了解 Spark
Spark 的核心是 数据处理引擎,这意味着它使数据工程师能够跨分布式系统有效地提取、转换和分析大型数据集。 区别在于它能够在一个框架下统一不同类型的数据工作负荷。 使用 Spark 时,无需单独的系统进行实时流式处理、批处理、SQL 查询或机器学习。 可以使用一组一致的 API 在 Spark 中完成所有作。
另一种力量在于它的易用性。 Spark 支持多种编程语言,包括 Python、Java、Scala 和 R。如果已经熟悉 Python,则可以使用适用于 Spark 的 Python 接口 PySpark 立即开始分析数据。
也许最重要的是,Spark 是考虑到可伸缩性的。 可以在本地计算机上开始试验,然后,在不更改代码的情况下,在数百台或数千台计算机的群集上运行相同的应用程序。
Spark 的生态系统
虽然人们经常谈论 Spark 作为一件事,但它实际上是一个基于核心引擎构建的库生态系统:
Spark Core 为分布式计算提供了基础,包括任务计划、内存管理和故障恢复。
Spark SQL 允许你使用大多数分析师已经知道的语言处理结构化数据:SQL。 它还与 Hive、Parquet 和 JSON 等外部数据源集成。
Spark 流式处理 允许近乎实时地处理数据,这对于欺诈检测或监视系统日志等应用程序非常有用。
MLlib 是 Spark 的机器学习库。 它提供用于分类、聚类分析、回归和建议的算法的可缩放实现。
GraphX 用于图形计算,例如分析社交网络或实体之间的建模关系。
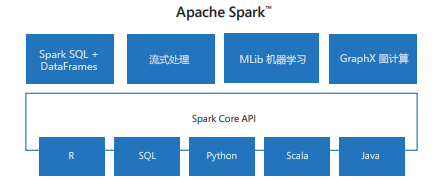
这些组件共同使 Spark 成为大多数大数据问题的一站式解决方案。
Spark 的工作原理
你可能会想:我为什么要编写 Spark 程序? 答案是为了应对大规模数据处理。 当您的数据集大到无法放入单台计算机的内存中,或需要计算速度比传统工具如 Pandas 或 Excel 更快速时,Spark 就能大显身手。 Spark 允许编写与处理本地数据非常相似的代码,但它会在群集中的许多计算机上自动分发该代码。 结果是,可以在数据集增长时分析千兆字节、TB 甚至 PB 级数据,而无需重写逻辑。
假设公司将网站点击流数据存储在 Azure Data Lake Storage 中。 你希望通过过滤过去24小时内的所有点击,关联用户资料表,然后计算最常访问的五个产品类别,以此了解客户行为。
以下是在 Databricks 中实现此情况时会发生什么情况:
笔记本包含你在 Python(PySpark)中编写的代码,并且此代码在驱动程序程序上运行。 驱动程序负责将高级命令(例如筛选行或分组数据)转换为较小的任务计划。
然后 ,群集管理器 将这些任务分配给不同的 执行程序。 每个执行程序都是在群集中的计算机上运行的辅助进程。 Apache Spark 群集是一组互连的服务器,这些服务器被视为单个计算引擎并处理从笔记本发出的命令的执行。 对于用户 ID 为 1–100,000 的点击次数,一个执行程序可能会筛选昨天的结果,另一个执行程序(可能在同一台或另一台服务器上)则负责 ID 为 100,001–200,000 的情况,依此类推。
所有执行程序完成其部分工作后,Spark 将收集结果、合并结果,并为你提供一个显示顶级产品类别的干净数据帧。
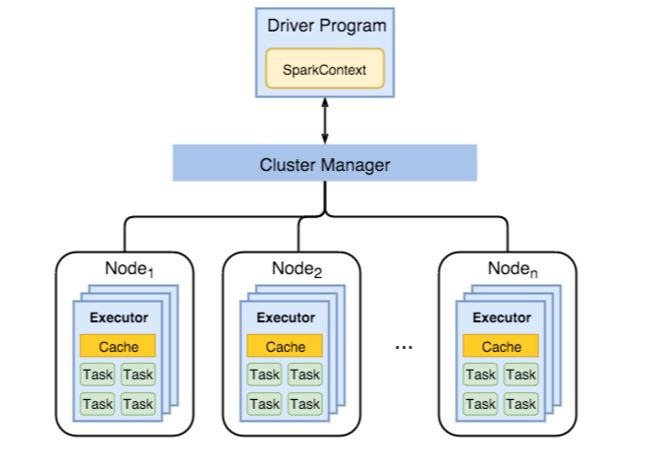
从数据工程师的角度来看,你只需在 Databricks 笔记本中编写熟悉的 DataFrame 代码。 Spark 负责分发数据、并行计算,并在群集中发生故障时重试任务。 这种设计使 Spark 感觉易于理解(就像使用本地数据工具一样),但在后台,它正在协调跨可能数百台计算机进行高度并行的容错计算。
延迟评估和 DAG
Spark 最重要的设计选择之一是 延迟评估。 与 Pandas 等工具不同,其中每个操作都会立即运行,Spark 不会在你编写命令时立即执行。 相反,当你应用转换(如筛选行、联接表或选择列)时,Spark 只需在计划中记录这些操作。 尚未启动任何实际计算过程。 此方法允许 Spark 在决定执行它们的最有效方案之前查看完整的操作序列。
在后台,Spark 会生成操作的有向无环图 (DAG)。 图形中的每个节点表示一个数据集,每个边缘表示应用于该数据集的转换。 由于图形是无环的,因此它从原始输入数据向最终结果的一个方向流动,而不会循环回本身。 Spark 的优化器分析此 DAG,以合并步骤、最小化数据移动并确定群集中的最佳执行策略。
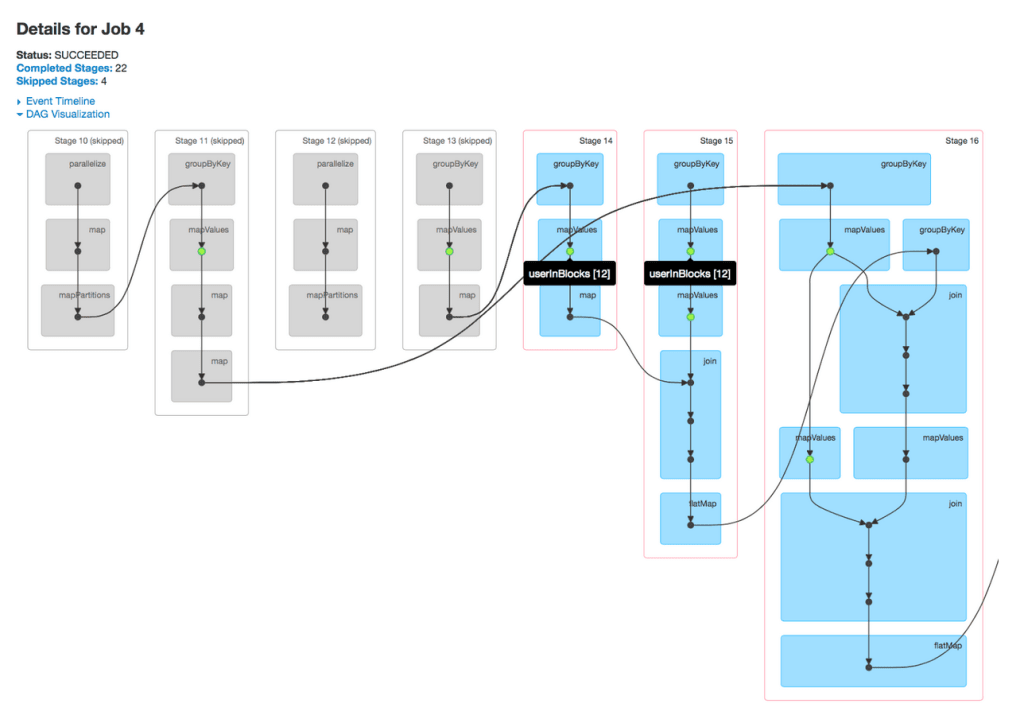
仅当执行 作(例如,将结果收集到驱动程序、将数据写入存储或对行进行计数)时,才会开始执行。 此时,Spark 会将优化的 DAG 作为一系列任务提交到集群管理器,集群管理器会将这些任务分发到执行器。 此设计有助于 Spark 实现高性能:它避免不必要的计算,减少节点之间的数据混排,并确保尽可能高效地使用群集资源。
Real-World 用例
许多行业的组织每当需要处理和分析大型或快速移动的数据集时,都会使用 Spark。 例如, 视频流式处理服务 可能使用 Spark 生成建议引擎,以基于查看历史记录来建议新内容。 金融机构可以依靠 Spark 流式处理实时监视交易并标记可疑活动。 在 医疗保健行业,研究人员可能使用 Spark 大规模分析遗传数据,以识别与疾病相关的模式。 即使在更传统的业务设置中,Spark 也经常在准备和转换原始作数据方面发挥作用,以便可用于仪表板和报告。
其他常见应用程序包括分析大量 Web 服务器日志、为物联网(IoT)设备提供 实时仪表板 、在非常大的数据集上训练 机器学习模型 ,以及构建从多个源提取、清理和合并原始数据的 ETL 管道 。
兼容性和部署选项
Spark 的优势之一是它不会将你锁定在单个基础结构中。 而是设计为运行在各种分布式系统之上,这为您提供了灵活性,使您可以根据需要在不同的地点进行部署。 在最简单的级别,Spark 可以在自己的计算机上本地运行,以便轻松试验小型数据集或学习基础知识,而无需设置群集。 如果需要更多功能,可以通过在计算机的独立群集上运行 Spark 来横向扩展,或将其与处理计划和资源分配的资源管理器(如 Hadoop YARN 或 Apache Mesos)集成。
在云中,Spark 在提供商之间受到广泛支持。 例如, Azure Databricks、 Azure Synapse Analytics 和 Microsoft Fabric 等服务可以直接启动 Spark 群集,而无需担心群集设置和管理的详细信息。 Spark 也越来越多地部署在 Kubernetes 上,这样组织就可以容器化其 Spark 应用程序,并在新式云原生环境中运行它们。 这种灵活性意味着,随着需求的发展,从本地开发到本地群集,到大规模云部署,你可以继续使用相同的 Spark 应用程序,而无需为不同的平台重写它们。