本文介绍了大型语言模型(LLM)如何使用额外的数据来提供更好的答案。 默认情况下,LLM 只知道它在训练期间学到的内容。 可以添加实时或专用数据,使其更有用。
可通过两种主要方法添加此额外数据:
- 检索扩充生成(RAG):使用语义搜索和上下文启动在模型答案之前查找和添加有用的信息。 在 生成生成 AI 解决方案的关键概念和注意事项中了解详细信息。
- 微调:在较小的特定数据集上重新训练 LLM,使其在某些任务或主题上变得更好。
下一节将分解这两种方法。
了解 RAG
RAG 支持关键“通过我的数据聊天”方案。 在此情境中,组织可能拥有大量文本内容,比如文件、文献资料和其他专有数据。 它使用此库作为用户提示答案的基础。
使用 RAG 可以生成聊天机器人,以便使用自己的文档回答问题。 以下是其工作原理:
- 将文档(或部分称为 区块)存储在数据库中
- 为每个区块创建 嵌入 ;描述数字的列表
- 当有人提出问题时,系统会发现类似的区块
- 将相关区块以及问题发送到 LLM 以创建答案
创建矢量化文档的索引
首先生成向量数据存储。 此存储区保存每个文档或区块的嵌入内容。 下图显示了创建文档矢量化索引的主要步骤。

此图显示了 数据管道。 此管道引入数据、处理数据并管理系统数据。 它还为矢量数据库中的存储准备数据,并确保它采用正确的 LLM 格式。
嵌入可推动整个过程。 嵌入是一组数字,表示字词、句子或文档的含义,以便机器学习模型可以使用它们。
创建嵌入的一种方法是将内容发送到 Azure OpenAI 嵌入 API。 API 返回矢量 - 数字列表。 每个数字都描述有关内容的内容,例如其主题、含义、语法或样式。
- 主题问题
- 语义
- 语法和语法
- 字词和短语用法
- 上下文关系
- 样式或音调
所有这些数字一起显示内容位于多维空间的位置。 想象一下 3D 图形,但维度数百或数千。 即使我们不能绘制它,计算机也可以处理这种空间。
教程:在 Azure AI Foundry 模型嵌入和文档搜索中探索 Azure OpenAI 提供了有关如何使用 Azure OpenAI 嵌入 API 为文档创建嵌入的指南。
存储矢量和内容
下一步涉及将矢量和内容(或指向内容位置的指针)和其他元数据存储在向量数据库中。 矢量数据库类似于任何其他类型的数据库,但有两个关键区别:
- 矢量数据库使用向量作为索引来搜索数据
- 矢量数据库通常使用最接近的邻域算法,该算法可以使用 余弦相似性 作为距离指标来查找最接近搜索条件的矢量
借助存储在向量数据库中的文档库,开发人员可以生成一个 检索器组件 来检索与用户查询匹配的文档。 系统使用此数据向 LLM 提供它需要回答用户查询的内容。
通过使用文档来回答查询
RAG 系统首先使用语义搜索来查找撰写答案时可能对 LLM 有帮助的文章。 下一步涉及将匹配的文章与用户的原始提示发送到 LLM 以撰写答案。
下图描绘了一个简单的 RAG 实现(有时称为 天真 RAG):
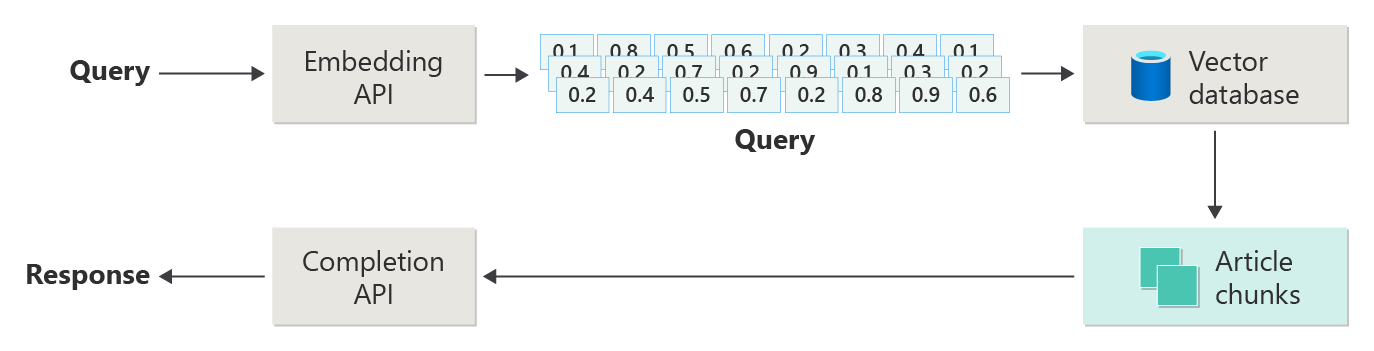
在关系图中,用户提交查询。 首先,系统将用户的提示转换为嵌入。 然后,它会搜索向量数据库以查找与提示最相似的文档或区块。
余弦相似性 通过查看两个向量之间的角度来度量两个向量之间的接近程度。 接近 1 的值表示矢量非常相似;-1 附近的值表示它们大相径庭。 此方法可帮助系统查找包含类似内容的文档。
最近的邻居算法 查找最接近给定点的向量。 最接近的邻居 (KNN) 算法查找最接近的 K 匹配项。 建议引擎等系统通常结合使用 KNN 和余弦相似性来查找用户需求的最佳匹配项。
搜索后,将最佳匹配内容和用户的提示发送到 LLM,以便它可以生成更相关的响应。
挑战和注意事项
RAG 系统具有自身的挑战:
- 数据隐私:负责处理用户数据,尤其是在从外部源检索或处理信息时。
- 计算要求:需要检索和生成步骤才能使用重要的计算资源。
- 准确性和相关性:专注于提供准确的相关响应,并监视数据或模型中的偏差。
开发人员需要解决这些挑战,以构建高效、道德和有价值的 RAG 系统。
若要详细了解如何生成生产就绪的 RAG 系统,请参阅 生成高级检索扩充生成系统。
想要尝试构建生成 AI 解决方案? 开始使用适用于 Python 的自己的数据示例开始聊天。 教程也适用于 .NET、 Java 和 JavaScript。
微调模型
优化在对大型常规数据集进行初始训练后,对较小的特定于域的数据集重新训练 LLM。
在预训练期间,LLM 从广泛的数据中学习语言结构、上下文和常规模式。 微调通过新的重点数据来教授模型,以便它可以更好地执行特定任务或主题。 据了解,模型会更新其权重,以处理新数据的详细信息。
微调的主要优势
- 专用化:微调可帮助模型更好地处理特定任务,例如分析法律文档或医疗文档或处理客户服务。
- 效率:微调使用的数据更少,资源比从头开始训练模型少。
- 适应性:微调使模型能够学习原始训练中未涵盖的新任务或域。
- 改进了性能:微调有助于模型理解新域的语言、样式或术语。
- 个性化:微调可以使模型的响应符合用户或组织的需要或首选项。
限制和挑战
微调还存在一些挑战:
- 数据要求:需要特定任务或域的大型高质量数据集。
- 过度拟合的风险:使用小型数据集,模型在训练数据方面可能表现良好,但对新数据表现不佳。
- 成本和资源:微调仍需要计算能力,尤其是大型模型或数据集。
- 维护和更新:在域更改时需要更新微调的模型。
- 模型偏移:针对特定任务的微调可以使模型在常规语言任务中效率更低。
通过微调自定义模型说明了如何微调模型。
微调 vs.RAG
微调和 RAG 都有助于 LLM 更好地工作,但每种需求都适合不同的需求。 根据目标、数据和计算选择正确的方法,以及是希望模型专门还是保持常规。
何时选择微调
- 特定于任务的性能:在需要特定任务的最佳结果时选择微调,并具有足够的域数据以避免过度拟合。
- 控制数据:如果你有与预先训练的基础模型截然不同的唯一或专有数据,请使用微调。
- 稳定内容:如果你的任务不需要使用最新信息进行常量更新,请选择微调。
何时选择 RAG
- 动态或更改的内容:如果需要最新信息,例如新闻或最近事件,请使用 RAG。
- 广泛的主题覆盖范围:如果希望跨多个主题获得强结果,请选择 RAG,而不仅仅是一个区域。
- 有限的资源:如果没有大量数据或计算来训练,则使用 RAG,并且基础模型已做好了工作。
应用程序设计的最终想法
根据应用需要的内容在微调和 RAG 之间做出决定。 微调最适合专用任务,而 RAG 提供灵活性和 up-to动态方案的日期内容。