适用于:![]() SQL Server
SQL Server
要创建分布式可用性组,必须创建两个具有各自侦听程序的可用性组。 然后将这些可用性组合并到分布式可用性组中。 以下步骤提供了在 Transact-SQL 中实现此操作的基本示例。 此示例不涵盖创建可用性组和侦听器的所有详细信息,相反,它着重于突出显示关键要求。
有关分布式可用性组的技术概述,请参阅分布式可用性组。
先决条件
若要配置分布式可用性组,必须满足以下各项:
- 支持的 SQL Server 版本。
注意
如果使用分布式网络名称 (DNN) 在 Azure VM 上的 SQL Server 上为可用性组配置了侦听器,则不支持在可用性组之上配置分布式可用性组。 若要了解详细信息,请参阅 Azure VM 上的 SQL Server 功能与 AG 和 DNN 侦听器的互操作性。
权限
需要服务器上的 CREATE AVAILABILITY GROUP 权限才能创建可用性组,以及需要 sysadmin 权限才能故障转移分布式可用性组。
设置数据库镜像终结点以侦听所有 IP 地址
确保数据库镜像终结点可以在分布式可用性组中的不同可用性组之间进行通信。 如果将一个可用性组设置为数据库镜像终结点上的特定网络,则分布式可用性组无法正常工作。 在托管分布式可用性组中副本的每个服务器上,将数据库镜像终结点设置为侦听所有 IP 地址(LISTENER_IP = ALL)。
创建数据库镜像终结点以侦听所有 IP 地址
例如,以下脚本在 TCP 端口 5022 上创建一个新的数据库镜像终结点,用于侦听所有 IP 地址。
CREATE ENDPOINT [aodns-hadr]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATABASE_MIRRORING
(
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
更改现有数据库镜像终结点以侦听所有 IP 地址
例如,以下脚本更改现有数据库镜像终结点以侦听所有 IP 地址。
ALTER ENDPOINT [aodns-hadr]
AS TCP
(
LISTENER_IP = ALL
);
GO
创建第一个可用性组
在第一个群集上创建主要可用性组
在第一个 Windows Server 故障转移群集 (WSFC) 上创建可用性组。 在此示例中,将用于数据库 ag1 的可用性组命令为 db1。 主可用性组的主要副本在分布式可用性组中称为全局主要副本。 Server1 是此示例中的全局主要副本。
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注意
上述示例使用自动种子设定,其中 SEEDING_MODE 设置为 AUTOMATIC,用于副本和分布式可用性组。 此配置将设置次要副本和次要可用性组自动填充,而无需手动备份和还原主要数据库。
将次要副本联接到主要可用性组
任何次要副本都必须使用 JOIN 选项联接到具有 ALTER AVAILABILITY GROUP 的可用性组。 由于在此示例中使用了自动种子设定,因此也必须调用具有 GRANT CREATE ANY DATABASE 选项的 ALTER AVAILABILITY GROUP。 此设置允许可用性组创建数据库并开始从主要副本自动进行种子设定。
在此示例中,在次要副本 server2上运行以下命令,以联接 ag1 可用性组。 允许可用性组在次要副本上创建数据库。
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
注意
当可用性组在辅助副本上创建数据库时,它将数据库所有者设置为运行 ALTER AVAILABILITY GROUP 语句的帐户以授予创建任意数据库的权限。 有关详细信息,请参阅授予可用性组在复制副本上创建数据库的权限。
为主要可用性组创建侦听程序
接下来,在第一个 WSFC 上为主要可用性组添加侦听器。 在此示例中,侦听器名为 ag1-listener。 有关创建侦听程序的详细说明,请参阅创建或配置可用性组侦听程序 (SQL Server)。
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
创建第二个可用性组
然后,在第二个 WSFC 上创建次要可用性组 ag2。 在这种情况下,不会指定数据库,因为它会自动从主可用性组进行初始化。 辅助可用性组的主要副本在分布式可用性组中称为转发器。 在此示例中,server3 是转发器。
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注意
- 该次要可用性组必须使用相同的数据库镜像终结点(此示例中为端口 5022)。 否则,在本地故障转移后,副本会停止。
- 基础可用性组应处于相同的可用性模式 - 两个可用性组都应处于同步提交模式,或者两者都应处于异步提交模式。 在准备好进行故障转移之前,如果不确定要使用哪个模式,请将两者都设置为异步提交模式。
将次要副本联接到次要可用性组
在此示例中,在次要副本 server4上运行以下命令,以联接 ag2 可用性组。 允许可用性组在次要副本上创建数据库以支持自动种子设定。
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
为次要可用性组创建侦听器
接下来,在第二个 WSFC 上添加次要可用性组的侦听器。 在此示例中,侦听器名为 ag2-listener。 有关创建侦听程序的详细说明,请参阅创建或配置可用性组侦听程序 (SQL Server)。
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
在第一个群集上创建分布式可用性组
在第一个 WSFC 上创建分布式可用性组(此示例中命名为 distributedAG )。 使用具有 DISTRIBUTED 选项的 CREATE AVAILABILITY GROUP 命令。 AVAILABILITY GROUP ON 参数指定了成员可用性组、 和 ag1ag2。
若要使用自动种子设定创建分布式可用性组,请使用以下 Transact-SQL 代码:
CREATE AVAILABILITY GROUP [distributedAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
注意
LISTENER_URL 为每个可用性组指定了侦听程序与可用性组的数据库镜像端点。 在此示例中,为端口 5022 (不是用于创建侦听程序的端口 60173 )。 如果使用负载均衡器(例如在 Azure 中),为分布式可用性组端口添加负载均衡规则。 向侦听器端口添加规则,除了 SQL Server 实例端口。
取消转发器的自动种子设定
无论出于何种原因,如果必须在同步两个可用性组前取消转发器的初始化,请通过将转发器的 SEEDING_MODE 参数设置为 MANUAL 并立即取消种子设定来更改分布式可用性组。 在全局主要可用性组中运行命令:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedAG]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
在第二个群集上联接分布式可用性组
然后,在第二个 WSFC 上联接分布式可用性组。
若要使用自动种子设定联接分布式可用性组,请使用以下 Transact-SQL 代码:
ALTER AVAILABILITY GROUP [distributedAG]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
联接第二个可用性组的辅助数据库
如果第二个可用性组已设置为使用自动种子设定,则转到步骤 2。
如果第二个可用性组正在使用手动种子设定,则将对全局主副本的备份还原到第二个可用性组的次要副本:
RESTORE DATABASE [db1] FROM DISK = '<full backup location>' WITH NORECOVERY; RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY;当第二个可用性组的次要副本上的数据库处于正在还原状态后,必须手动将它联接到可用性组。
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
故障转移分布式可用性组
由于 SQL Server 2022 (16.x) 引入了 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 设置的分布式可用性组支持,因此,SQL Server 2022 及更高版本与 SQL Server 2019 及更早版本的分布式可用性故障转移说明不同。
对于分布式可用性组,唯一支持的故障转移类型是手动的用户启动 FORCE_FAILOVER_ALLOW_DATA_LOSS。 因此,若要防止数据丢失,必须执行额外的步骤(详情见本部分所述),以确保在启动故障转移之前在两个副本之间同步数据。
如果出现可接受数据丢失的紧急情况,可以启动故障转移,而无需通过运行来确保数据同步:
ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
可以使用同一命令来故障转移到转发器,以及故障回复到全局主数据库。
在 SQL Server 2022 (16.x) 及更高版本上,可以为分布式可用性组配置 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 设置,该设置旨在保证分布式可用性组故障转移时不会丢失任何数据。 如果已配置此设置,请按照本部分中的步骤对分布式可用性组进行故障转移。 如果不想使用 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 设置,请按照说明在 SQL Server 2019 及更早版本中对分布式可用性组进行故障转移。
注意
将 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 设置为 1 意味着在主副本上提交事务之前,主副本会等待在次要副本上提交事务,这可能会降低性能。 尽管分布式可用性组不需要限制或停止全局主数据库上的事务才能在 SQL Server 2022 (16.x)中同步,但这样做可以提高用户事务和分布式可用性组同步的性能,并将 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 设置为 1。
确保数据不会丢失的步骤
若要确保没有数据丢失,必须先配置分布式可用性组,以支持无数据丢失,步骤如下:
- 若要准备故障转移,请验证全局主 服务器和 转发器是否处于
SYNCHRONOUS_COMMIT模式。 如果不是,请通过SYNCHRONOUS_COMMIT将其设置为 。 - 将分布式可用性组设置为在全局主副本和转发器上同步提交。
- 请等待分布式可用性组同步完成。
- 在全局主副本上,使用
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT将分布式可用性组 设置设为 1。 - 验证本地 AG 和分布式可用性组中的所有副本是否正常运行,并验证分布式可用性组是否处于 SYNCHRONIZED 状态。
- 在全局主副本上,将分布式可用性组角色设置为
SECONDARY,从而使分布式可用性组不可用。 - 在转发器(预期的新主副本)上,使用 ALTER AVAILABILITY GROUP 和
FORCE_FAILOVER_ALLOW_DATA_LOSS对分布式可用性组进行故障转移。 - 在新辅助副本(上一个全局主副本)上,将分布式可用性组
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT设置为 0。 - 可选:如果可用性组跨越导致延迟的地理距离,请将可用性模式更改为
ASYNCHRONOUS_COMMIT。 如有必要,这将从第一步还原变更。
T-SQL 示例
本部分介绍了使用 Transact-SQL 对名为 distributedAG 的分布式可用性组进行故障转移的详细步骤示例。 示例环境共有 4 个节点用于分布式可用性组。 全局主 N1 和 N2 主机可用性组 ag1 ,而转发器 N3 和 N4 主机可用性组 ag2。 分布式可用性组 distributedAG 将更改从 ag1 推送到 ag2。
查询以验证构成分布式可用性组的本地可用性组的主副本的
SYNCHRONOUS_COMMIT。 直接在 转发器和全局主服务器 上运行以下 T-SQL:SELECT DISTINCT ag.name AS [Availability Group], ar.replica_server_name AS [Replica], ar.availability_mode_desc AS [Availability Mode] FROM sys.availability_replicas AS ar INNER JOIN sys.availability_groups AS ag ON ar.group_id = ag.group_id INNER JOIN sys.dm_hadr_database_replica_states AS rs ON ar.group_id = rs.group_id AND ar.replica_id = rs.replica_id WHERE ag.name IN ('ag1', 'ag2') AND rs.is_primary_replica = 1 ORDER BY [Availability Group]; --if needed, to set a given replica to SYNCHRONOUS for node N1, default instance. If named, change from N1 to something like N1\SQL22 ALTER AVAILABILITY GROUP [testag] MODIFY REPLICA ON N'N1\SQL22' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);通过在全局主副本和转发器上运行以下代码,将分布式可用性组设置为同步提交:
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedAG] MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);注意
在分布式可用性组中,两个可用性组之间的同步状态取决于两个副本的可用性模式。 对于同步提交模式,当前的主要可用性组和当前的次要可用性组必须具有
SYNCHRONOUS_COMMIT可用性模式。 因此,必须在全局主备份和转发服务器上运行此脚本。等待分布式可用性组的状态更改为
SYNCHRONIZED。 在全局主副本上运行以下查询:-- Run this query on the Global Primary -- Check the results to see if synchronization_state_desc is SYNCHRONIZED SELECT ag.name, drs.database_id AS [Availability Group], db_name(drs.database_id) AS database_name, drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id WHERE ag.name = 'distributedAG' ORDER BY [Availability Group];在可用性组 synchronization_state_desc 变为
SYNCHRONIZED后继续。对于 SQL Server 2022(16.x)及更高版本,在全球主服务器上,使用以下 T-SQL 将
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT设置为 1:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);通过查询全局主副本和转发器,验证可用性组在所有副本上是否正常运行:
SELECT ag.name AS [AG Name], db_name(drs.database_id) AS database_name, ar.replica_server_name AS [replica], drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id INNER JOIN sys.availability_replicas AS ar ON drs.replica_id = ar.replica_id AND drs.replica_id = ar.replica_id WHERE ag.name IN ('ag1', 'ag2', 'distributedAG');在全局主要副本上,将分布式可用性组角色设置为
SECONDARY。 此时,分布式可用性组不可用。 完成此步骤后,必须执行其余步骤才能进行故障回复。ALTER AVAILABILITY GROUP distributedAG SET (ROLE = SECONDARY);通过在转发器上运行以下查询从全局主副本进行故障转移,以转换可用性组并使分布式可用性组重新上线:
-- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;执行此步骤后:
- 全局主副本将从
N1转换为N3。 - 转发器从
N3转换到N1。 - 分布式可用性组可用。
- 全局主副本将从
在新的转发器(以前的全局主副本,
N1)上,通过将分布式可用性组属性REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT设置为 0 来清除该属性:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);可选:如果可用性组因位于不同地理位置而导致延迟,请考虑在全局主副本和转发器上将可用性模式更改回
ASYNCHRONOUS_COMMIT。 如果需要,这会还原在第一步中所做的更改。-- If applicable: sets the distributed availability group to asynchronous commit: ALTER AVAILABILITY GROUP distributedAG MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT);
删除分布式可用性组
以下 Transact-SQL 语句删除了名为 distributedAG的分布式可用性组:
DROP AVAILABILITY GROUP distributedAG;
在故障转移群集实例上创建分布式可用性组
你可以使用故障转移群集实例 (FCI) 上的可用性组来创建分布式可用性组。 在此情况下,无需任何可用性组侦听器。 为 FCI 实例的主要副本使用虚拟网络名称 (VNN)。 以下示例演示了一个名为 SQLFCIDAG 的分布式可用性组。 一个可用性组为 SQLFCIAG。 SQLFCIAG 有 2 个 FCI 副本。 FCI 主要副本的 VNN 为 SQLFCIAG-1,FCI 次要副本的 VNN 为 SQLFCIAG-2。 该分布式可用性组还包含用于灾难恢复的 SQLAG-DR。
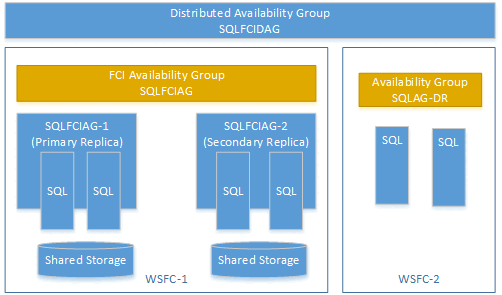
以下 DDL 创建此分布式可用性组:
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
侦听程序 URL 是主要 FCI 实例的 VNN。
在分布式可用性组中手动故障转移 FCI
若要手动故障转移 FCI 可用性组,请更新分布式可用性组,以反映侦听程序 URL 的更改。 例如,在分布式 AG 的全局 master 数据库和 SQLFCIDAG 的分布式 AG 的转发器上运行以下 DDL:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)
相关内容
- CREATE AVAILABILITY GROUP (Transact-SQL)(创建可用性组 (Transact-SQL))
- 更改可用性组 (Transact-SQL)