你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
跟踪是保存试验相关信息的过程。 本文介绍如何使用 MLflow 跟踪 Azure 机器学习工作区中的试验和运行。
使用 Azure 机器学习时,MLflow API 中提供的某些方法可能不可用。 有关支持和不支持的操作的详细信息,请参阅查询运行和试验的支持矩阵。 还可以从 MLflow 和 Azure 机器学习一文中了解 Azure 机器学习中支持的 MLflow 功能。
注意
- 若要跟踪在 Azure Databricks 上运行的试验,请参阅 使用 MLflow 和 Azure 机器学习跟踪 Azure Databricks 机器学习试验。
- 若要跟踪在 Azure Synapse Analytics 上运行的试验,请参阅使用 MLflow 和 Azure 机器学习跟踪 Azure Synapse Analytics ML 试验。
Prerequisites
拥有 Azure 订阅和 Azure 机器学习的免费或付费版本。
若要运行 Azure CLI 和 Python 命令,请安装 Azure CLI v2 和适用于 Python 的 Azure 机器学习 SDK v2。 首次运行 Azure 机器学习 CLI 命令时,会自动安装 Azure CLI 的
ml扩展。
安装 MLflow SDK
mlflow包和适用于 MLflow 的 Azure 机器学习azureml-mlflow插件:pip install mlflow azureml-mlflow提示
可以使用
mlflow-skinny包,它是一个不带 SQL 存储、服务器、UI 或数据科学依赖项的轻型 MLflow 包。 对于主要需要 MLflow 跟踪和日志记录功能但不是完整的功能套件(包括部署)的用户,我们建议使用此包。创建 Azure 机器学习工作区。 若要创建工作区,请参阅创建入门所需的资源。 查看在工作区中执行 MLflow 操作所需的 访问权限。
若要执行远程跟踪(即跟踪在 Azure 机器学习以外运行的试验),请将 MLflow 配置为指向 Azure 机器学习工作区的跟踪 URI。 有关如何将 MLflow 连接到工作区的详细信息,请参阅为 Azure 机器学习配置 MLflow。
配置试验
MLflow 组织试验和运行中的信息。 在 Azure 机器学习中,运行称为“作业”。 默认情况下,运行记录到自动创建的名为“默认”的试验,但你可配置要跟踪的试验。
对于交互式训练(如 Jupyter 笔记本中),请使用 MLflow 命令 mlflow.set_experiment()。 例如,以下代码片段会配置一个试验:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
配置运行
Azure 机器学习会跟踪 MLflow 调用运行的训练作业。 使用运行捕获作业执行的所有处理。
以交互方式工作时,一旦你记录需要活动运行的信息,MLflow 就会立即开始跟踪训练例程。 例如,如果启用了 MLflow 的自动记录功能,则记录指标或参数或启动训练周期时,MLflow 跟踪将启动。
但显式启动运行通常很有帮助,特别是在要捕获“持续时间”字段中试验总时间的情况下。 要显式启动运行,请使用 mlflow.start_run()。
无论是否手动启动运行,你最终都需要停止运行,以便 MLflow 知道试验运行已完成,并且可以将运行状态标记为“已完成”。 若要停止运行,请使用 mlflow.end_run()。
以下代码会手动启动运行,并在笔记本末尾结束该运行:
mlflow.start_run()
# Your code
mlflow.end_run()
最好手动启动运行,以免忘记结束运行。 可使用上下文管理器范式来帮助记住结束运行。
with mlflow.start_run() as run:
# Your code
当您开始一个新的运行时使用 mlflow.start_run(),指定 run_name 参数非常有用,该参数随后会被转换为 Azure 机器学习用户界面中的运行名称。 这样做有助于更快地识别运行。
with mlflow.start_run(run_name="hello-world-example") as run:
# Your code
启用 MLflow 自动日志记录
可以使用 MLflow 手动记录指标、参数和文件,还可依赖于 MLflow 的自动日志记录功能。 MLflow 支持的每个机器学习框架都会确定自动跟踪的内容。
若要启用自动日志记录,请在训练代码之前插入以下代码:
mlflow.autolog()
查看工作区中的指标和项目
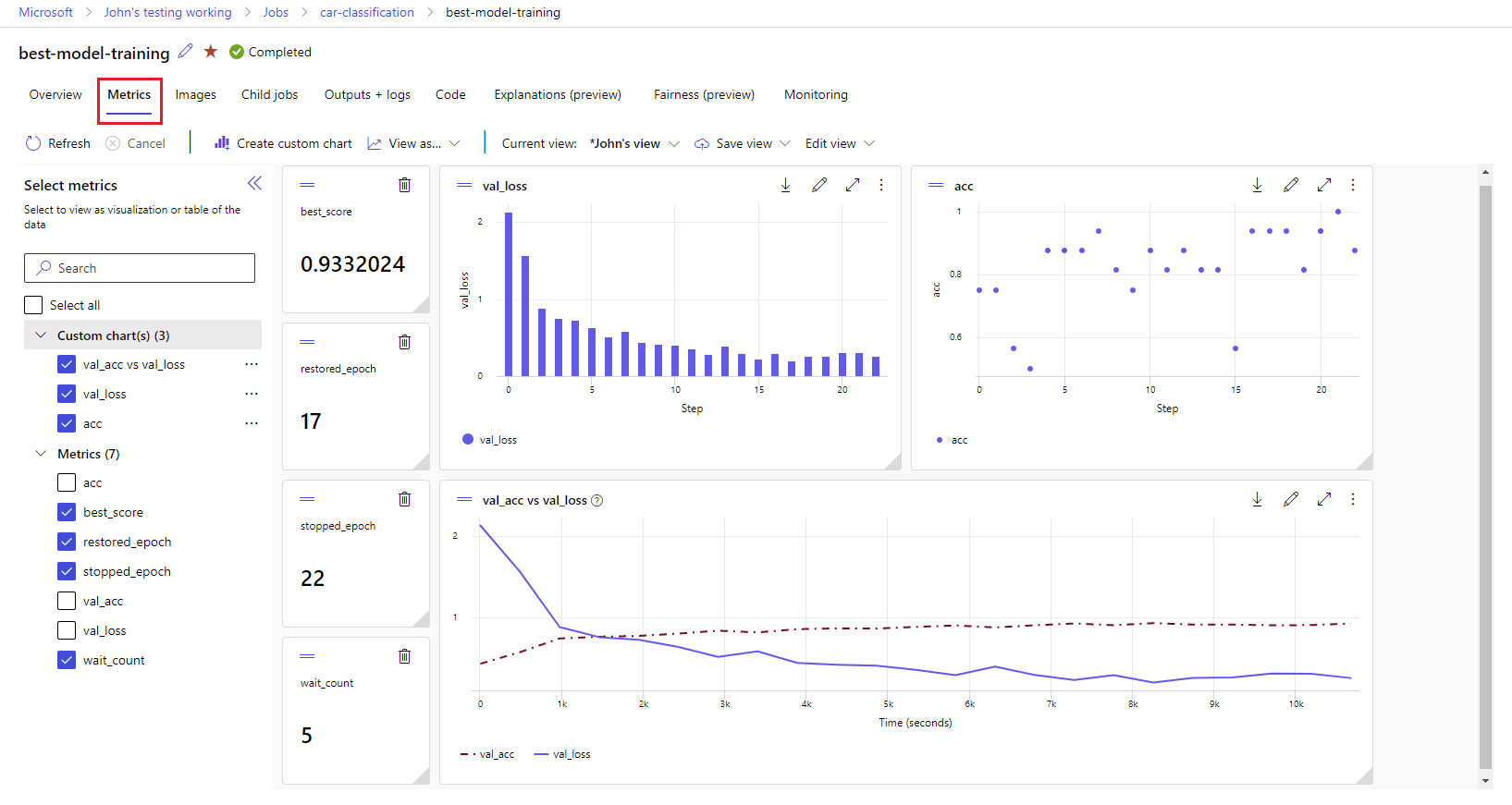
你的工作区中将跟踪 MLflow 记录的指标和项目。 可以在 Azure 机器学习工作室中查看和访问它们,也可以使用 MLflow SDK 以编程方式访问它们。
在工作室中查看指标和工件:
在工作区的“作业”页面上,选择试验名称。
在“试验详细信息”页面上,选择“指标”选项卡。
选择记录的指标以在页面右侧呈现图表。 可以通过应用平滑处理、更改颜色或在单个图形上绘制多个指标来自定义图表。 还可以调整布局的大小和重新排列布局。
创建所需的视图后,保存该视图以供将来使用,并使用直接链接与团队成员共享。

若要使用 MLflow SDK 以编程方式访问或查询指标、参数和项目,请使用mlflow.get_run()。
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
提示
上述示例仅返回给定指标的最后一个值。 若要检索给定指标的所有值,请使用 mlflow.get_metric_history 方法。 若要详细了解如何检索指标值,请参阅从运行中获取参数和指标。
若要下载已记录的项目(如文件和模型),请使用 mlflow.artifacts.download_artifacts()。
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
有关如何使用 MLflow 在 Azure 机器学习中检索或比较试验和运行的信息的详细信息,请参阅 查询和比较试验和运行与 MLflow。