数据引入和集成
数据引入和集成构成了 Azure Databricks 中 Lakeflow 声明性管道的有效数据处理机制的基础层。 这可以确保将来自各种源的数据准确高效地加载到系统中,以做进一步的分析和处理。
Lakeflow 声明性管道通过以下方法促进数据引入和集成:
- 多源引入:让你可以从各种源收集数据。
- 流式处理和批处理数据:让你可以连续或按分组间隔处理数据。
- 架构管理:确保数据的结构处理得当且易于管理。
- 数据质量和治理:帮助你维持数据的完整性与合规性
- 管道自动化和业务流程:简化和控制数据处理任务的顺序
- 与 Azure 生态系统集成:让你可以顺畅地与各种 Azure 工具和服务交互
- 性能优化:提高你快速有效地处理数据的能力
- 监视和世系跟踪:帮助你跟踪数据的历程并监视其在系统中的移动。
创建管道
首先,在 Lakeflow 声明性管道中创建 ETL 管道。 Lakeflow 声明性管道通过使用 Lakeflow 声明性管道语法解析笔记本或文件中定义的依赖项(称为源代码)来创建管道。 每个源代码文件只能包含一种语言,但可以在管道中添加多种语言的笔记本或文件。
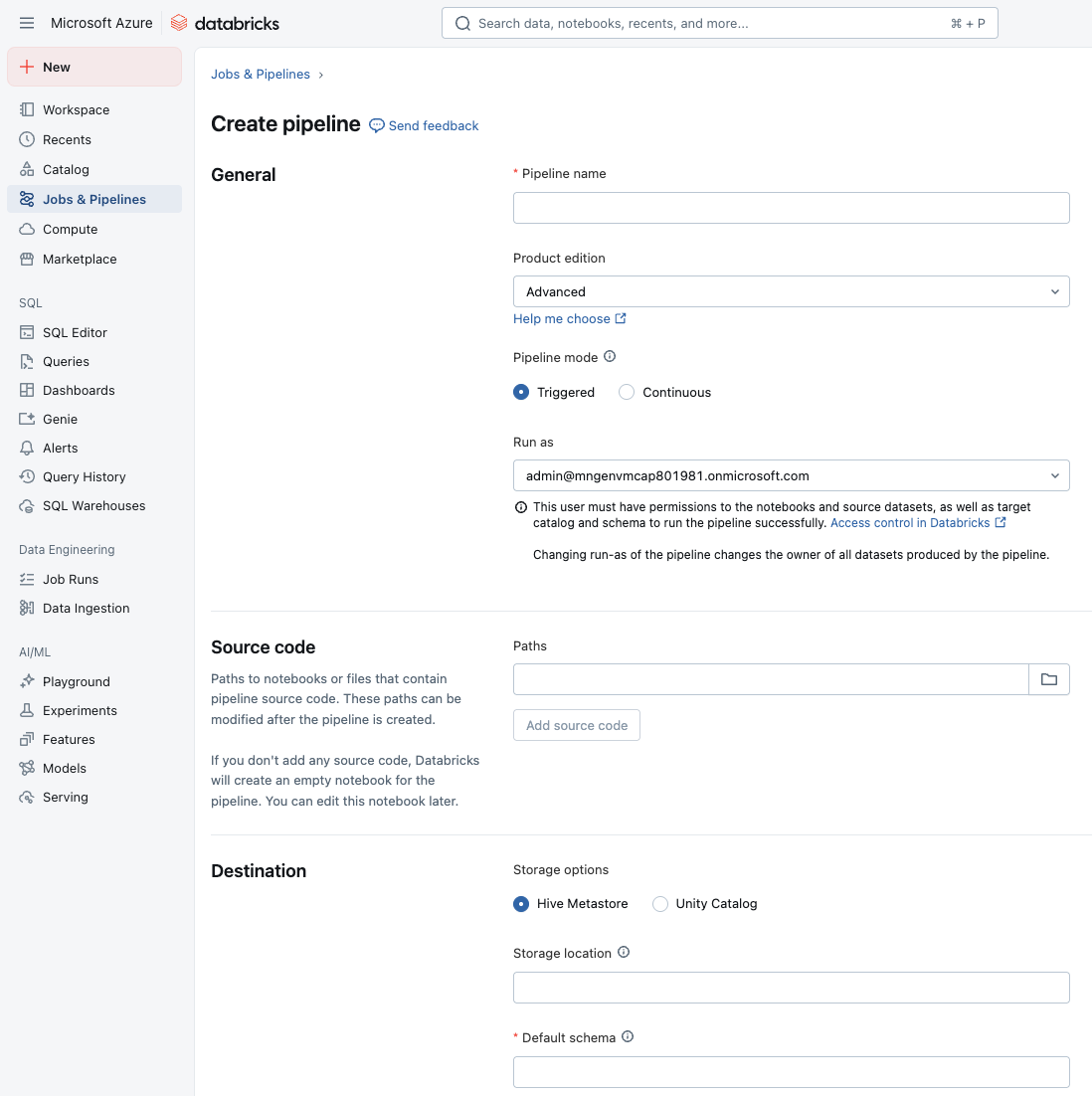
在工作区中,可以从边栏的“作业和管道”部分创建新的 ETL 管道。 应为管道分配名称、配置包含源代码的笔记本或文件,并设置目标存储位置和架构。
从现有表加载
在笔记本中,可以从 Databricks 的任何现有表中加载数据。 可以使用查询来转换数据,或加载该表以便在管道中进行进一步处理。
CREATE OR REFRESH MATERIALIZED VIEW top_baby_names_2021
COMMENT "A table summarizing counts of the top baby names for New York for 2021."
AS SELECT
First_Name,
SUM(Count) AS Total_Count
FROM baby_names_prepared
WHERE Year_Of_Birth = 2021
GROUP BY First_Name
ORDER BY Total_Count DESC
从云对象存储加载文件
Databricks 建议将自动加载器与 Lakeflow 声明性管道配合使用,以便从云对象存储或 Unity 目录卷中的文件引入大多数数据引入任务。 自动加载器和 Lakeflow 声明性管道旨在随着数据到达云存储而以增量方式和幂等方式加载不断增长的数据。
自动加载程序可以引入 JSON、CSV、XML、PARQUET、AVRO、ORC、TEXT 和 BINARYFILE 文件格式。
以下 SQL 示例使用自动加载程序从云存储读取数据:
CREATE OR REFRESH STREAMING TABLE sales
AS SELECT *
FROM STREAM read_files(
'abfss://myContainer@myStorageAccount.dfs.core.windows.net/analysis/*/*/*.json',
format => "json"
);
以下 SQL 示例使用自动加载程序从 Unity 目录卷中的 CSV 文件创建数据集:
CREATE OR REFRESH STREAMING TABLE customers
AS SELECT * FROM STREAM read_files(
"/Volumes/my_catalog/retail_org/customers/",
format => "csv"
)
解析 JSON
在 Lakeflow 声明性管道中,使用函数 from_json分析 JSON 数据时,可以让系统自动找出 JSON 架构(推理),并随时间(演变)进行调整,而不是预先对架构进行硬编码。 当架构提前或经常更改时,这非常有用。
为每个 from_json 表达式设置推理 + 演变时,都需要一个名为 schemaLocationKey 的唯一标识符。 它允许系统跟踪哪些 JSON 架构属于哪个分析表达式。 如果管道中有多个 JSON 分析表达式,则每个表达式都必须使用不同的 schemaLocationKey。 此外,密钥在给定管道的上下文中必须是唯一的。
下面是使用 SQL 语法的示例,演示如何将架构参数设置为 NULL,指示应推断架构而不是固定架构:
SELECT
value,
from_json(value, NULL, map('schemaLocationKey', 'keyX')) parsedX,
from_json(value, NULL, map('schemaLocationKey', 'keyY')) parsedY,
FROM STREAM READ_FILES('/databricks-datasets/nyctaxi/sample/json/', format => 'text')
可以选择使用固定的模式,即通过 from_json(jsonStr, schema, ...) 的方式来进行操作。 如果选择固定架构,则不使用推理和演变。 此外,当需要固定架构但还希望预测或处理架构偏移时,架构提示非常有用。
下面是 SQL 中的一个示例,其中查询采用包含两个字段(a 和 b)的 JSON 字符串,并使用第二个参数中指定的架构将其分析为结构化对象。 在这里,架构将 a 声明为整数,将 b 声明为双精度值,因此结果是一个 STRUCT<a: INT, b: DOUBLE>
SELECT from_json('{"a":1, "b":0.8}', 'a INT, b DOUBLE');
使用管道预期管理数据质量
可以选择使用预期应用质量约束,以在数据流经 ETL 管道时验证数据。 预期可对数据质量指标提供更深入的洞察,并在检测到无效记录时允许更新失败或丢弃记录。

下面是定义约束子句的具体化视图的示例。 在这种情况下,该约束包含正在验证的内容的实际逻辑:Country_Region 不应为空。 当记录不符合此条件时,就会触发预期。
CREATE OR REFRESH MATERIALIZED VIEW processed_covid_data (
CONSTRAINT valid_country_region EXPECT (Country_Region IS NOT NULL) ON VIOLATION FAIL UPDATE
)
COMMENT "Formatted and filtered data for analysis."
AS
SELECT
TO_DATE(Last_Update, 'MM/dd/yyyy') as Report_Date,
Country_Region,
Confirmed,
Deaths,
Recovered
FROM live.raw_covid_data;
约束示例:
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0) ON VIOLATION DROP ROW
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020) ON VIOLATION FAIL UPDATE
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0),
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
保留无效记录是默认的预期行为。 不符合预期的记录将与有效记录一起添加到目标数据集中。 如果指定 ON VIOLATION DROP ROW,那么不符合预期的记录将从目标数据集中删除。 最后,如果你指定了 ON VIOLATION FAIL UPDATE,则系统会以原子方式回滚事务。
应用转换
可以使用查询转换数据,就像使用标准 SQL 命令一样。 在以下示例中,我们定义了另一个聚合数据的具体化视图。
CREATE OR REFRESH MATERIALIZED VIEW aggregated_covid_data
COMMENT "Aggregated daily data for the US with total counts."
AS
SELECT
Report_Date,
sum(Confirmed) as Total_Confirmed,
sum(Deaths) as Total_Deaths,
sum(Recovered) as Total_Recovered
FROM live.processed_covid_data
GROUP BY Report_Date;
执行和监视 ETL 管道
在笔记本或源代码文件中定义代码后,便可以启动 ETL 管道了。 会提供一个可视化界面,可用于监视执行情况:

管道图在管道更新成功启动后立即显示。 箭头表示管道中数据集之间的依赖关系。 默认情况下,管道详细信息页显示表的最近更新,但你可以从下拉菜单中选择旧的更新。
Lakeflow 声明性管道支持以下任务:
- 观察管道更新的进度和状态。
- 对管道事件发出警报,例如管道更新的成功或失败。
- 查看 Apache Kafka 和自动加载程序等流式处理源的指标。
- 管道更新失败或成功完成时接收电子邮件通知。