本文提供有关Microsoft SQL Server 查询花费过多时间(小时或天数)的问题的故障排除指南。
症状
本文重点介绍似乎在没有结束的情况下运行或编译的查询。 也就是说,其 CPU 使用率继续增加。 本文不适用于阻止或等待从未释放的资源的查询。 在这些情况下,CPU 使用率保持不变或仅略有更改。
重要
如果查询仍要继续运行,它最终可能会完成。 此过程可能需要几秒钟或几天时间。 在某些情况下,查询可能非常无休止,例如 WHILE 循环未退出时。 此处使用术语“永不结束”来描述对未完成的查询的感知。
原因
长时间运行(永不结束)查询的常见原因包括:
-
非常大的表上的嵌套循环 (NL) 联接: 由于 NL 联接的性质,联接包含大量行的表的查询可能会长时间运行。 有关详细信息,请参阅 “联接”。
- NL 联接的一个示例是使用
TOP或FASTEXISTS。 即使哈希或合并联接的速度可能更快,优化器也无法使用任一运算符,因为行目标。 - NL 联接的另一个示例是在查询中使用不相等联接谓词。 例如,
SELECT .. FROM tab1 AS a JOIN tab 2 AS b ON a.id > b.id。 优化器不能在此处使用合并或哈希联接。
- NL 联接的一个示例是使用
- 过时统计信息: 基于过时统计信息选取计划的查询可能不理想,需要很长时间才能运行。
- 无限循环: 使用 WHILE 循环的 T-SQL 查询可能编写不正确。 生成的代码永远不会离开循环并无休止地运行。 这些查询确实是永无止境的。 他们运行,直到他们被手动杀死。
- 具有许多联接和大型表的复杂查询: 涉及许多联接表的查询通常具有可能需要很长时间才能运行的复杂查询计划。 此方案在分析查询中很常见,这些查询不筛选出行,并且涉及大量表。
- 缺少索引: 如果对表使用适当的索引,查询可以更快地运行。 索引允许选择一部分数据以提供更快的访问。
解决方案
步骤 1:发现永不结束的查询
查找在系统上运行的永无止境的查询。 必须确定查询的执行时间长、等待时间长(停滞在瓶颈上)还是长时间编译。
1.1 运行诊断
在 SQL Server 实例上运行以下诊断查询,其中永不结束的查询处于活动状态:
DECLARE @cntr INT = 0
WHILE (@cntr < 3)
BEGIN
SELECT TOP 10 s.session_id,
r.status,
CAST(r.cpu_time / (1000 * 60.0) AS DECIMAL(10,2)) AS cpu_time_minutes,
CAST(r.total_elapsed_time / (1000 * 60.0) AS DECIMAL(10,2)) AS elapsed_minutes,
r.logical_reads,
r.wait_time,
r.wait_type,
r.wait_resource,
r.reads,
r.writes,
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count,
atrn.name as transaction_name,
atrn.transaction_id,
atrn.transaction_state
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id
CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
LEFT JOIN (sys.dm_tran_session_transactions AS stran
JOIN sys.dm_tran_active_transactions AS atrn
ON stran.transaction_id = atrn.transaction_id)
ON stran.session_id =s.session_id
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
SET @cntr = @cntr + 1
WAITFOR DELAY '00:00:05'
END
1.2 检查输出
有多种方案可能导致查询长时间运行:长时间执行、长时间等待和长时间编译。 有关查询运行速度缓慢的详细信息,请参阅 “正在运行”与“正在等待”:为什么查询速度较慢?
长时间执行
当收到类似于以下内容的输出时,本文中的故障排除步骤适用,其中 CPU 时间与已用时间成比例增加,且等待时间不长。
| session_id | 状态 | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | “正在运行” | 64.40 | 23.50 | 0 | 0.00 | Null |
如果查询具有以下条件,则查询会持续运行:
- CPU 时间增加
- 状态或
runningrunnable - 最短或零等待时间
- 无wait_type
在这种情况下,查询正在读取行、联接、处理结果、计算或格式设置。 这些活动都是 CPU 绑定的作。
注意
logical_reads在这种情况下,更改并不相关,因为某些 CPU 绑定的 T-SQL 请求(例如执行计算或WHILE循环)可能根本不执行任何逻辑读取。
如果慢查询满足这些条件,请专注于减少其运行时。 通常,减少运行时涉及通过应用索引、重写查询或更新统计信息来减少查询在其整个生命周期中必须处理的行数。 有关详细信息,请参阅 “解决方法 ”部分。
长时间等待时间
本文不适用于长时间等待方案。 在等待方案中,你可能会收到类似于以下示例的输出,因为会话正在等待资源,因此 CPU 使用率不会稍有更改或更改:
| session_id | 状态 | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | suspended | 0.03 | 4.20 | 50 | 4.10 | LCK_M_U |
等待类型指示会话正在等待资源。 长时间的等待时间和较长的等待时间表示会话正在等待此资源的大部分生存期。 Тhe 短 CPU 时间表示实际处理查询的时间很少。
若要排查由于等待而长时间 运行的查询,请参阅 SQL Server 中运行缓慢的查询疑难解答。
编译时间长
在极少数情况下,你可能会发现 CPU 使用率会随时间推移而持续增加,但不受查询执行驱动。 相反,过度长的编译(查询分析和编译)可能是原因。 在这些情况下,检查 transaction_name 输出列的值是否为 sqlsource_transform. 此事务名称指示编译。
步骤 2:手动收集诊断日志
确定系统上存在永不结束的查询后,可以收集查询的计划数据以进一步进行故障排除。 若要收集数据,请使用以下方法之一,具体取决于 SQL Server 的版本。
- SQL Server 2008 - SQL Server 2014 (早于 SP2)
- SQL Server 2014(高于 SP2)和 SQL Server 2016(早于 SP1)
- SQL Server 2016(高于 SP1)和 SQL Server 2017
- SQL Server 2019 及更高版本
若要使用 SQL Server Management Studio (SSMS)收集诊断数据,请执行以下步骤:
捕获估计的 查询执行计划 XML。
查看查询计划,了解数据是否显示导致速度缓慢的明显迹象。 典型指示的示例包括:
- 表或索引扫描(查看估计行)
- 由大型外部表数据集驱动的嵌套循环
- 在循环内侧具有大型分支的嵌套循环
- 表后台处理程序
-
SELECT列表中需要很长时间来处理每行的函数
如果查询随时运行得更快,则可以捕获“快速”运行(实际 XML 执行计划)来比较结果。
使用 SQL LogScout 捕获永不结束的查询
可以使用 SQL LogScout 在永不结束的查询运行时捕获日志。 通过以下命令使用 永不结束的查询方案 :
.\SQL_LogScout.ps1 -Scenario "NeverEndingQuery" -ServerName "SQLInstance"
注意
此日志捕获过程需要较长的查询消耗至少 60 秒的 CPU 时间。
SQL LogScout 为每个高 CPU 消耗查询捕获至少三个查询计划。 可以找到类似于 servername_datetime_NeverEnding_statistics_QueryPlansXml_Startup_sessionId_#.sqlplan.. 查看计划以确定长时间执行查询的原因时,可以在下一步中使用这些文件。
步骤 3:查看收集的计划
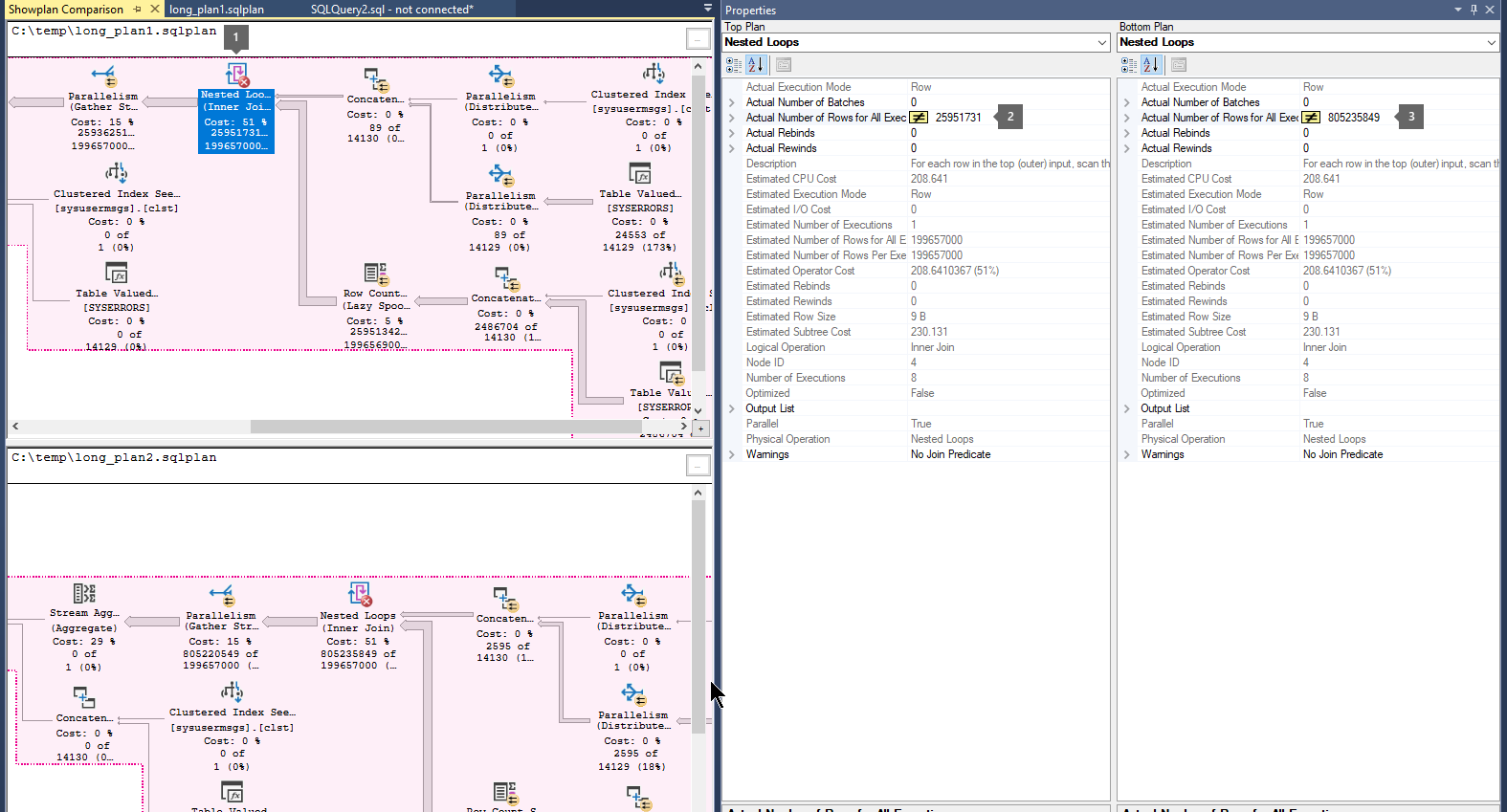
本部分讨论如何查看收集的数据。 它使用在 Microsoft SQL Server 2016 SP1 及更高版本中收集的多个 XML 查询计划(使用扩展 .sqlplan)。
按照以下步骤比较执行计划:
打开以前保存的查询执行计划文件(
.sqlplan)。右键单击执行计划的空白区域,然后选择“ 比较显示计划”。
选择要比较的第二个查询计划文件。
查找指示大量行在运算符之间流动的粗箭头。 然后,选择箭头前后的运算符,并比较两个计划中 的实际 行数。
比较第二和第三个计划,以了解行的最大流是否在同一运算符中发生。
例如:

步骤 4:解决方法
确保为查询中使用的表更新统计信息。
在查询计划中查找缺少的索引建议,并应用找到的任何建议。
简化查询:
尝试使用 查询提示 生成更好的计划:
-
HASH JOIN或MERGE JOIN提示 -
FORCE ORDER提示 -
FORCESEEK提示 RECOMPILE- USE
PLAN N'<xml_plan>'(如果有快速查询计划可以强制)
-
使用 查询存储 (QDS) 强制建立良好的已知计划(如果存在此类计划),如果 SQL Server 版本支持查询存储。