你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
该azure_ai扩展通过集成 Azure AI 服务的强大功能,增加了使用大型语言模型(LLM)并在 Azure Database for PostgreSQL 数据库中生成生成 AI 应用程序的能力。
生成式 AI 是一种形式的人工智能,在这种形式中,LLM 被训练基于自然语言输入生成原创内容。 通过使用 azure_ai 扩展,可以使用生成式 AI 的功能直接从数据库处理自然语言查询。
本文介绍如何使用 azure_ai 扩展向 Azure Database for PostgreSQL 灵活服务器实例添加丰富的 AI 功能。 它演示如何使用扩展将 Azure OpenAI 和 Azure AI 语言服务 集成到数据库中。
Prerequisites
一份 Azure 订阅。 免费创建一个。
已在所需的 Azure 订阅中授予对 Azure OpenAI 的访问权限。 目前,应用程序授予对此服务的访问权限。 可以通过完成 Azure OpenAI 服务的有限访问权限表单来申请对 Azure OpenAI 的访问权限。
部署了
text-embedding-ada-002(版本 2)模型的 Azure OpenAI 资源。 此模型目前仅在 某些区域中可用。 如果你没有资源,Azure OpenAI 资源部署指南中阐述了创建资源的过程。一种 Azure AI 语言资源。 如果没有语言资源,可以按照总结快速入门中提供的说明,在 Azure 门户中创建一个资源。 可以使用免费定价层 (
Free F0) 试用该服务,之后再升级到付费层以用于生产。你的 Azure 订阅中的 Azure Database for PostgreSQL 灵活服务器实例。 如果没有此资源,请参阅 “创建 Azure Database for PostgreSQL”。
在 Azure Cloud Shell 中使用 psql 连接到数据库
在 Web 浏览器中打开 Azure Cloud Shell。 选择“Bash”作为环境。 如果出现提示,请选择用于 Azure Database for PostgreSQL 数据库的订阅,然后选择“创建存储”。
要检索数据库连接详细信息:
在 Azure 门户中,转到 Azure Database for PostgreSQL 灵活服务器实例。
在左侧菜单中的 “设置”下,选择“ 连接”。 复制“连接详细信息”块。
将环境变量复制的声明行粘贴到 Azure Cloud Shell 终端。 将
{your-password}令牌替换为创建数据库时设置的密码。export PGHOST={your-server-name}.postgresql.database.azure.com export PGUSER={your-user-name} export PGPORT=5432 export PGDATABASE={your-database-name} export PGPASSWORD="{your-password}"使用 psql 命令行工具连接到数据库。 在提示符下输入以下命令:
psql
安装azure_ai扩展
可以使用 azure_ai 扩展将 Azure OpenAI 和 Azure 认知服务集成到数据库中。 有关详细信息,请参阅在 Azure Database for PostgreSQL 中使用 Azure OpenAI 生成矢量嵌入。
若要在数据库中启用扩展,请执行以下作:
检查azure_ai扩展中的对象
查看扩展包含的对象 azure_ai 可以更好地了解它提供的功能。 可以使用\dx命令提示符中的psql元命令列出扩展中的对象:
\dx+ azure_ai
该元命令输出显示 azure_ai 扩展会在数据库中创建三个架构、多个用户定义的函数 (UDF) 和数个复合类型。 下表描述了扩展添加的架构:
| 架构 | 说明 |
|---|---|
azure_ai |
提供配置表和用于与其交互的 UDF 所在的主体架构。 |
azure_openai |
包含实现调用 Azure OpenAI 终结点的 UDF。 |
azure_cognitive |
提供与将数据库与 Azure 认知服务集成相关的 UDF 和复合类型。 |
函数和类型都与其中一个架构相关联。 若要查看架构中 azure_ai 定义的函数,请使用 \df 元命令。 指定应显示其函数的架构。 在\x auto命令之前的\df命令自动打开和关闭扩展显示,以便于在 Azure Cloud Shell 中查看命令的输出。
\x auto
\df+ azure_ai.*
使用该 azure_ai.set_setting() 函数设置 Azure AI 服务的终结点和关键值。 它接受一个密钥和分配给它的值。 该 azure_ai.get_setting() 函数提供了一种方法来检索使用 set_setting() 函数设置的值。 它接受你要查看的设置的密钥。 对于这两种方法,密钥必须是下列项之一:
| 密钥 | 说明 |
|---|---|
azure_openai.endpoint |
支持的 Azure OpenAI 终结点(例如 https://example.openai.azure.com)。 |
azure_openai.subscription_key |
Azure OpenAI 资源的订阅密钥。 |
azure_cognitive.endpoint |
支持的认知服务终结点(例如 https://example.cognitiveservices.azure.com)。 |
azure_cognitive.subscription_key |
认知服务资源的订阅密钥。 |
重要说明
由于 Azure AI 服务(包括 API 密钥)的连接信息存储在数据库中的配置表中, azure_ai 因此该扩展定义了一个调用 azure_ai_settings_manager 的角色,以帮助确保此信息受保护且仅可供具有该角色的用户访问。 此角色允许读取和写入与扩展相关的设置。
只有超级用户和 azure_ai_settings_manager 角色的成员才能调用 azure_ai.get_setting() 和 azure_ai.set_setting() 函数。 在 Azure Database for PostgreSQL 中,所有管理员用户都具有该 azure_ai_settings_manager 角色。
使用 Azure OpenAI 生成矢量嵌入
azure_ai 扩展的 azure_openai 架构允许使用 Azure OpenAI 为文本值创建矢量嵌入。 使用此架构,可以直接从数据库 使用 Azure OpenAI 生成嵌入 内容,以创建输入文本的矢量表示形式。 然后,这些表示形式可以用于矢量相似性搜索,并被机器学习模型利用。
嵌入是一种使用机器学习模型来评估信息接近程度的技术。 此方法允许有效识别数据之间的关系和相似性,以便算法可以识别模式并做出准确的预测。
设置 Azure OpenAI 终结点和密钥
在使用 azure_openai 函数之前,请先用您的 Azure OpenAI 服务终结点和密钥对扩展进行配置:
在 Azure 门户中,转到 Azure OpenAI 资源。 在左侧菜单中的 “资源管理”下,选择 “密钥和终结点”。
复制你的终结点和访问密钥。 可以使用
KEY1或KEY2。 始终准备好两个密钥可以安全地轮换和重新生成密钥,而不会导致服务中断。在以下命令中,将
{endpoint}{api-key}令牌替换为从 Azure 门户检索的值。 然后,从psql命令提示符运行命令,将值添加到配置表。SELECT azure_ai.set_setting('azure_openai.endpoint','{endpoint}'); SELECT azure_ai.set_setting('azure_openai.subscription_key', '{api-key}');验证在配置表中写入的设置:
SELECT azure_ai.get_setting('azure_openai.endpoint'); SELECT azure_ai.get_setting('azure_openai.subscription_key');
azure_ai 扩展现已连接到你的 Azure OpenAI 帐户,并准备好生成矢量嵌入了。
使用示例数据填充数据库
本文使用 BillSum 数据集 的一小部分来提供用于生成矢量的示例文本数据。 此数据集提供美国国会和加州州法案的列表。 可以从 bill_sum_data.csv下载包含此数据的文件。
若要在数据库中存储示例数据,请创建一个名为 bill_summaries 的表:
CREATE TABLE bill_summaries
(
id bigint PRIMARY KEY,
bill_id text,
bill_text text,
summary text,
title text,
text_len bigint,
sum_len bigint
);
通过使用命令提示符中的 PostgreSQL psql,将 CSV 文件中的示例数据加载到bill_summaries表中。 指定 CSV 文件的第一行是标题行。
\COPY bill_summaries (id, bill_id, bill_text, summary, title, text_len, sum_len) FROM PROGRAM 'curl "https://raw.githubusercontent.com/Azure-Samples/Azure-OpenAI-Docs-Samples/main/Samples/Tutorials/Embeddings/data/bill_sum_data.csv"' WITH CSV HEADER ENCODING 'UTF8'
启用矢量支持
可以使用 azure_ai 扩展程序为输入文本生成嵌入。 若要使生成的向量与数据库中的其余数据一起存储,必须安装 pgvector 扩展。 请遵循文档中的指南,以在数据库中启用向量支持。
在向您的数据库中添加向量支持后,通过使用bill_summaries数据类型在vector表中添加新列,以便存储嵌入。 模型 text-embedding-ada-002 生成具有 1,536 个维度的矢量,因此必须指定 1536 为矢量大小。
ALTER TABLE bill_summaries
ADD COLUMN bill_vector vector(1536);
生成和存储矢量
现在 bill_summaries 表已准备好存储嵌入。 通过使用 azure_openai.create_embeddings() 函数,可以创建 bill_text 字段的向量,并将其插入表中新创建的 bill_vector 列 bill_summaries 。
在使用 create_embeddings() 函数之前,请运行以下命令来检查它并查看所需的参数:
\df+ azure_openai.*
Argument data types命令输出\df+ azure_openai.*中的属性显示函数所需的参数列表:
| 参数 | 类型 | 默认 | 说明 |
|---|---|---|---|
deployment_name |
text |
Azure AI Foundry 门户中包含 text-embeddings-ada-002 模型的部署的名称。 |
|
input |
text |
用于创建嵌入的输入文本。 | |
timeout_ms |
integer |
3600000 |
超时时间(以毫秒为单位),之后操作将被停止。 |
throw_on_error |
boolean |
true |
指示函数是否应在错误时引发异常并导致包装事务回滚的标志。 |
第一个参数是 deployment_name 的具体值,是在您的 Azure OpenAI 帐户中部署嵌入模型时分配的。 若要检索此值,
转到 Azure 门户中的 Azure OpenAI 资源。
在左侧菜单中的 “资源管理”下,选择 “模型部署 ”以打开 Azure AI Foundry 门户。
在 Azure AI Foundry 门户中,选择 “部署”。 在“部署”窗格中,复制与模型部署关联的
text-embedding-ada-002值。
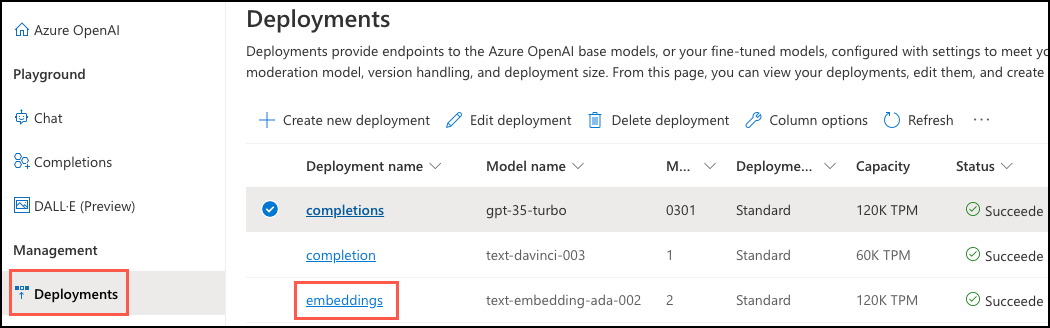
通过使用此信息,运行查询以更新表中的每条记录 bill_summaries 。 使用bill_text函数将bill_vector字段生成的向量嵌入插入到azure_openai.create_embeddings()列中。 将 {your-deployment-name} 替换为从 Azure AI Foundry 门户的“部署”窗格中复制的“部署名称”值。 然后,运行以下命令:
UPDATE bill_summaries b
SET bill_vector = azure_openai.create_embeddings('{your-deployment-name}', b.bill_text);
运行以下查询以查看为表中第一条记录生成的嵌入内容。 如果输出难以读取,则可以先运行 \x。
SELECT bill_vector FROM bill_summaries LIMIT 1;
每个嵌入都是由浮点数构成的向量。 矢量空间中两个嵌入之间的距离与原始格式的两个输入之间的语义相似性相关。
执行矢量相似性搜索
矢量相似性是一种测量两个项的相似程度的方法,方法是将其表示为向量。 向量是一系列数字。 它们通常用于通过大型语言模型(LLM)进行搜索。
矢量相似性通常通过距离指标计算,例如:
- Euclidean 距离:测量 n 维空间中两个向量之间的直线距离。
- 余弦相似性:测量两个向量之间角度的余弦值。
通过在vector上通过余弦距离和bill_summaries创建索引,实现对字段的更高效搜索。 HNSW 允许 pgvector 使用基于图形的最新算法来近似最近邻域查询。
CREATE INDEX ON bill_summaries USING hnsw (bill_vector vector_cosine_ops);
现在,已准备好对数据库执行 余弦相似性 搜索查询。
在以下查询中,输入问题的嵌入向量被生成,然后转换为向量数组(::vector)。 矢量数组允许将问题与表中存储的 bill_summaries 向量进行比较。
SELECT bill_id, title FROM bill_summaries
ORDER BY bill_vector <=> azure_openai.create_embeddings('embeddings', 'Show me bills relating to veterans entrepreneurship.')::vector
LIMIT 3;
查询使用 <=>向量运算符。 此运算符表示用于计算多维空间中两个向量之间的距离的余弦距离运算符。
集成 Azure 认知服务
扩展架构azure_cognitive中包含的 azure_ai Azure AI 服务集成提供了一组丰富的 AI 语言功能,可以直接从数据库进行访问。 这些功能包括情绪分析、语言检测、关键短语提取、实体识别和文本摘要。 可通过 Azure AI 语言服务启用这些功能。
若要查看可以通过扩展访问的完整 Azure AI 功能,请参阅 将 Azure Database for PostgreSQL 与 Azure 认知服务集成。
设置 Azure AI 语言服务终结点和密钥
与 azure_openai 函数一样,若要使用 azure_ai 扩展成功调用 Azure AI 服务,必须为 Azure AI 语言服务资源提供终结点和密钥:
在 Azure 门户中,转到语言服务资源。
在左侧菜单中的 “资源管理”下,选择 “密钥和终结点”。
复制你的终结点和访问密钥。 可以使用
KEY1或KEY2。在
psql命令提示符下运行以下命令,将值添加到配置表。 用您从 Azure 门户获取的值替换{endpoint}和{api-key}令牌。SELECT azure_ai.set_setting('azure_cognitive.endpoint','{endpoint}'); SELECT azure_ai.set_setting('azure_cognitive.subscription_key', '{api-key}');
汇总账单
为了演示 azure_cognitive 扩展的 azure_ai 函数的一些功能,可以生成每个帐单的摘要。 该 azure_cognitive 架构提供两个用于汇总文本的函数:
-
summarize_abstractive:抽象摘要生成一个摘要,它捕获输入文本中的主要概念,但可能不会使用完全相同的单词。 -
summarize_extractive:提取摘要通过从输入文本中提取关键句子来组合摘要。
要使用 Azure AI 语言服务的功能生成新的原创内容,请使用 summarize_abstractive 函数创建文本输入的摘要。 在 \df 处再次使用 psql 元命令,这次专门关注 azure_cognitive.summarize_abstractive 函数:
\df azure_cognitive.summarize_abstractive
Argument data types命令输出\df azure_cognitive.summarize_abstractive中的属性显示函数所需的参数列表:
| 参数 | 类型 | 默认 | 说明 |
|---|---|---|---|
text |
text |
要汇总的输入文本。 | |
language |
text |
输入文本的语言使用双字母的 ISO 639-1 表示。 对于允许的值,请检查 语言对语言功能的支持。 | |
timeout_ms |
integer |
3600000 |
超时时间(以毫秒为单位),之后操作将被停止。 |
throw_on_error |
boolean |
true |
指示函数是否应在错误时引发异常并导致包装事务回滚的标志。 |
sentence_count |
integer |
3 |
要包含在生成的摘要中的最大句子数。 |
disable_service_logs |
boolean |
false |
禁用语言服务日志的设置。 语言服务会将你的输入文本记录 48 小时,仅用于排除故障。 将此属性设置为 true 后,会禁用输入日志记录,并可能会限制我们调查所发生的问题的能力。 有关详细信息,请参阅 认知服务合规性和隐私说明 以及 Microsoft负责任的 AI 原则。 |
该summarize_abstractive函数需要下列参数: azure_cognitive.summarize_abstractive(text TEXT, language TEXT)
以下针对bill_summaries表的查询使用summarize_abstractive函数为法案文本生成新的单句摘要。 它允许您将生成式人工智能的强大功能直接纳入查询。
SELECT
bill_id,
azure_cognitive.summarize_abstractive(bill_text, 'en', sentence_count => 1) one_sentence_summary
FROM bill_summaries
WHERE bill_id = '112_hr2873';
还可以使用该函数将数据写入数据库表。 修改 bill_summaries 表以添加新列,用于在数据库中存储单句摘要:
ALTER TABLE bill_summaries
ADD COLUMN one_sentence_summary TEXT;
接下来,用摘要更新表。
summarize_abstractive 函数会返回文本的数组 (text[])。
array_to_string 函数会将返回值转换为其字符串表示形式。 在以下查询中,参数 throw_on_error 设置为 false. 此设置允许摘要过程在发生错误时继续。
UPDATE bill_summaries b
SET one_sentence_summary = array_to_string(azure_cognitive.summarize_abstractive(b.bill_text, 'en', throw_on_error => false, sentence_count => 1), ' ', '')
where one_sentence_summary is NULL;
在输出中,你可能会注意到有关无效文档的警告,提示无法为它们生成适当的摘要。 此警告是由于在前面的查询中将 throw_on_error 设置为 false 产生的。 如果将该标志保留为默认值 true,则查询将失败,并且不会将摘要写入数据库。 若要查看引发警告的记录,请运行以下命令:
SELECT bill_id, one_sentence_summary FROM bill_summaries WHERE one_sentence_summary is NULL;
然后,可以查询 bill_summaries 表以查看 azure_ai 扩展为表中其他记录生成的新单句摘要。
SELECT bill_id, one_sentence_summary FROM bill_summaries LIMIT 5;
结束语
祝贺! 你刚刚了解了如何使用 azure_ai 扩展将大型语言模型和生成 AI 功能集成到数据库中。