.
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
In het volgende uitvoeringsplan voor deze query ziet u dat de queryoptimalisatie een sorteeroperator heeft gebruikt om de resultatenset te retourneren in de volgorde die is opgegeven door de ORDER BY component.

Als er een op schijf gebaseerde rowstore-index wordt gemaakt met sleutelkolommen die overeenkomen met de kolommen in de ORDER BY component in de query, wordt de sorteeroperator in het queryplan geëlimineerd, waardoor het queryplan efficiënter wordt.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
Nadat de query opnieuw is uitgevoerd, ziet u in het volgende uitvoeringsplan dat de operator Sorteren niet meer aanwezig is en dat de zojuist gemaakte niet-geclusterde index wordt gebruikt.
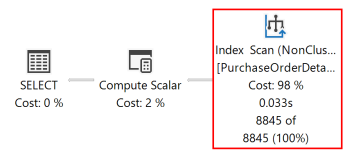
De database-engine kan een index in beide richtingen scannen. Een index die is gedefinieerd als RejectedQty DESC, ProductID ASC kan nog steeds worden gebruikt voor een query waarin de sorteerrichtingen van de kolommen in de ORDER BY component worden omgekeerd. Een query met de ORDER BY component ORDER BY RejectedQty ASC, ProductID DESC kan bijvoorbeeld dezelfde index gebruiken.
De sorteervolgorde kan alleen worden opgegeven voor de sleutelkolommen in de index. De sys.index_columns catalogusweergave geeft aan of een indexkolom in oplopende of aflopende volgorde wordt opgeslagen.
Ontwerprichtlijnen voor geclusterde indexen
In de geclusterde index worden alle rijen en alle kolommen van een tabel opgeslagen. Rijen worden gesorteerd in de volgorde van indexsleutelwaarden. Er kan slechts één geclusterde index per tabel zijn.
De term basistabel kan verwijzen naar een geclusterde index of naar een heap. Een heap is een niet-gesorteerde gegevensstructuur op schijf die alle rijen en alle kolommen van een tabel bevat.
Met enkele uitzonderingen moet elke tabel een geclusterde index hebben. De gewenste eigenschappen van de geclusterde index zijn:
| Vastgoed | Description |
|---|---|
| Smal | De geclusterde indexsleutel maakt deel uit van een niet-geclusterde index in dezelfde basistabel. Een smalle sleutel of een sleutel waarbij de totale lengte van sleutelkolommen klein is, vermindert de opslag, I/O en geheugenoverhead van alle indexen in een tabel. Als u de sleutellengte wilt berekenen, voegt u de opslaggrootten toe voor de gegevenstypen die worden gebruikt door sleutelkolommen. Zie Gegevenstypecategorieën voor meer informatie. |
| Uniek | Als de geclusterde index niet uniek is, wordt er automatisch een interne unieke kolom van 4 bytes toegevoegd aan de indexsleutel om de uniekheid te garanderen. Als u een bestaande unieke kolom toevoegt aan de geclusterde indexsleutel, vermijdt u de opslag-, I/O- en geheugenbelasting van de uniqueifier-kolom in alle indexen op een tabel. Daarnaast kan de queryoptimalisatie efficiëntere queryplannen genereren wanneer een index uniek is. |
| Steeds groter | In een steeds toenemende index worden gegevens altijd toegevoegd op de laatste pagina van de index. Hierdoor worden paginasplitsingen in het midden van de index vermeden, waardoor de paginadichtheid wordt verminderd en de prestaties afnemen. |
| Onveranderlijk | De geclusterde indexsleutel maakt deel uit van een niet-geclusterde index. Wanneer een sleutelkolom van een geclusterde index wordt gewijzigd, moet er ook een wijziging worden aangebracht in alle niet-geclusterde indexen, waarmee een CPU, logboekregistratie, I/O en geheugenoverhead worden toegevoegd. De overhead wordt vermeden als de sleutelkolommen van de geclusterde index onveranderbaar zijn. |
| Heeft alleen niet-nullbare kolommen | Als een rij null-kolommen bevat, moet deze een interne structuur bevatten die een NULL-blok wordt genoemd, waarmee 3-4 bytes opslagruimte per rij in een index wordt toegevoegd. Als u alle kolommen van de geclusterde index niet nullable maakt, voorkomt u deze overhead. |
| Heeft alleen kolommen met vaste breedte | Kolommen met gegevenstypen voor variabele breedte, zoals varchar of nvarchar , gebruiken een extra 2 bytes per waarde in vergelijking met gegevenstypen met vaste breedte. Het gebruik van gegevenstypen met vaste breedte, zoals int , voorkomt deze overhead in alle indexen in de tabel. |
Het voldoen aan zoveel mogelijk van deze eigenschappen bij het ontwerpen van een geclusterde index maakt niet alleen de geclusterde index, maar ook alle niet-geclusterde indexen in dezelfde tabel efficiënter. De prestaties worden verbeterd door opslag, I/O en geheugenoverhead te voorkomen.
Een geclusterde indexsleutel met één int of bigint-kolom die niet null mag zijn, heeft bijvoorbeeld al deze eigenschappen als deze is gevuld met een IDENTITY clausule of een standaardvoorwaarde met een reeks en niet wordt bijgewerkt nadat een rij is ingevoegd.
Omgekeerd is een geclusterde indexsleutel met één unieke id-kolom breder omdat deze 16 bytes opslagruimte gebruikt in plaats van 4 bytes voor int en 8 bytes voor bigint, en niet voldoet aan de steeds toenemende eigenschap, tenzij de waarden opeenvolgend worden gegenereerd.
Tip
Wanneer u een PRIMARY KEY beperking maakt, wordt automatisch een unieke index gemaakt die de beperking ondersteunt. Deze index is standaard geclusterd; Als deze index echter niet voldoet aan de gewenste eigenschappen van de geclusterde index, kunt u de beperking maken als niet-geclusterd en in plaats daarvan een andere geclusterde index maken.
Als u geen geclusterde index maakt, wordt de tabel opgeslagen als een heap, wat over het algemeen niet wordt aanbevolen.
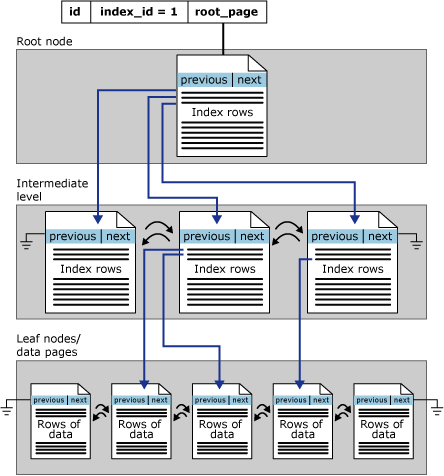
Geclusterde indexarchitectuur
Rowstore-indexen zijn ingedeeld als B+-bomen. Elke pagina in een index B+ structuur wordt een indexknooppunt genoemd. Het bovenste knooppunt van de B+-structuur wordt het hoofdknooppunt genoemd. De onderste knooppunten in de index worden de leaf-knooppunten genoemd. Indexniveaus tussen de hoofd- en bladknooppunten worden gezamenlijk tussenliggende niveaus genoemd. In een geclusterde index bevatten de bladknooppunten de gegevenspagina's van de onderliggende tabel. De hoofd- en tussenliggende niveauknooppunten bevatten indexpagina's met indexrijen. Elke indexrij bevat een sleutelwaarde en een aanwijzer naar een pagina met een tussenliggend niveau in de B+-structuur of een gegevensrij op het bladniveau van de index. De pagina's in elk niveau van de index worden gekoppeld in een dubbel gekoppelde lijst.
Geclusterde indexen hebben één rij in sys.partitions voor elke partitie die door de index wordt gebruikt, met index_id = 1. Een geclusterde index heeft standaard één partitie. Wanneer een geclusterde index meerdere partities heeft, heeft elke partitie een afzonderlijke B+-structuur met de gegevens voor die specifieke partitie. Als een geclusterde index bijvoorbeeld vier partities heeft, zijn er vier B+ structuurstructuren, één in elke partitie.
Afhankelijk van de gegevenstypen in de geclusterde index heeft elke geclusterde indexstructuur een of meer toewijzingseenheden waarin de gegevens voor een specifieke partitie moeten worden opgeslagen en beheerd. Elke geclusterde index heeft minimaal één IN_ROW_DATA toewijzingseenheid per partitie. De geclusterde index heeft ook één LOB_DATA toewijzingseenheid per partitie als deze grote objectkolommen (LOB) bevat, zoals nvarchar(max). Het heeft ook één ROW_OVERFLOW_DATA toewijzingseenheid per partitie als deze kolommen met een variabele lengte bevat die de limiet van 8.060 byterijen overschrijden.
De pagina's in de B+-structuur zijn gerangschikt op de waarde van de geclusterde indexsleutel. Alle invoegingen worden gemaakt op de pagina waar de sleutelwaarde in de ingevoegde rij in de volgorde van bestaande pagina's past. Binnen een pagina worden rijen niet noodzakelijkerwijs opgeslagen in een fysieke volgorde. De pagina onderhoudt echter een logische volgorde van rijen met behulp van een interne structuur die een slot-array wordt genoemd. Vermeldingen in de sitematrix worden bijgehouden in de volgorde van de indexsleutel.
In deze afbeelding ziet u de structuur van een geclusterde index in één partitie.
Ontwerprichtlijnen voor niet-geclusterde indexen
Het belangrijkste verschil tussen een geclusterde en een niet-geclusterde index is dat een niet-geclusterde index een subset van de kolommen in de tabel bevat, meestal anders gesorteerd dan de geclusterde index. Optioneel kan een niet-geclusterde index worden gefilterd, wat betekent dat deze een subset bevat van alle rijen in de tabel.
Een niet-geclusterde rijopslagindex op schijf bevat de rijlocators die wijzen naar de opslaglocatie van de rij in de basistabel. U kunt meerdere niet-geclusterde indexen maken in een tabel of geïndexeerde weergave. Over het algemeen moeten niet-geclusterde indexen worden ontworpen om de prestaties te verbeteren van veelgebruikte query's die anders de basistabel moeten scannen.
Net als bij het gebruik van een index in een boek zoekt de queryoptimalisatie naar een gegevenswaarde door de niet-geclusterde index te doorzoeken om de locatie van de gegevenswaarde in de tabel te vinden en vervolgens de gegevens rechtstreeks van die locatie op te halen. Dit maakt niet-geclusterde indexen de optimale keuze voor exacte overeenkomstquery's, omdat de index vermeldingen bevat die de exacte locatie in de tabel beschrijven van de gegevenswaarden waarnaar wordt gezocht in de query's.
Als u bijvoorbeeld een query wilt uitvoeren op de HumanResources.Employee tabel voor alle werknemers die rapporteren aan een specifieke manager, kan de queryoptimalisatie de niet-geclusterde index IX_Employee_ManagerIDgebruiken; dit heeft ManagerID als eerste sleutelkolom. Omdat de ManagerID waarden in de niet-geclusterde index zijn gerangschikt, kan de queryoptimalisatie snel alle vermeldingen in de index vinden die overeenkomen met de opgegeven ManagerID waarde. Elke indexvermelding verwijst naar de exacte pagina en rij in de basistabel, waar de bijbehorende gegevens uit alle andere kolommen kunnen worden opgehaald. Nadat de queryoptimalisatie alle vermeldingen in de index heeft gevonden, kan deze rechtstreeks naar de exacte pagina en rij gaan om de gegevens op te halen in plaats van de hele basistabel te scannen.
Niet-geclusterde indexarchitectuur
Niet-geclusterde indexen op basis van schijfopslag hebben dezelfde B+ structuurstructuur als geclusterde indexen, met uitzondering van de volgende verschillen:
Een niet-geclusterde index bevat niet noodzakelijkerwijs alle kolommen en rijen van de tabel.
Het bladniveau van een niet-geclusterde index bestaat uit indexpagina's in plaats van gegevenspagina's. De indexpagina's op het bladniveau van een niet-geclusterde index bevatten sleutelkolommen. Optioneel kunnen ze ook een subset van andere kolommen in de tabel bevatten, zoals opgenomen kolommen, om te voorkomen dat ze worden opgehaald uit de basistabel.
De rijzoekers in niet-geclusterde indexrijen zijn een aanwijzer naar een rij of een geclusterde indexsleutel voor een rij, zoals als volgt wordt beschreven:
Als de tabel een geclusterde index heeft of als de index zich in een geïndexeerde weergave bevindt, is de rijzoeker de geclusterde indexsleutel voor de rij.
Als de tabel een heap is, wat betekent dat deze geen geclusterde index heeft, is de rijzoeker een aanwijzer naar de rij. De aanwijzer is gebaseerd op de bestands-id (ID), het paginanummer en het nummer van de rij op de pagina. De hele aanwijzer staat bekend als een Row-ID (RID).
Rijverwijzers zorgen ook voor uniciteit bij niet-geclusterde indexrijen. In de volgende tabel wordt beschreven hoe de database-engine rijzoekers toevoegt aan niet-geclusterde indexen:
| Basistabeltype | Niet-geclusterd indextype | Rijzoeker |
|---|---|---|
| Heap | ||
| Nonunique | RID toegevoegd aan sleutelkolommen | |
| Unique | RID toegevoegd aan opgenomen kolommen | |
| Unieke geclusterde index | ||
| Nonunique | Geclusterde indexsleutels toegevoegd aan sleutelkolommen | |
| Unique | Geclusterde indexsleutels toegevoegd aan opgenomen kolommen | |
| Niet-unieke geclusterde index | ||
| Nonunique | Geclusterde indexsleutels en uniqueifier (indien aanwezig) toegevoegd aan sleutelkolommen | |
| Unique | Geclusterde indexsleutels en unieke classificatie (indien aanwezig) toegevoegd aan opgenomen kolommen |
De database-engine slaat nooit meer dan één keer een bepaalde kolom op in een niet-geclusterde index. De indexsleutelvolgorde die door de gebruiker is opgegeven wanneer ze een niet-geclusterde index maken, wordt altijd gehonoreerd: alle kolommen van de rijzoeker die moeten worden toegevoegd aan de sleutel van een niet-geclusterde index, worden toegevoegd aan het einde van de sleutel, na de kolommen die zijn opgegeven in de indexdefinitie. Geclusterde indexsleutelzoekers in een niet-geclusterde index kunnen worden gebruikt bij het verwerken van query's, ongeacht of ze expliciet zijn opgegeven in de indexdefinitie of impliciet worden toegevoegd.
In de volgende voorbeelden ziet u hoe rijzoekers worden geïmplementeerd in niet-geclusterde indexen:
| Geclusterde index | Niet-geclusterde indexdefinitie | Niet-geclusterde indexdefinitie met rijverwijzers | Explanation |
|---|---|---|---|
Unieke geclusterde index met sleutelkolommen (A, B, C) |
Niet-geclusterde index met sleutelkolommen (B, A) en opgenomen kolommen (E, G) |
Sleutelkolommen (B, A, C) en opgenomen kolommen (E, G) |
De niet-geclusterde index is niet-uniek, dus de rijlocatie moet aanwezig zijn in de indexsleutels. Kolommen B en A van de rijzoeker zijn al aanwezig, dus wordt alleen kolom C toegevoegd. De kolom C wordt toegevoegd aan het einde van de lijst met sleutelkolommen. |
Unieke geclusterde index met sleutelkolom (A) |
Niet-geclusterde index met sleutelkolommen (B, C) en opgenomen kolom (A) |
Sleutelkolommen (B, C, A) |
De niet-geclusterde index is niet uniek, dus de rijzoeker wordt aan de sleutel toegevoegd. Kolom A is nog niet opgegeven als sleutelkolom, dus wordt deze toegevoegd aan het einde van de lijst met sleutelkolommen. De kolom A bevindt zich nu in de sleutel, dus u hoeft deze niet op te slaan als een opgenomen kolom. |
Unieke geclusterde index met sleutelkolom (A, B) |
Unieke niet-geclusterde index met sleutelkolom (C) |
Sleutelkolom (C) en opgenomen kolommen (A, B) |
De niet-geclusterde index is uniek, dus de rijzoeker wordt toegevoegd aan de opgenomen kolommen. |
Niet-geclusterde indexen hebben één rij in sys.partitions voor elke partitie die door de index wordt gebruikt, met index_id > 1. Een niet-geclusterde index heeft standaard één partitie. Wanneer een niet-geclusterde index meerdere partities heeft, heeft elke partitie een B+-structuur met de indexrijen voor die specifieke partitie. Als een niet-geclusterde index bijvoorbeeld vier partities heeft, zijn er vier B+ structuurstructuren, één in elke partitie.
Afhankelijk van de gegevenstypen in de niet-geclusterde index heeft elke niet-geclusterde indexstructuur een of meer toewijzingseenheden waarin de gegevens voor een specifieke partitie moeten worden opgeslagen en beheerd. Elke niet-geclusterde index heeft minimaal één IN_ROW_DATA toewijzingseenheid per partitie waarin de index B+ structuurpagina's worden opgeslagen. De niet-geclusterde index heeft ook één LOB_DATA toewijzingseenheid per partitie als deze grote objectkolommen (LOB) bevat, zoals nvarchar(max). Daarnaast heeft het één ROW_OVERFLOW_DATA toewijzingseenheid per partitie als deze kolommen met een variabele lengte bevat die de limiet van 8.060 byterijen overschrijden.
In de volgende afbeelding ziet u de structuur van een niet-geclusterde index in één partitie.

Opgenomen kolommen gebruiken in niet-geclusterde indexen
Naast sleutelkolommen kan een niet-geclusterde index ook niet-sleutelkolommen bevatten die zijn opgeslagen op het bladniveau. Deze niet-sleutelkolommen worden opgenomen kolommen genoemd en worden opgegeven in de INCLUDE component van de CREATE INDEX instructie.
Een index met opgenomen niet-sleutelkolommen kan de prestaties van query's aanzienlijk verbeteren wanneer de query wordt behandeld, dat wil gezegd, wanneer alle kolommen die in de query worden gebruikt, zich in de index bevinden als sleutel- of niet-sleutelkolommen. Prestatieverbeteringen worden bereikt omdat de database-engine alle kolomwaarden in de index kan vinden; de basistabel wordt niet geopend, wat resulteert in minder I/O-bewerkingen van de schijf.
Als een kolom moet worden opgehaald door een query, maar niet wordt gebruikt in de querypredicaten, aggregaties en sorteringen, voegt u deze toe als een opgenomen kolom en niet als sleutelkolom. Dit heeft de volgende voordelen:
Opgenomen kolommen kunnen gegevenstypen gebruiken die niet zijn toegestaan als indexsleutelkolommen.
Opgenomen kolommen worden niet meegenomen door de database-engine bij het berekenen van het aantal indexsleutelkolommen of de grootte van de indexsleutel. Bij opgenomen kolommen bent u niet beperkt door de maximale sleutelgrootte van 900 bytes. U kunt bredere indexen maken die betrekking hebben op meer query's.
Wanneer u een kolom verplaatst van de indexsleutel naar opgenomen kolommen, duurt de indexbuild minder tijd omdat de indexsorteerbewerking sneller wordt.
Als de tabel een geclusterde index heeft, worden de kolom of kolommen die in de geclusterde indexsleutel zijn gedefinieerd, automatisch toegevoegd aan elke niet-geclusterde niet-geclusterde index in de tabel. Het is niet nodig om ze op te geven in de niet-geclusterde indexsleutel of als opgenomen kolommen.
Richtlijnen voor indexen met opgenomen kolommen
Houd rekening met de volgende richtlijnen wanneer u niet-geclusterde indexen ontwerpt met opgenomen kolommen:
Opgenomen kolommen kunnen alleen worden gedefinieerd in niet-geclusterde indexen in tabellen of geïndexeerde weergaven.
Alle gegevenstypen zijn toegestaan, behalve tekst, ntexten afbeelding.
Berekende kolommen die deterministisch zijn en die nauwkeurig of onnauwkeurig zijn, kunnen kolommen worden opgenomen. Zie Indexen voor berekende kolommenvoor meer informatie.
Net als bij belangrijke kolommen kunnen berekende kolommen die zijn afgeleid van gegevenstypen afbeelding, ntext en tekst , kolommen opnemen zolang het berekende kolomgegevenstype is toegestaan in een opgenomen kolom.
Kolomnamen kunnen niet worden opgegeven in zowel de
INCLUDElijst als in de lijst met sleutelkolommen.Kolomnamen kunnen niet worden herhaald in de
INCLUDElijst.Er moet ten minste één sleutelkolom worden gedefinieerd in een index. Het maximum aantal opgenomen kolommen is 1023. Dit is het maximum aantal tabelkolommen min 1.
Ongeacht de aanwezigheid van opgenomen kolommen, moeten indexsleutelkolommen voldoen aan de bestaande indexgroottebeperkingen van maximaal 16 sleutelkolommen en een totale indexsleutelgrootte van 900 bytes.
Aanbevelingen voor ontwerpen voor indexen met opgenomen kolommen
Overweeg om niet-geclusterde indexen opnieuw te ontwerpen met een grote indexsleutelgrootte, zodat alleen kolommen die worden gebruikt in querypredicaten, aggregaties en sorteringen belangrijke kolommen zijn. Maak alle andere kolommen die betrekking hebben op de query die niet-sleutelkolommen bevat. Op deze manier hebt u alle kolommen nodig om de query te behandelen, maar de indexsleutel zelf is klein en efficiënt.
Stel dat u een index wilt ontwerpen om de volgende query te behandelen.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
Als u de query wilt behandelen, moet elke kolom worden gedefinieerd in de index. Hoewel u alle kolommen als sleutelkolommen kunt definiëren, is de sleutelgrootte 334 bytes. Omdat de enige kolom die wordt gebruikt als zoekcriteria de PostalCode kolom is, met een lengte van 30 bytes, zou een beter indexontwerp worden gedefinieerd PostalCode als de sleutelkolom en alle andere kolommen als niet-sleutelkolommen bevatten.
Met de volgende instructie maakt u een index met bijbehorende kolommen om de query te ondersteunen.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Als u wilt controleren of de index betrekking heeft op de query, maakt u de index en geeft u vervolgens het geschatte uitvoeringsplan weer. Als in het uitvoeringsplan een operator indexzoeken voor de IX_Address_PostalCode index wordt weergegeven, wordt de query gedekt door de index.
Prestatieoverwegingen voor indexen met opgenomen kolommen
Vermijd het maken van indexen met een zeer groot aantal opgenomen kolommen. Hoewel de index mogelijk betrekking heeft op meer query's, is het prestatievoordeel afgenomen omdat:
Minder indexrijen passen op een pagina. Dit verhoogt de I/O van de schijf en vermindert de efficiëntie van de cache.
Er is meer schijfruimte nodig om de index op te slaan. Met name het toevoegen van varchar(max), nvarchar(max), varbinary(max), of XML-gegevenstypen in opgenomen kolommen kunnen de schijfruimte aanzienlijk verhogen. Dit komt doordat de kolomwaarden worden gekopieerd naar het niveau van het indexblad. Daarom bevinden ze zich in zowel de index als de basistabel.
De prestaties van gegevenswijziging nemen af omdat veel kolommen zowel in de gebaseerde tabel als in de niet-geclusterde index moeten worden gewijzigd.
U moet bepalen of de winst in queryprestaties opweegt tegen de afname van de prestaties van gegevenswijziging en de toename van de schijfruimtevereisten.
Richtlijnen voor het ontwerpen van unieke indexen
Een unieke index garandeert dat de indexsleutel geen dubbele waarden bevat. Het maken van een unieke index is alleen mogelijk wanneer uniekheid een kenmerk is van de gegevens zelf. Als u er bijvoorbeeld voor wilt zorgen dat de waarden in de NationalIDNumber kolom in de HumanResources.Employee tabel uniek zijn wanneer de primaire sleutel is EmployeeID, maakt u een UNIQUE beperking voor de NationalIDNumber kolom. De beperking weigert pogingen om rijen met dubbele nationale id-nummers te introduceren.
Met unieke indexen met meerdere kolommen garandeert de index dat elke combinatie van waarden in de indexsleutel uniek is. Als er bijvoorbeeld een unieke index wordt gemaakt op basis van een combinatie van LastName, FirstName, en MiddleName kolommen, kunnen geen twee rijen in de tabel dezelfde waarden hebben voor deze kolommen.
Zowel geclusterde als niet-geclusterde indexen kunnen uniek zijn. U kunt een unieke geclusterde index en meerdere unieke niet-geclusterde indexen in dezelfde tabel maken.
De voordelen van unieke indexen zijn:
- Bedrijfsregels waarvoor gegevens uniek zijn, worden afgedwongen.
- Aanvullende informatie die nuttig is voor de queryoptimalisatie wordt verstrekt.
Het maken van een PRIMARY KEY of UNIQUE beperking creëert automatisch een unieke index op de opgegeven kolommen. Er zijn geen belangrijke verschillen tussen het maken van een UNIQUE beperking en het maken van een unieke index onafhankelijk van een beperking. Gegevensvalidatie vindt op dezelfde manier plaats en de queryoptimalisatie maakt geen onderscheid tussen een unieke index die is gemaakt door een beperking of handmatig gemaakt. U moet echter een UNIQUE of PRIMARY KEY beperking voor de kolom maken wanneer het afdwingen van bedrijfsregels het doel is. Hierdoor is het doel van de index duidelijk.
Overwegingen voor unieke indexen
Er kan geen unieke index,
UNIQUEbeperking ofPRIMARY KEYbeperking worden gemaakt als er dubbele sleutelwaarden aanwezig zijn in de gegevens.Als de gegevens uniek zijn en u wilt dat de uniekheid wordt afgedwongen, biedt het maken van een unieke index in plaats van een niet-logische index op dezelfde combinatie van kolommen aanvullende informatie voor de queryoptimalisatie die efficiëntere uitvoeringsplannen kan produceren. In dit geval wordt het maken van een
UNIQUEbeperking of een unieke index aanbevolen.Een unieke niet-geclusterde index kan niet-sleutelkolommen bevatten. Zie Opgenomen kolommen gebruiken in niet-geclusterde indexen voor meer informatie.
In tegenstelling tot een
PRIMARY KEYbeperking kan eenUNIQUEbeperking of een unieke index worden gemaakt met een null-kolom in de indexsleutel. Voor het afdwingen van uniekheid worden twee NULL's als gelijk beschouwd. Dit betekent bijvoorbeeld dat in een unieke index met één kolom de kolom NULL kan zijn voor één rij in de tabel.
Richtlijnen voor het ontwerpen van gefilterde indexen
Een gefilterde index is een geoptimaliseerde niet-geclusterde index, met name geschikt voor query's waarvoor een kleine subset van gegevens in de tabel is vereist. Er wordt een filterpredicaat in de indexdefinitie gebruikt om een deel van de rijen in de tabel te indexeren. Een goed ontworpen gefilterde index kan de prestaties van query's verbeteren, de kosten voor indexupdates verlagen en de kosten voor indexopslag verlagen in vergelijking met een volledige-tabelindex.
Gefilterde indexen kunnen de volgende voordelen bieden ten opzichte van indexen in volledige tabellen:
Verbeterde prestatie van query's en kwaliteit van plannen
Een goed ontworpen gefilterde index verbetert de prestaties van query's en de kwaliteit van het uitvoeringsplan omdat deze kleiner is dan een niet-geclusterde volledige tabel. Een gefilterde index heeft gefilterde statistieken, die nauwkeuriger zijn dan volledige tabelstatistieken, omdat ze alleen de rijen in de gefilterde index behandelen.
Lagere kosten voor indexupdates
Een index wordt alleen bijgewerkt wanneer DML-instructies (Data Manipulat Language) van invloed zijn op de gegevens in de index. Een gefilterde index vermindert de kosten voor indexupdates vergeleken met een niet-geclusterde index in een volledige tabel, omdat deze kleiner is en alleen wordt bijgewerkt wanneer de gegevens in de index worden beïnvloed. Het is mogelijk om een groot aantal gefilterde indexen te hebben, met name wanneer ze gegevens bevatten die niet vaak worden beïnvloed. Als een gefilterde index alleen de vaak beïnvloede gegevens bevat, vermindert de kleinere grootte van de index de kosten voor het bijwerken van statistieken.
Lagere kosten voor indexopslag
Het maken van een gefilterde index kan de schijfopslag voor niet-geclusterde indexen verminderen wanneer een volledige tabelindex niet nodig is. Mogelijk kunt u een niet-geclusterde volledige tabelindex vervangen door meerdere gefilterde indexen zonder de opslagvereisten aanzienlijk te verhogen.
Gefilterde indexen zijn handig wanneer kolommen goed gedefinieerde subsets van gegevens bevatten. Voorbeelden zijn:
Kolommen die veel NULL-waarden bevatten.
Heterogene kolommen die categorieën gegevens bevatten.
Kolommen die reeksen van waarden bevatten, zoals bedragen, tijd en data.
Lagere updatekosten voor gefilterde indexen zijn het meest merkbaar wanneer het aantal rijen in de index klein is vergeleken met een volledige tabelindex. Als de gefilterde index de meeste rijen in de tabel bevat, kan het meer kosten om te onderhouden dan een volledige tabelindex. In dit geval moet u een volledige tabelindex gebruiken in plaats van een gefilterde index.
Gefilterde indexen worden gedefinieerd in één tabel en ondersteunen alleen eenvoudige vergelijkingsoperatoren. Als u een filterexpressie met complexe logica of verwijzingen naar meerdere tabellen nodig hebt, moet u een geïndexeerde berekende kolom of een geïndexeerde weergave maken.
Overwegingen bij het ontwerpen van gefilterde indexen
Om effectieve gefilterde indexen te ontwerpen, is het belangrijk om te begrijpen welke query's uw toepassing gebruikt en hoe deze betrekking hebben op subsets van uw gegevens. Enkele voorbeelden van gegevens met goed gedefinieerde subsets zijn kolommen met veel NULL's, kolommen met heterogene categorieën waarden en kolommen met afzonderlijke waardenbereiken.
De volgende ontwerpoverwegingen geven verschillende scenario's voor wanneer een gefilterde index voordelen kan bieden ten opzichte van indexen in volledige tabellen.
Gefilterde indexen voor subsets van gegevens
Wanneer een kolom slechts enkele relevante waarden voor query's bevat, kunt u een gefilterde index maken voor de subset met waarden. Als de kolom bijvoorbeeld voornamelijk NULL is en de query alleen niet-NULL-waarden vereist, kunt u een gefilterde index maken die de niet-NULL-rijen bevat.
De voorbeelddatabase AdventureWorks heeft bijvoorbeeld een Production.BillOfMaterials tabel met 2.679 rijen. De EndDate kolom bevat slechts 199 rijen die een niet-NULL-waarde bevatten en de andere 2480 rijen NULL bevatten. De volgende gefilterde index bevat query's die de kolommen retourneren die zijn gedefinieerd in de index en waarvoor alleen rijen met een niet-NULL-waarde zijn vereist.EndDate
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
De gefilterde index FIBillOfMaterialsWithEndDate is geldig voor de volgende query.
Geef het geschatte uitvoeringsplan weer om te bepalen of de queryoptimalisatie de gefilterde index heeft gebruikt.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
Zie Gefilterde indexen maken voor meer informatie over het maken van gefilterde indexen en het definiëren van de gefilterde indexpredicaatexpressie.
Gefilterde indexen voor heterogene gegevens
Wanneer een tabel heterogene gegevensrijen bevat, kunt u een gefilterde index maken voor een of meer gegevenscategorieën.
De producten die in de Production.Product tabel worden vermeld, worden bijvoorbeeld toegewezen aan een ProductSubcategoryID, die op zijn beurt gekoppeld zijn aan de productcategorieën Fietsen, Onderdelen, Kleding of Accessoires. Deze categorieën zijn heterogene omdat de kolomwaarden in de Production.Product tabel niet nauw zijn gecorreleerd. De kolommenColor, ReorderPoint, ListPrice, , Weighten ClassStylehebben bijvoorbeeld unieke kenmerken voor elke productcategorie. Stel dat er veelgestelde vragen zijn voor accessoires, die subcategorieën hebben tussen 27 en 36 inclusief. U kunt de prestaties van query's voor accessoires verbeteren door een gefilterde index te maken voor de subcategorieën accessoires, zoals wordt weergegeven in het volgende voorbeeld.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
De gefilterde index FIProductAccessories dekt de volgende query omdat de queryresultaten zijn opgenomen in de index en het queryplan geen toegang nodig heeft tot de basistabel. De querypredicaatexpressie ProductSubcategoryID = 33 is bijvoorbeeld een subset van het gefilterde indexpredicaat ProductSubcategoryID >= 27 en ProductSubcategoryID <= 36de ProductSubcategoryID kolommen ListPrice in het querypredicaat zijn beide sleutelkolommen in de index en de naam wordt opgeslagen in het bladniveau van de index als een opgenomen kolom.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Sleutel en opgenomen kolommen in gefilterde indexen
Het is een best practice om een klein aantal kolommen toe te voegen in een gefilterde indexdefinitie, alleen als dat nodig is voor de queryoptimalisatie om de gefilterde index voor het queryuitvoeringsplan te kiezen. De queryoptimalisatie kan een gefilterde index voor de query kiezen, ongeacht of deze wel of niet betrekking heeft op de query. De query-optimizer zal waarschijnlijker een gefilterde index kiezen als deze de query dekt.
In sommige gevallen dekt een gefilterde index de query zonder dat de kolommen in de gefilterde indexexpressie zijn opgenomen als sleutel of als opgenomen kolommen in de gefilterde indexdefinitie. In de volgende richtlijnen wordt uitgelegd wanneer een kolom in de gefilterde indexexpressie een sleutel of kolom in de gefilterde indexdefinitie moet zijn. De voorbeelden verwijzen naar de gefilterde index, FIBillOfMaterialsWithEndDate die eerder is gemaakt.
Een kolom in de gefilterde indexexpressie hoeft geen sleutel of opgenomen kolom in de gefilterde indexdefinitie te zijn als de gefilterde indexexpressie gelijk is aan het querypredicaat en de query retourneert niet de kolom in de gefilterde indexexpressie met de queryresultaten. Behandelt bijvoorbeeld FIBillOfMaterialsWithEndDate de volgende query omdat het querypredicaat gelijk is aan de filterexpressie en EndDate niet wordt geretourneerd met de queryresultaten. De FIBillOfMaterialsWithEndDate-index heeft EndDate niet nodig als sleutel of opgenomen kolom in de definitie van de gefilterde index.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Een kolom in de gefilterde indexexpressie moet een sleutel of een opgenomen kolom in de gefilterde indexdefinitie zijn als het querypredicaat gebruikmaakt van de kolom in een vergelijking die niet gelijk is aan de gefilterde indexexpressie. Is bijvoorbeeld FIBillOfMaterialsWithEndDate geldig voor de volgende query omdat hiermee een subset rijen uit de gefilterde index wordt geselecteerd. Deze query wordt echter niet gedekt omdat EndDate wordt gebruikt in de vergelijking EndDate > '20040101', wat niet overeenkomt met de gefilterde indexexpressie. De queryprocessor kan deze query niet uitvoeren zonder de waarden van EndDate.
EndDate Daarom moet dit een sleutel zijn of een opgenomen kolom in de gefilterde indexdefinitie.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Een kolom in de gefilterde indexexpressie moet een sleutel of een opgenomen kolom in de gefilterde indexdefinitie zijn als de kolom zich in de resultatenset van de query bevindt. Een voorbeeld hiervan is dat FIBillOfMaterialsWithEndDate de volgende query niet dekt, omdat in de queryresultaten de EndDate kolom wordt geretourneerd.
EndDate Daarom moet dit een sleutel zijn of een opgenomen kolom in de gefilterde indexdefinitie.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
De geclusterde indexsleutel van de tabel hoeft geen sleutel of opgenomen kolom te zijn in de gefilterde indexdefinitie. De geclusterde indexsleutel wordt automatisch opgenomen in alle niet-geclusterde indexen, inclusief gefilterde indexen.
Gegevensconversieoperators in het filterpredicaat
Als de vergelijkingsoperator die is opgegeven in de gefilterde indexexpressie van de gefilterde index resulteert in een impliciete of expliciete gegevensconversie, treedt er een fout op als de conversie aan de linkerkant van een vergelijkingsoperator plaatsvindt. Een oplossing is het schrijven van de gefilterde indexexpressie met de operator voor gegevensconversie (CAST of CONVERT) aan de rechterkant van de vergelijkingsoperator.
In het volgende voorbeeld wordt een tabel gemaakt met kolommen met verschillende gegevenstypen.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
In de volgende gefilterde indexdefinitie wordt de kolom b impliciet geconverteerd naar een gegevenstype geheel getal om deze te vergelijken met de constante 1. Hiermee wordt foutbericht 10611 gegenereerd omdat de conversie plaatsvindt aan de linkerkant van de operator in het gefilterde predicaat.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
De oplossing is om de constante aan de rechterkant te converteren naar hetzelfde type als kolom b, zoals te zien is in het volgende voorbeeld:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Het verplaatsen van de gegevensconversie van de linkerkant naar de rechterkant van een vergelijkingsoperator kan de betekenis van de conversie wijzigen. In het vorige voorbeeld, toen de operator aan de rechterkant werd toegevoegd, is de CONVERT vergelijking gewijzigd van een int-vergelijking met een varbinaire vergelijking.
Columnstore-indexarchitectuur
Een columnstore-index is een technologie voor het opslaan, ophalen en beheren van gegevens met behulp van een columnaire gegevensindeling, columnstore genoemd. Zie Columnstore-indexen voor meer informatie: overzicht.
Voor versie-informatie en om erachter te komen wat er nieuw is, gaat u naar Wat is er nieuw in columnstore-indexen.
Als u deze basisprincipes kent, is het eenvoudiger om andere columnstore-artikelen te begrijpen die uitleggen hoe u deze technologie effectief kunt gebruiken.
Gegevensopslag maakt gebruik van columnstore en rowstore
Bij het bespreken van columnstore-indexen gebruiken we de termen rowstore en columnstore om de indeling voor de gegevensopslag te benadrukken. Columnstore-indexen maken gebruik van beide typen opslag.

Een columnstore is gegevens die logisch zijn ingedeeld als een tabel met rijen en kolommen, en fysiek zijn opgeslagen in een gegevensindeling die in kolomvorm is opgeslagen.
In een columnstore-index worden de meeste gegevens fysiek opgeslagen in kolomopslagindeling. In columnstore-indeling worden de gegevens gecomprimeerd en niet-gecomprimeerd in de vorm van kolommen. U hoeft geen andere waarden in elke rij op te heffen die niet door de query worden aangevraagd. Hierdoor kunt u snel een hele kolom van een grote tabel scannen.
Een rijopslag is gegevens die logisch zijn ingedeeld als een tabel met rijen en kolommen en vervolgens fysiek zijn opgeslagen in een gegevensindeling die in rijvorm wordt opgeslagen. Dit is de traditionele manier om relationele tabelgegevens op te slaan, zoals een geclusterde B+-structuurindex of een heap.
Een columnstore-index slaat ook fysiek enkele rijen op in een rijstore-indeling, een deltastore genoemd. De deltastore, ook wel deltarijgroepen genoemd, is een bewaringsplaats voor rijen die niet talrijk genoeg zijn om geschikt te zijn voor compressie in de columnstore. Elke deltarijgroep wordt geïmplementeerd als een geclusterde B+-boomindex, die een rowstore vertegenwoordigt.
Bewerkingen worden uitgevoerd op rijgroepen en kolomsegmenten
De columnstore-index groepeert rijen in beheerbare eenheden. Elk van deze eenheden wordt een rijgroep genoemd. Voor de beste prestaties is het aantal rijen in een rijgroep groot genoeg om de compressieverhouding te verbeteren en klein genoeg om te profiteren van geheugenbewerkingen.
De columnstore-index voert bijvoorbeeld deze bewerkingen uit op rijgroepen:
Comprimeert rijgroepen in de columnstore. Compressie wordt uitgevoerd op elk kolomsegment binnen een rijgroep.
Hiermee worden rijgroepen samengevoegd tijdens een
ALTER INDEX ... REORGANIZEbewerking, inclusief het verwijderen van verwijderde gegevens.Maakt alle rijgroepen opnieuw tijdens een
ALTER INDEX ... REBUILDbewerking.Rapporten over de status en fragmentatie van rijgroepen in de dynamische beheerweergaven (DMV's).
De deltastore bestaat uit een of meer rijgroepen die deltarijgroepen worden genoemd. Elke deltarijgroep is een geclusterde B+-boom index waarin kleine bulkloads en invoegingen worden opgeslagen totdat de rijgroep 1.048.576 rijen bevat. Op dat moment comprimeert een proces dat de tuple-mover wordt genoemd automatisch een gesloten rijgroep naar de kolomstore.
Voor meer informatie over de statussen van rijgroepen, zie sys.dm_db_column_store_row_group_physical_stats.
Tip
Als u te veel kleine rijengroepen hebt, wordt de kwaliteit van de columnstore-index verlaagd. Met een herorganisatiebewerking worden kleinere rijgroepen samengevoegd, volgens een intern drempelwaardebeleid waarmee wordt bepaald hoe verwijderde rijen worden verwijderd en de gecomprimeerde rijgroepen worden gecombineerd. Na een samenvoeging wordt de indexkwaliteit verbeterd.
In SQL Server 2019 (15.x) en latere versies wordt de tuple-mover geholpen door een taak voor samenvoeging op de achtergrond waarmee automatisch kleinere open deltarijgroepen worden gecomprimeerd die al enige tijd bestaan, zoals bepaald door een interne drempelwaarde, of worden gecomprimeerde rijgroepen samengevoegd waaruit een groot aantal rijen is verwijderd.
Elke kolom heeft een aantal waarden in elke rijgroep. Deze waarden worden kolomsegmenten genoemd. Elke rijgroep bevat één kolomsegment voor elke kolom in de tabel. Elke kolom heeft één kolomsegment in elke rijgroep.

Wanneer de columnstore-index een rijgroep comprimeert, wordt elk kolomsegment afzonderlijk gecomprimeerd. Als u een hele kolom wilt opheffen, hoeft de columnstore-index slechts één kolomsegment uit elke rijgroep op te heffen.
Kleine ladingen en invoeringen gaan naar de deltastore
Een columnstore-index verbetert de columnstore-compressie en prestaties door ten minste 102.400 rijen tegelijk te comprimeren in de columnstore-index. Om rijen in bulk te comprimeren, verzamelt de columnstore-index kleine ladingen en voegt deze in de deltastore in. De deltastore-bewerkingen worden op de achtergrond verwerkt. Als u queryresultaten wilt retourneren, combineert de geclusterde columnstore-index queryresultaten uit zowel de columnstore als de deltastore.
Rijen gaan naar de DeltaStore wanneer dit het volgende is:
Ingevoegd met de
INSERT INTO ... VALUESverklaring.Aan het einde van een bulkverwerking en hun aantal is minder dan 102.400.
Updated. Elke update wordt geïmplementeerd als een verwijderbewerking en een invoegbewerking.
In de deltastore wordt ook een lijst met id's opgeslagen voor verwijderde rijen die zijn gemarkeerd als verwijderd, maar nog niet fysiek zijn verwijderd uit de columnstore.
Wanneer deltarijgroepen vol zijn, worden ze gecomprimeerd in de columnstore
Geclusterde columnstore-indexen verzamelen maximaal 1.048.576 rijen in elke deltarijgroep voordat de rijgroep in de columnstore wordt gecomprimeerd. Dit verbetert de compressie van de columnstore-index. Wanneer een deltarijgroep het maximum aantal rijen bereikt, gaat deze van de OPEN-status naar de CLOSED-status over. Een achtergrondproces met de naam tuple-mover controleert op gesloten rijgroepen. Als in het proces een gesloten rijgroep wordt gevonden, wordt de rijgroep gecomprimeerd en opgeslagen in de columnstore.
Wanneer een deltarijgroep is gecomprimeerd, gaat de bestaande deltarijgroep over naar toestand TOMBSTONE, die later door de tuple-mover wordt verwijderd wanneer er geen verwijzingen meer naar zijn. De nieuwe gecomprimeerde rijgroep wordt gemarkeerd als COMPRESSED.
Voor meer informatie over de statussen van rijgroepen, zie sys.dm_db_column_store_row_group_physical_stats.
U kunt deltarijgroepen in de columnstore afdwingen door ALTER INDEX te gebruiken om de index opnieuw op te bouwen of te herorganiseren. Als er geheugendruk is tijdens de compressie, kan de columnstore-index het aantal rijen in de gecomprimeerde rijgroep verminderen.
Elke tabelpartitie heeft zijn eigen rijgroepen en deltarijgroepen
Het concept van partitioneren is hetzelfde in een geclusterde index, een heap en een columnstore-index. Het partitioneren van een tabel verdeelt de tabel in kleinere groepen rijen op basis van een bereik van kolomwaarden. Het wordt vaak gebruikt voor het beheren van de gegevens. U kunt bijvoorbeeld een partitie maken voor elk jaar gegevens en vervolgens partitiewisseling toepassen om oude gegevens naar goedkopere opslag te archiveren.
Rijgroepen worden altijd gedefinieerd binnen een tabelpartitie. Wanneer een columnstore-index wordt gepartitioneerd, heeft elke partitie zijn eigen gecomprimeerde rijgroepen en deltarijgroepen. Een niet-gepartitioneerde tabel bevat één partitie.
Tip
Overweeg om tabelpartitionering te gebruiken als u gegevens uit de columnstore wilt verwijderen. Het uitschakelen en afkappen van partities die niet meer nodig zijn, is een efficiënte strategie om gegevens te verwijderen zonder fragmentatie in de columnstore te introduceren.
Elke partitie kan meerdere deltarijgroepen hebben
Elke partitie kan meer dan één deltarijgroep hebben. Wanneer de columnstore-index gegevens moet toevoegen aan een deltarijgroep en de delta-rijgroep door een andere transactie wordt vergrendeld, probeert de columnstore-index een vergrendeling op een andere deltarijgroep te verkrijgen. Als er geen deltarijgroepen beschikbaar zijn, maakt de columnstore-index een nieuwe deltarijgroep. Een tabel met 10 partities kan bijvoorbeeld eenvoudig 20 of meer deltarijgroepen hebben.
Columnstore- en rowstore-indexen combineren in dezelfde tabel
Een niet-geclusterde index bevat een kopie van een deel of alle rijen en kolommen in de onderliggende tabel. De index wordt gedefinieerd als een of meer kolommen van de tabel en heeft een optionele voorwaarde waarmee de rijen worden gefilterd.
U kunt een updatable niet-geclusterde columnstore-index maken in een rowstore-tabel. In de columnstore-index wordt een kopie van de gegevens opgeslagen, zodat u extra opslagruimte nodig hebt. De gegevens in de columnstore-index worden echter gecomprimeerd tot een veel kleinere grootte dan nodig is voor de rowstore-tabel. Hierdoor kunt u tegelijkertijd analyses uitvoeren op de columnstore-index en OLTP-workloads in de rowstore-index. De columnstore wordt bijgewerkt wanneer gegevens in de tabel rowstore worden gewijzigd, dus beide indexen werken met dezelfde gegevens.
Een rowstore-tabel kan één niet-geclusterde columnstore-index hebben. Zie Columnstore-indexen - ontwerprichtlijnen voor meer informatie.
U kunt een of meer niet-geclusterde rowstore-indexen hebben in een geclusterde columnstore-tabel. Hierdoor kunt u efficiënte tabelzoekopdrachten uitvoeren op de onderliggende columnstore. Er zijn ook andere opties beschikbaar. U kunt bijvoorbeeld uniekheid afdwingen met behulp van een UNIQUE beperking in de tabel rowstore. Wanneer een niet-unieke waarde niet kan worden ingevoegd in de rowstore-tabel, voegt de database-engine de waarde ook niet in de columnstore in.
Prestatieoverwegingen voor niet-geclusterde columnstore
De niet-geclusterde columnstore-indexdefinitie ondersteunt het gebruik van een gefilterde voorwaarde. Als u het prestatie-effect van het toevoegen van een columnstore-index wilt minimaliseren, gebruikt u een filterexpressie om alleen een niet-geclusterde columnstore-index te maken op de subset van de gegevens die vereist zijn voor analyse.
Een tabel die is geoptimaliseerd voor geheugen kan één columnstore-index hebben. U kunt deze maken wanneer de tabel wordt gemaakt of later toevoegen met ALTER TABLE.
Voor meer informatie, zie Columnstore-indexen - queryprestaties.
Ontwerprichtlijnen voor hash-indexen die zijn geoptimaliseerd voor geheugen
Wanneer uIn-Memory OLTP gebruikt, moeten alle tabellen die zijn geoptimaliseerd voor geheugen ten minste één index hebben. Voor een tabel die is geoptimaliseerd voor geheugen, is elke index ook geoptimaliseerd voor geheugen. Hash-indexen zijn een van de mogelijke indextypen in een tabel die is geoptimaliseerd voor geheugen. Zie Indexen van Memory-Optimized tabellen voor meer informatie.
Architectuur voor hash-index geoptimaliseerd voor geheugen
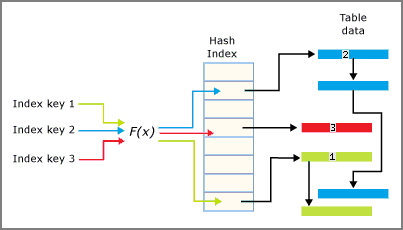
Een hash-index bestaat uit een matrix met aanwijzers en elk element van de matrix wordt een hash-bucket genoemd.
- Elke bucket is 8 bytes, die worden gebruikt voor het opslaan van het geheugenadres van een koppelingslijst met sleutelvermeldingen.
- Elke vermelding is een waarde voor een indexsleutel, plus het adres van de bijbehorende rij in de onderliggende tabel die is geoptimaliseerd voor geheugen.
- Elk item verwijst naar de volgende vermelding in een koppelingslijst met vermeldingen, allemaal gekoppeld aan de huidige bucket.
Het aantal buckets moet worden opgegeven tijdens het maken van de index:
- Hoe lager de verhouding tussen buckets en tabelrijen of tussen buckets en afzonderlijke waarden, hoe langer de gemiddelde lijst met bucketkoppelingen is.
- Korte koppelingslijsten worden sneller uitgevoerd dan lange koppelingslijsten.
- Het maximum aantal buckets in hash-indexen is 1.073.741.824.
De hash-functie wordt toegepast op de indexsleutelkolommen en het resultaat van de functie bepaalt in welke bucket die sleutel valt. Elke bucket heeft een aanwijzer naar rijen waarvan de gehashte sleutelwaarden aan die bucket zijn toegewezen.
De hashfunctie die wordt gebruikt voor hash-indexen heeft de volgende kenmerken:
- De database-engine heeft één hash-functie die wordt gebruikt voor alle hash-indexen.
- De hash-functie is deterministisch. Dezelfde waarde voor de invoersleutel wordt altijd toegewezen aan dezelfde bucket in de hash-index.
- Er kunnen meerdere indexsleutels worden toegewezen aan dezelfde hash-bucket.
- De hash-functie is evenwichtig, wat betekent dat de verdeling van indexsleutelwaarden voor hash-buckets doorgaans een Poisson- of klokcurveverdeling volgt, niet een platte lineaire verdeling.
- Poisson-distributie is geen gelijkmatige verdeling. Indexsleutelwaarden worden niet gelijkmatig verdeeld in de hash-buckets.
- Als twee indexsleutels zijn toegewezen aan dezelfde hash-bucket, is er sprake van een hash-botsing. Een groot aantal hashconflicten kan invloed hebben op de prestaties van leesbewerkingen. Een realistisch doel is dat 30 procent van de buckets twee verschillende sleutelwaarden bevat.
De interactie tussen de hash-index en de buckets wordt samengevat in de volgende afbeelding.
Het aantal hash-indexbuckets configureren
Het aantal hash-indexbuckets wordt opgegeven tijdens het maken van de index en kan worden gewijzigd met behulp van de ALTER TABLE...ALTER INDEX REBUILD syntaxis.
In de meeste gevallen moet het aantal buckets tussen 1 en 2 keer het aantal afzonderlijke waarden in de indexsleutel zijn.
Mogelijk kunt u niet altijd voorspellen hoeveel waarden een bepaalde indexsleutel heeft. Prestaties zijn meestal nog steeds goed als de BUCKET_COUNT waarde binnen 10 keer van het werkelijke aantal sleutelwaarden ligt en overschatting over het algemeen beter is dan onderschatten.
Te weinig buckets kunnen de volgende nadelen hebben:
- Meer hashconflicten bij verschillende sleutelwaarden.
- Elke afzonderlijke waarde wordt gedwongen om dezelfde bucket te delen met een andere afzonderlijke waarde.
- De gemiddelde ketenlengte per bucket groeit.
- Hoe langer de bucketketen, hoe langzamer de snelheid van het zoeken naar gelijkheid in de index.
Te veel buckets kunnen de volgende nadelen hebben:
- Te hoog aantal buckets kan leiden tot meer lege buckets.
- Lege buckets zijn van invloed op de prestaties van volledige indexscans. Als scans regelmatig worden uitgevoerd, kunt u overwegen het aantal buckets dicht bij het aantal afzonderlijke indexsleutelwaarden te kiezen.
- Lege buckets gebruiken geheugen, hoewel elke bucket slechts 8 bytes gebruikt.
Note
Het toevoegen van meer buckets doet niets om de koppeling van items die een dubbele waarde delen te verminderen. De snelheid van waardeduplicatie wordt gebruikt om te bepalen of een hash-index of een niet-geclusterde index het juiste indextype is, niet om het aantal buckets te berekenen.
Prestatieoverwegingen voor hash-indexen
De prestaties van een hash-index zijn:
- Uitstekend wanneer het predicaat in de
WHEREcomponent een exacte waarde voor elke kolom in de hash-indexsleutel opgeeft. Een hash-index wordt teruggezet naar een scan op basis van een ongelijkheidspredicaat. - Slecht wanneer het predicaat in de
WHEREclausule zoekt naar een bereik van waarden in de indexsleutel. - Slecht wanneer het predicaat in de
WHEREcomponent één specifieke waarde voor de eerste kolom van een sleutel voor de hash-index van twee kolommen bevat, maar geen waarde opgeeft voor andere kolommen van de sleutel.
Tip
Het predicaat moet alle kolommen in de hash-indexsleutel bevatten. De hash-index vereist dat de volledige sleutel nodig is om toegang tot de index te krijgen.
Als een hash-index wordt gebruikt en het aantal unieke indexsleutels meer dan 100 keer kleiner is dan het aantal rijen, kunt u overwegen om te verhogen tot een groter aantal buckets om grote rijketens te voorkomen of een niet-geclusterde index te gebruiken.
Een hash-index maken
Overweeg bij het maken van een hash-index het volgende:
- Een hash-index kan alleen bestaan in een tabel die is geoptimaliseerd voor geheugen. Deze kan niet bestaan in een tabel op basis van een schijf.
- Een hash-index is standaard niet-unique, maar kan worden gedeclareerd als uniek.
In het volgende voorbeeld wordt een unieke hash-index gemaakt:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Rijversies en garbagecollection in tabellen die zijn geoptimaliseerd voor geheugen
Wanneer een rij wordt beïnvloed door een UPDATE instructie, wordt in een tabel die is geoptimaliseerd voor geheugen, een bijgewerkte versie van de rij gemaakt. Tijdens de updatetransactie kunnen andere sessies mogelijk de oudere versie van de rij inzien en zodoende een prestatievermindering vermijden die gepaard gaat met een rijvergrendeling.
De hash-index kan ook verschillende versies van de vermeldingen hebben om tegemoet te komen aan de update.
Later wanneer de oudere versies niet meer nodig zijn, doorkruist een GC-thread (garbagecollection) de buckets en de bijbehorende koppelingslijsten om oude items op te schonen. De GC-thread presteert beter als de lengte van de koppelingslijstketen kort is. Zie In-Memory OLTP Garbagecollection voor meer informatie.
Richtlijnen voor het ontwerpen van niet-geclusterde indexen die zijn geoptimaliseerd voor geheugen
Naast hash-indexen zijn niet-geclusterde indexen de andere mogelijke indextypen in een tabel die is geoptimaliseerd voor geheugen. Zie Indexen van Memory-Optimized tabellen voor meer informatie.
Niet-geclusterde indexarchitectuur geoptimaliseerd voor geheugen
Niet-geclusterde indexen voor tabellen die zijn geoptimaliseerd voor geheugen, worden geïmplementeerd met behulp van een gegevensstructuur, een BW-structuur, die oorspronkelijk is ingericht en beschreven door Microsoft Research in 2011. Een Bw-boom is een slot- en sluitingsvrije variatie van een B-boom. Zie The Bw-tree: A B-tree for New Hardware Platforms voor meer informatie.
Op hoog niveau kan de Bw-structuur worden begrepen als een kaart van pagina's die zijn ingedeeld op pagina-id (PidMap), een faciliteit voor het toewijzen en hergebruiken van pagina-id's (PidAlloc) en een set pagina's die zijn gekoppeld aan de paginakaart en aan elkaar. Deze drie subonderdelen op hoog niveau vormen de basis interne structuur van een Bw-boom.
De structuur is vergelijkbaar met een normale B-structuur in de zin dat elke pagina een set sleutelwaarden heeft die zijn gerangschikt en dat er niveaus in de index zijn die elk verwijzen naar een lager niveau en de bladniveaus verwijzen naar een gegevensrij. Er zijn echter verschillende verschillen.
Net als bij hash-indexen kunnen meerdere gegevensrijen worden gekoppeld om versiebeheer te ondersteunen. De paginapointers tussen de niveaus zijn logische pagina-id's, die naar posities verwijzen in een tabel voor paginatoewijzing, dat op zijn beurt het fysieke adres van elke pagina bevat.
Er zijn geen directe updates van indexpagina's. Hiervoor worden nieuwe deltapagina's geïntroduceerd.
- Er is geen vergrendeling nodig voor pagina-updates.
- Indexpagina's zijn geen vaste grootte.
De sleutelwaarde op elke pagina op niet-paginaniveau is de hoogste waarde die het onderliggende element waarnaar wordt verwezen, en elke rij bevat ook de logische pagina-id van die pagina. Op pagina's op niveau van het blad, bevat het samen met de sleutelwaarde het fysieke adres van de gegevensrij.
Puntzoekacties zijn vergelijkbaar met B-trees, behalve dat omdat pagina's in slechts één richting zijn gekoppeld, de database-engine de juiste paginapointers volgt, waarbij elke niet-secundaire pagina de hoogste waarde van het onderliggende item heeft in plaats van de laagste waarde zoals in een B-boomstructuur.
Als een pagina op bladniveau moet worden gewijzigd, wijzigt de database-engine de pagina zelf niet. In plaats daarvan maakt de database-engine een deltarecord die de wijziging beschrijft en deze toevoegt aan de vorige pagina. Vervolgens wordt het adres van de paginakaarttabel voor die vorige pagina bijgewerkt naar het adres van de deltarecord dat nu het fysieke adres voor deze pagina wordt.
Er zijn drie verschillende bewerkingen vereist voor het beheren van de structuur van een Bw-boom: consolidatie, splitsing en samenvoeging.
Deltaconsolidatie
Een lange keten van deltarecords kan uiteindelijk de zoekprestatie verslechteren, omdat hiervoor een lange ketendoorzoeking nodig kan zijn bij het doorzoeken van een index. Als er een nieuwe deltarecord wordt toegevoegd aan een keten met al 16 elementen, worden de wijzigingen in de deltarecords samengevoegd in de indexpagina waarnaar wordt verwezen en wordt de pagina vervolgens opnieuw opgebouwd, inclusief de wijzigingen die worden aangegeven door de nieuwe deltarecord die de consolidatie heeft geactiveerd. De zojuist opnieuw opgebouwde pagina heeft dezelfde pagina-id, maar een nieuw geheugenadres.

Pagina splitsen
Een indexpagina in Bw-tree groeit naar behoefte vanaf het opslaan van één rij tot het opslaan van maximaal 8 kB. Zodra de indexpagina is uitgebreid tot 8 kB, zorgt een nieuwe invoeging van één rij ervoor dat de indexpagina wordt gesplitst. Voor een interne pagina betekent dit dat wanneer er geen ruimte meer is om een andere sleutelwaarde en aanwijzer toe te voegen, en voor een bladpagina betekent dit dat de rij te groot is om op de pagina te passen zodra alle deltarecords zijn opgenomen. De informatie over statistieken in de paginakoptekst voor een bladpagina houdt bij hoeveel ruimte er nodig is om de deltarecords samen te voegen. Deze informatie wordt aangepast wanneer elke nieuwe deltarecord wordt toegevoegd.
Er wordt een splitsbewerking uitgevoerd in twee atomische stappen. In het volgende diagram wordt ervan uitgegaan dat een bladpagina een splitsing dwingt omdat een sleutel met waarde 5 wordt ingevoegd en er een niet-leaf pagina bestaat die verwijst naar het einde van de huidige pagina op bladniveau (sleutelwaarde 4).

Stap 1: Wijs twee nieuwe pagina's P1 toe en P2splits de rijen van de oude P1 pagina op deze nieuwe pagina's, inclusief de zojuist ingevoegde rij. Er wordt een nieuwe sleuf in de tabel paginatoewijzing gebruikt om het fysieke adres van de pagina P2 op te slaan. Pagina's P1 en P2 zijn nog niet toegankelijk voor gelijktijdige bewerkingen. Daarnaast wordt de logische aanwijzer van P1 naar P2 ingesteld. Werk vervolgens in één atomische stap de tabel voor paginatoewijzing bij om de aanwijzer van oud P1 naar nieuw P1te wijzigen.
Stap 2: De niet-leaf-pagina verwijst naar P1, maar er is geen directe pointer van een niet-leaf-pagina naar P2.
P2 is alleen bereikbaar via P1. Als u een aanwijzer wilt maken van een niet-bladzijde pagina naar P2, wijst u een nieuwe niet-bladzijde pagina (interne indexpagina) toe, kopieert u alle rijen van de oude niet-bladzijde pagina, en voegt u een nieuwe rij toe om naar P2 te verwijzen. Zodra dit is gebeurd, werkt u in één atomische stap de paginatoewijzingstabel bij om de wijzer van de oude niet-bladzijde pagina naar de nieuwe niet-bladzijde pagina te veranderen.
Pagina samenvoegen
Wanneer een DELETE bewerking resulteert in een pagina met minder dan 10 procent van het maximale paginaformaat (8 kB) of met één rij erop, wordt die pagina samengevoegd met een aaneengesloten pagina.
Wanneer een rij van een pagina wordt verwijderd, wordt er een deltarecord voor de verwijdering toegevoegd. Daarnaast wordt een controle uitgevoerd om te bepalen of de indexpagina (niet-bladzijde pagina) in aanmerking komt voor samenvoeging. Hiermee wordt gecontroleerd of de resterende ruimte na het verwijderen van de rij kleiner is dan 10 procent van het maximale paginaformaat. Als deze in aanmerking komt, wordt de samenvoeging uitgevoerd in drie atomische stappen.
In de volgende afbeelding wordt ervan uitgegaan dat met een DELETE bewerking de sleutelwaarde 10 wordt verwijderd.

Stap 1: Er wordt een deltapagina gemaakt die de sleutelwaarde 10 (blauwe driehoek) vertegenwoordigt en de verwijzing in de niet-blad pagina Pp1 wordt ingesteld op de nieuwe deltapagina. Daarnaast wordt er een speciale samenvoegings-deltapagina (groene driehoek) gemaakt en gekoppeld om naar de deltapagina te verwijzen. In deze fase zijn beide pagina's (deltapagina en samenvoegingspagina) niet zichtbaar voor een gelijktijdige transactie. In één atomische stap wordt de aanwijzer naar de pagina P1 op bladniveau in de paginatoewijzingstabel bijgewerkt zodat deze verwijst naar de pagina merge-delta. Na deze stap verwijst de vermelding voor de sleutelwaarde 10 in Pp1 nu naar de pagina merge-delta.
Stap 2: De rij die sleutelwaarde 7 in de niet-bladzijdepagina Pp1 vertegenwoordigt, moet worden verwijderd. De vermelding voor sleutelwaarde 10 moet worden bijgewerkt zodat deze verwijst naar P1. Hiervoor wordt een nieuwe niet-bladzijde Pp2 toegewezen en worden alle rijen van Pp1 gekopieerd, met uitzondering van de rij die de sleutelwaarde 7 vertegenwoordigt; vervolgens wordt de rij voor sleutelwaarde 10 bijgewerkt zodat deze verwijst naar pagina P1. Zodra dit is gebeurd, wordt in één atomische stap de vermelding Pp1 van de paginatoewijzingstabel bijgewerkt zodat deze verwijst naar Pp2.
Pp1 is niet meer bereikbaar.
Stap 3: De pagina's P2 op bladniveau en P1 worden samengevoegd en de deltapagina's verwijderd. Hiervoor wordt een nieuwe pagina P3 toegewezen en worden de rijen van P2 en P1 worden samengevoegd en worden de deltapaginawijzigingen opgenomen in de nieuwe P3pagina. In één atomische stap wordt de vermelding in de paginatoewijzingstabel die naar pagina P1 verwijst, bijgewerkt om naar pagina P3 te verwijzen.
Prestatieoverwegingen voor niet-geclusterde indexen die zijn geoptimaliseerd voor geheugen
De prestaties van een niet-geclusterde index zijn beter dan met hash-indexen bij het uitvoeren van query's op een tabel die is geoptimaliseerd voor geheugen met ongelijkheidspredicaten.
Een kolom in een tabel die is geoptimaliseerd voor geheugen kan deel uitmaken van zowel een hash-index als een niet-geclusterde index.
Wanneer een sleutelkolom in een niet-geclusterde index veel dubbele waarden heeft, kunnen de prestaties afnemen voor updates, invoegingen en verwijderingen. Een manier om de prestaties in deze situatie te verbeteren, is door een kolom toe te voegen met een betere selectiviteit in de indexsleutel.
Indexmetagegevens
Als u indexmetagegevens zoals indexdefinities, eigenschappen en gegevensstatistieken wilt onderzoeken, gebruikt u de volgende systeemweergaven:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
De vorige weergaven zijn van toepassing op alle indextypen. Gebruik voor columnstore-indexen ook de volgende weergaven:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
Voor columnstore-indexen worden alle kolommen opgeslagen in de metagegevens als opgenomen kolommen. De columnstore-index heeft geen sleutelkolommen.
Voor indexen in tabellen die zijn geoptimaliseerd voor geheugen, gebruikt u bovendien de volgende weergaven:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Verwante inhoud
- MAAK INDEX AAN (Transact-SQL)
- Indexonderhoud optimaliseren om de queryprestaties te verbeteren en het resourceverbruik te verminderen
- gepartitioneerde tabellen en indexen
- Indexen voor Memory-Optimized tabellen
- Columnstore-indexen: overzicht
- Indexen voor berekende kolommen
- Niet-geclusterde indexen afstemmen met behulp van suggesties voor ontbrekende indexen