缓解潜在危害
确定基线和测量解决方案生成的有害输出的方法后,可以采取措施来缓解潜在危害,并在适当地重新测试修改后的系统,并将危害级别与基线进行比较。
缓解生成 AI 解决方案中的潜在危害涉及分层方法,其中缓解技术可应用于四个层中的每一个,如下所示:
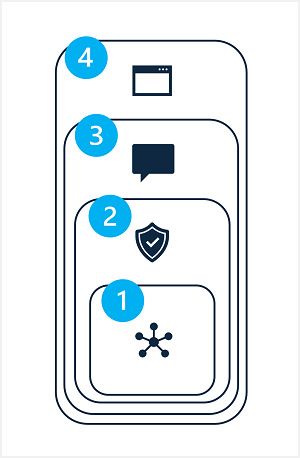
- 型号
- 安全系统
- 系统消息和基础设置
- 用户体验
1: 模型 层
模型层由解决方案的核心一个或多个生成 AI 模型组成。 例如,解决方案可能围绕 GPT-4 等模型生成。
可在模型层应用的缓解措施包括:
- 选择适合预期解决方案使用的模型。 例如,虽然 GPT-4 可能是一种强大且通用的模型,但在仅对小型特定文本输入进行分类所需的解决方案中,更简单的模型可能会提供所需的功能,并降低有害内容生成的风险。
- 使用 自己的训练数据微调基础模型,使其生成的响应更有可能与解决方案方案相关且范围更广。
2: 安全系统 层
安全系统层包括平台级配置和有助于减轻伤害的功能。 例如,Azure AI Foundry 支持应用条件的 内容筛选器,以根据内容的分类,对提示和响应进行抑制,将其分类为四种严重级别(安全、低、中、高),比如对于可能的四类潜在危害(仇恨、性、暴力和自我伤害)。
其他安全系统层缓解措施可能包括滥用检测算法,以确定解决方案是否受到系统滥用(例如,通过来自机器人的大量自动请求)和警报通知,以便快速响应潜在的系统滥用或有害行为。
3:系统消息和基础设置层
此层侧重于提交到模型的提示的构造。 可在此层应用的危害缓解技术包括:
- 指定系统输入以定义模型的行为参数。
- 应用提示工程来向输入提示添加基础数据,从而最大化获得相关且无害输出的可能性。
- 使用 检索扩充生成 (RAG) 方法从受信任的数据源中检索上下文数据,并将其包含在提示中。
4: 用户体验 层
用户体验层包括软件应用程序,用户通过该应用程序与生成式 AI 模型和文档或其他用户辅助资料进行交互,用于描述解决方案的使用给其用户和利益干系人。
设计应用程序用户界面以限制特定主题或类型的输入,或应用输入和输出验证可以降低潜在有害响应的风险。
生成式AI解决方案的文档和其他说明应该适当地保持透明,明确说明系统的功能和限制、其所基于的模型,以及任何可能存在且无法总是通过你制定的缓解措施解决的潜在危害。