适用于:![]() SQL Server
SQL Server![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例![]() Microsoft Fabric 预览版中的 SQL 数据库
Microsoft Fabric 预览版中的 SQL 数据库
SQL Server 2016 (13.x) 引入了实时运营分析,可以同时对同一个数据库表运行分析和 OLTP 工作负载。 除了实时运行分析以外,你还可以消除对 ETL 和数据仓库的需求。
实时运营分析介绍
传统上,企业有用于运营工作负荷(即 OLTP)和分析工作负荷的独立系统。 对于此类系统,提取、转换和加载 (ETL) 作业会定期将数据从操作存储转移到分析存储。 分析数据通常存储在专用于运行分析查询的数据仓库或数据市场中。 尽管这种解决方案已成为标准,但在以下三个方面存在很大问题:
- Complexity. 实施 ETL 可能需要编码相当多的代码,尤其是只想要加载修改的行时。 识别哪些行已被修改是一个复杂的过程。
- Cost. 实施 ETL 需要付出采购额外硬件和软件许可证的成本。
- Data Latency. 实施 ETL 会增大运行分析的时间延迟。 例如,如果 ETL 作业在每个工作日结束时运行,分析查询会针对至少一天的数据运行。 对于许多企业来说,这种延迟不可接受,因为企业依赖于实时分析数据。 例如,欺诈检测需要实时分析操作数据。
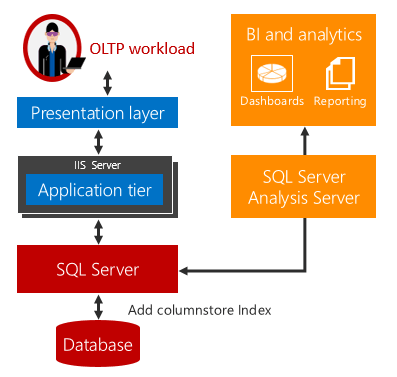
实时运行分析为这些难题提供了解决方案。
对同一个基础表运行分析和 OLTP 工作负载时不会出现时间延迟。 对于使用实时分析的方案,成本和复杂性将大大降低,因为不需要使用 ETL,并且不需要采购和维护独立的数据仓库。
Note
实时运营分析针对单一数据源的场景,例如,您可以在企业资源规划 (ERP) 应用程序上同时运行运营和分析工作负载。 如果在运行分析工作负载之前需要集成多个源中的数据,或者你要使用预先聚合的数据(如多维数据集)实现极高的分析性能,则它不能取代独立的数据仓库。
实时分析对行存储表使用可更新的非聚集列存储索引。 列存储索引维护数据的副本,因此 OLTP 和分析工作负载可针对数据的独立副本运行。 这可以最大程度地降低对同时运行的两个工作负载的性能影响。 数据库引擎自动维护索引更改,因此,要分析的 OLTP 更改始终是最新的。 通过这种设计,对最新数据实时运行分析是切实可行的。 这适用于基于磁盘的表和内存优化表。
入门示例
若要开始使用实时分析,请执行以下操作:
识别操作架构中包含需要用于分析的数据的表。
对于每个表,删除主要用于提高 OLTP 工作负载上现有分析速度的所有 B 树索引。 将它们替换为单个非聚集列存储索引。 这可以提高 OLTP 工作负荷的整体性能,因为要维护的索引较少。
--This example creates a nonclustered columnstore index on an existing OLTP table. --Create the table CREATE TABLE t_account ( accountkey int PRIMARY KEY, accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int ); --Create the columnstore index with a filtered condition CREATE NONCLUSTERED COLUMNSTORE INDEX account_NCCI ON t_account (accountkey, accountdescription, unitsold) ;内存优化表上的列存储索引通过将内存中 OLTP 和列存储技术相结合,为 OLTP 和分析工作负载提供高性能,实现运营分析。 内存优化表上的列存储索引必须是聚集索引,换句话说,它必须包含所有列。
-- This example creates a memory-optimized table with a columnstore index. CREATE TABLE t_account ( accountkey int NOT NULL PRIMARY KEY NONCLUSTERED, Accountdescription nvarchar (50), accounttype nvarchar(50), unitsold int, INDEX t_account_cci CLUSTERED COLUMNSTORE ) WITH (MEMORY_OPTIMIZED = ON );
现在,无需对应用程序进行任何更改,就能运行实时运营分析。 分析查询将针对列存储索引运行,OLTP 操作将针对 OLTP B 树索引不断运行。 OLTP 工作负载将继续执行,但维护列存储索引会产生更多的开销。 请参阅下一部分中有关性能优化的信息。
Blog posts
要详细了解实时运营分析,请阅读以下博客文章。 如果你先阅读这些博客文章,则可以更容易理解性能提示部分。
Videos
有关某些功能和注意事项的更多详细信息,请参阅“Data Exposed”视频系列。
性能提示 #1:使用筛选索引提高查询性能
运行实时运营分析可能会影响 OLTP 工作负载的性能。 这种影响应该很小。 示例 A 演示如何使用筛选索引来最大程度地减少非聚集列存储索引对事务工作负荷的影响,同时仍实时交付分析。
为了尽量减少维护操作工作负载上非聚集列存储索引的开销,你可以使用筛选条件,以便只对暖数据或缓慢变化的数据创建非聚集列存储索引。 例如,在订单管理应用程序中,可以针对已发货的订单创建非聚集列存储索引。 订单在发货后,就很少会发生变化,因此被视为暖数据。 使用筛选索引时,非聚集列存储索引中的数据需要更少的更新,从而降低对事务工作负荷的影响。
分析查询将根据需要以透明方式访问暖数据和热数据,以提供实时分析。 如果操作工作负载的重要部分处理热数据,这些操作不需要额外维护列存储索引。 最佳做法是对筛选索引定义中使用的列使用行存储聚集索引。 数据库引擎使用聚集索引快速扫描不符合筛选条件的行。 如果没有此聚集索引,需要对行存储表进行完整表扫描才能查找这些行,这可能会对分析查询的性能产生负面影响。 如果不使用聚集索引,你可以创建一个互补筛选的非聚集 B 树索引来标识这些行,但我们不建议这样做,因为通过非聚集 B 树索引访问大量的行会造成很大的开销。
Note
只有基于磁盘的表才支持筛选的非聚集列存储索引。 内存优化表不支持它。
示例 A:从 B 树索引访问热数据,从列存储索引访问暖数据
此示例使用筛选条件 (accountkey > 0) 来确定列存索引中包含的行。 目的是设计筛选条件和后续查询,以便从 B+ 树索引访问经常变化的“热”数据,从列存储索引访问更稳定的“暖”数据。

Note
查询优化器会考虑列存索引以用于查询计划,但并不总是选择它。 当查询优化器选择筛选的列存储索引时,将以透明方式合并来自列存储索引的行以及不符合筛选条件的行,以便能够进行实时分析。 这不同于常规的非聚集筛选索引,后者只能在将自身限制为索引中存在的行的查询中使用。
-- Use a filtered condition to separate hot data in a rowstore table
-- from "warm" data in a columnstore index.
-- create the table
CREATE TABLE orders (
AccountKey int not null,
CustomerName nvarchar (50),
OrderNumber bigint,
PurchasePrice decimal (9,2),
OrderStatus smallint not null,
OrderStatusDesc nvarchar (50)
);
-- OrderStatusDesc
-- 0 => 'Order Started'
-- 1 => 'Order Closed'
-- 2 => 'Order Paid'
-- 3 => 'Order Fulfillment Wait'
-- 4 => 'Order Shipped'
-- 5 => 'Order Received'
CREATE CLUSTERED INDEX orders_ci ON orders(OrderStatus);
--Create the columnstore index with a filtered condition
CREATE NONCLUSTERED COLUMNSTORE INDEX orders_ncci ON orders (accountkey, customername, purchaseprice, orderstatus)
WHERE OrderStatus = 5;
-- The following query returns the total purchase done by customers for items > $100 .00
-- This query will pick rows both from NCCI and from 'hot' rows that are not part of NCCI
SELECT TOP (5) CustomerName, SUM(PurchasePrice)
FROM orders
WHERE PurchasePrice > 100.0
GROUP BY CustomerName;
分析查询使用以下查询计划执行。 你可以看到,不符合筛选条件的行是通过聚集 B 树索引访问的。

有关详细信息,请参阅 博客:筛选的非聚集列存储索引。
性能提示 #2:将分析负载转移到 Always On 可读次要副本
尽管你可使用已筛选的列存储索引来尽量减少列存储索引维护,但分析查询可能仍需要大量计算资源(CPU、I/O、内存),这会影响操作工作负载的性能。 对于大多数任务关键型工作负载,我们建议使用 AlwaysOn 配置。 在这种配置中,你可以通过将运行分析转移到可读辅助节点来消除影响。
性能提示 #3:通过在增量行组中保存热数据来减少索引碎片
如果工作负载更新/删除了已压缩的行,包含列存储索引的表可能会出现大量碎片(即已删除的行)。 有碎片的列存储索引会导致内存/存储利用效率下降。 除了资源的低效利用以外,还会对分析查询性能造成负面影响,因为需要额外的 I/O,并且需要从结果集中筛选出已删除的行。
在使用 REORGANIZE 命令运行索引碎片整理,或者在整个表或受影响的分区上重新生成列存储索引之前,已删除的行实际上并未删除。 索引 REORGANIZE 和 REBUILD 的操作开销很高,占用了原本可用于其他工作负载的资源。 此外,如果过早压缩行,可能会由于更新而需要重新压缩多次,从而导致压缩开销的浪费。
可使用 COMPRESSION_DELAY 选项来尽量减少索引碎片。
-- Create a sample table
CREATE TABLE t_colstor (
accountkey int not null,
accountdescription nvarchar (50) not null,
accounttype nvarchar(50),
accountCodeAlternatekey int
);
-- Creating nonclustered columnstore index with COMPRESSION_DELAY.
-- The columnstore index will keep the rows in closed delta rowgroup
-- for 100 minutes after it has been marked closed.
CREATE NONCLUSTERED COLUMNSTORE INDEX t_colstor_cci ON t_colstor
(accountkey, accountdescription, accounttype)
WITH (DATA_COMPRESSION = COLUMNSTORE, COMPRESSION_DELAY = 100);
有关详细信息,请参阅 博客:压缩延迟。
下面是建议的最佳做法:
插入/查询工作负荷: 如果工作负荷主要插入数据并查询数据,则建议使用默认值
COMPRESSION_DELAY0。 在单个增量行组中插入 100 万行后,新插入的行将被压缩。 需要分析 Web 应用程序中的选择模式时,此类工作负荷的一些示例是传统的 DW 工作负荷或选择流分析。OLTP 工作负荷: 如果工作负荷主要是以 DML 操作为主(即大量的更新、删除和插入混合),则可以通过检查 DMV
sys.dm_db_column_store_row_group_physical_stats观察到列存储索引碎片。 如果你看到 > 最近压缩的行组中有 10 个% 行被标记为已删除,则可以使用COMPRESSION_DELAY选项在行有资格进行压缩时添加时间延迟。 例如,对于你的工作负载,如果新插入的数据保持“热”状态(即多次更新)60 分钟,应将COMPRESSION_DELAY指定为 60。
选项的 COMPRESSION_DELAY 默认值应适用于大多数客户。
对于高级用户,我们建议运行以下查询并收集过去七天内已删除行的百分比。
SELECT row_group_id,
CAST(deleted_rows AS float)/CAST(total_rows AS float)*100 AS [% fragmented],
created_time
FROM sys.dm_db_column_store_row_group_physical_stats
WHERE object_id = OBJECT_ID('FactOnlineSales2')
AND state_desc = 'COMPRESSED'
AND deleted_rows > 0
AND created_time > DATEADD(day, -7, GETDATE())
ORDER BY created_time DESC;
如果压缩行组中已删除的行数 > 20%,则平整变化率 < 5% 的旧行组(称为冷行组)会将 COMPRESSION_DELAY 设置为 (youngest_rowgroup_created_time - current_time)。 此方法最适用于稳定且相对同质的工作负荷。