创建 Spark 群集
可以使用 Azure Databricks 工作区 UI 在 Azure Databricks 工作区中创建一个或多个群集。

创建群集时,可以指定配置设置,包括:
- 群集的名称。
-
群集模式,可以是:
- 标准:适用于需要多个工作器节点的单用户工作负荷。
- 高并发性:适用于多个用户将同时使用群集的工作负荷。
- 单节点:适用于小型工作负荷或测试,其中只需要单个工作器节点。
- 要用于群集的 Databricks Runtime 的版本;这决定了 Spark 的版本以及各个组件(如 Python、Scala)以及安装的其他组件。
- 用于群集中工作器节点的虚拟机(VM)的类型。
- 群集中最小和最大工作节点数。
- 用于群集中驱动程序节点的 VM 类型。
- 群集是否支持 自动缩放 以动态调整群集的大小。
- 群集在自动关闭之前可以保持空闲状态的时间。
Azure 如何管理群集资源
创建 Azure Databricks 工作区时, Databricks 设备 将部署为订阅中的 Azure 资源。 在工作区中创建群集时,可以指定用于驱动程序节点和辅助角色节点的虚拟机的类型和大小,以及其他一些配置选项,但 Azure Databricks 管理群集的所有其他方面。
Databricks 设备作为订阅中的 托管资源组 部署到 Azure 中。 此资源组包含群集的驱动程序和辅助角色 VM,以及其他必需的资源,包括虚拟网络、安全组和存储帐户。 群集的所有元数据(例如计划作业)都存储在 Azure 数据库中,用于容错异地复制。
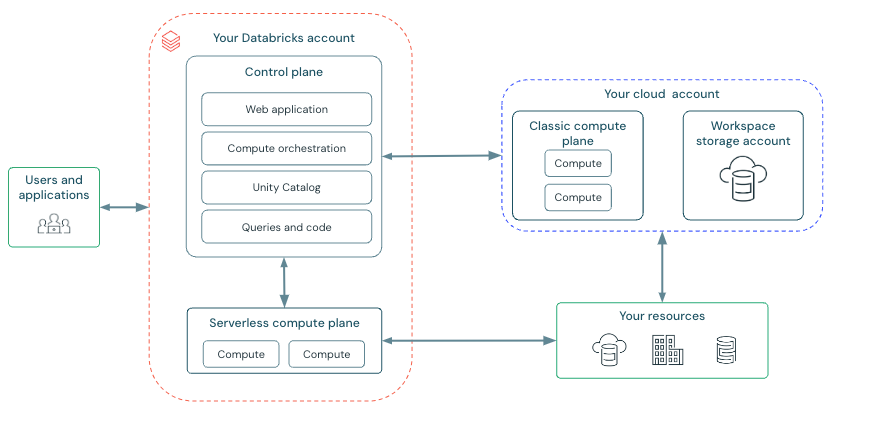
Azure Databricks 拆分为两个主要平面: 控制平面,由Microsoft管理的后端服务(例如 Web UI)和运行数据工作负荷的 计算平面组成。 计算有两种类型:经典计算和无服务器计算。经典计算使用您自己的 Azure 订阅和虚拟网络,提供订阅内部的隔离,而无服务器计算在 Databricks 托管环境内运行,但仍位于与您的工作区相同的 Azure 区域,并利用网络和安全控制在客户之间提供隔离。 每个工作区都有一个订阅中的存储帐户,用于保存系统数据(笔记本、日志、作业元数据)、分布式文件系统(DBFS)和目录资产(如果已启用 Unity 目录),并具有额外的网络、防火墙和访问权限控制,以确保安全性和适当的隔离。
注释
还可以选择将群集附加到空闲节点 池 ,以减少群集启动时间。 有关详细信息,请参阅 Azure Databricks 文档中的 池 。