你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
本指南提供了有关将自定义命名实体识别(NER)与 Azure AI Foundry 或 REST API 配合使用的分步说明。 使用 NER 可以检测和分类非结构化文本中的实体,例如人员、地点、组织和数字。 使用自定义 NER,可以训练模型,以识别特定于业务的实体,并根据需要对其进行调整。
首先, 示例贷款协议 作为数据集提供,用于生成自定义 NER 模型并提取这些关键实体:
- 协议日期
- 借款人的姓名、地址、城市和州
- 贷款人的姓名、地址、城市和州
- 贷款和利息金额
注意
- 此项目要求你拥有 一个基于 Azure AI Foundry 中心的项目,其中包含一个 Azure 存储帐户 (而不是 Foundry 项目)。 有关详细信息, 请参阅如何创建和管理 Azure AI Foundry 中心
- 如果已有 Azure AI 语言或多服务资源(无论是单独使用还是通过 Language Studio 使用),则可以在 Azure AI Foundry 门户中继续使用这些现有语言资源。 有关详细信息,请参阅 如何在 Azure AI Foundry 门户中使用 Azure AI 服务。
Prerequisites
一个 Azure 订阅。 如果没有帐户,可以免费创建一个帐户。
必需权限。 确保在订阅级别将负责建立帐户和项目的人员分配为 Azure AI 帐户拥有者角色。 若在订阅范围内具有 参与者 或 认知服务参与者 角色,也可以满足此要求。 有关详细信息,请参阅基于角色的访问控制(RBAC)。
包含存储帐户的 Azure AI 语言资源。 在“选择其他功能”页上,选择“自定义文本分类”、“自定义命名实体识别”、“自定义情绪分析”和“自定义健康文本分析”,以将所需的存储帐户与此资源链接:

注意
- 需要在资源组上分配 所有者 角色才能创建语言资源。
- 如果要连接预先存在的存储帐户,应为其分配所有者角色。
- 一旦与语言资源链接,请不要将存储帐户移到其他资源组或订阅。
基于 Azure AI Foundry 中心的项目。 有关基于 Foundry 中心的项目的详细信息, 请参阅为 Azure AI Foundry 创建中心项目。
上传到存储容器的自定义 NER 数据集。 自定义命名实体识别(NER)数据集是用于训练自定义 NER 模型的标记文本文档的集合。 可以 下载本快速入门的示例数据集 。 源语言为英语。
步骤 1:配置所需的角色、权限和设置
让我们首先配置您的资源。
启用自定义命名实体识别功能
确保在 Azure 门户中启用自定义文本分类/自定义命名实体识别功能。
- 转到Azure 门户中的语言资源。
- 在左侧菜单中,在 “资源管理 ”部分下,选择“ 功能”。
- 确保已启用 自定义文本分类/自定义命名实体识别 功能。
- 如果未分配存储帐户,请选择并连接存储帐户。
- 选择应用。
为 Azure AI 语言资源添加所需的角色
在 Azure 门户中转到你的存储帐户或语言资源。
在左窗格中选择 “访问控制”(IAM )。
选择“添加”以打开添加角色分配,然后为您的帐户选择相应的角色。
- 应为语言资源分配 认知服务语言所有者 或 认知服务参与者 角色。
在“将访问权限分配给”中,选择“用户、组或服务主体”。
选择“选择成员”。
选择 用户名。 可在“选择”字段中搜索用户名。 对所有角色重复此步骤。
对需要访问此资源的所有用户帐户重复这些步骤。
为存储帐户添加所需的角色
- 转到 Azure 门户中的存储帐户页。
- 在左窗格中选择 “访问控制”(IAM )。
- 选择“添加”以添加角色分配,然后选择存储帐户上的“存储 Blob 数据参与者”角色。
- 在 “分配访问权限”中,选择 “托管标识”。
- 选择“选择成员”。
- 选择您的订阅,并选择Language作为托管标识。 可以在 “选择” 字段中搜索语言资源。
添加所需的用户角色
重要说明
如果跳过此步骤,尝试连接到自定义项目时会出现 403 错误。 重要的是,即使你是存储帐户的所有者,当前用户也必须具有此角色才能访问存储帐户 blob 数据。
- 转到 Azure 门户中的存储帐户页。
- 在左窗格中选择 “访问控制”(IAM )。
- 选择“添加”以添加角色分配,然后选择存储帐户上的“存储 Blob 数据参与者”角色。
- 在“将访问权限分配给”中,选择“用户、组或服务主体”。
- 选择“选择成员”。
- 选择你的用户。 可在“选择”字段中搜索用户名。
重要说明
如果您有防火墙、虚拟网络或专用终结点,请确保在 Azure 门户的网络选项卡中选择“允许受信任的服务列表中的 Azure 服务访问此存储帐户”。

步骤 2:将数据集上传到存储容器
接下来,添加容器并将数据集文件直接上传到存储容器的根目录。 这些文档用于训练模型。
将容器添加到与语言资源关联的存储帐户。 有关详细信息, 请参阅创建容器。
从 GitHub 下载示例数据集。 提供的示例数据集包含 20 个贷款协议:
- 每份协议包括两方:贷方和借方。
- 提取相关信息:双方、协议日期、贷款金额和利率。
打开 .zip 文件,然后解压缩包含文档的文件夹。
导航到 Azure AI Foundry。
如果尚未登录,门户会提示你使用 Azure 凭据执行此作。
登录后,访问为本快速入门所准备的基于 Azure AI Foundry 中心的现有项目。
从左侧导航菜单中选择 管理中心 。
从管理中心菜单的“Hub”部分选择“已连接资源”。
接下来,选择设置为连接资源的工作区 Blob 存储。
在工作区 Blob 存储中,选择 ‘在 Azure 门户中查看’。
在 Blob 存储的 AzurePortal 页上,从顶部菜单中选择 “上传 ”。 接下来,选择之前下载的
.txt和.json文件。 最后,选择“ 上传 ”按钮,将文件添加到容器。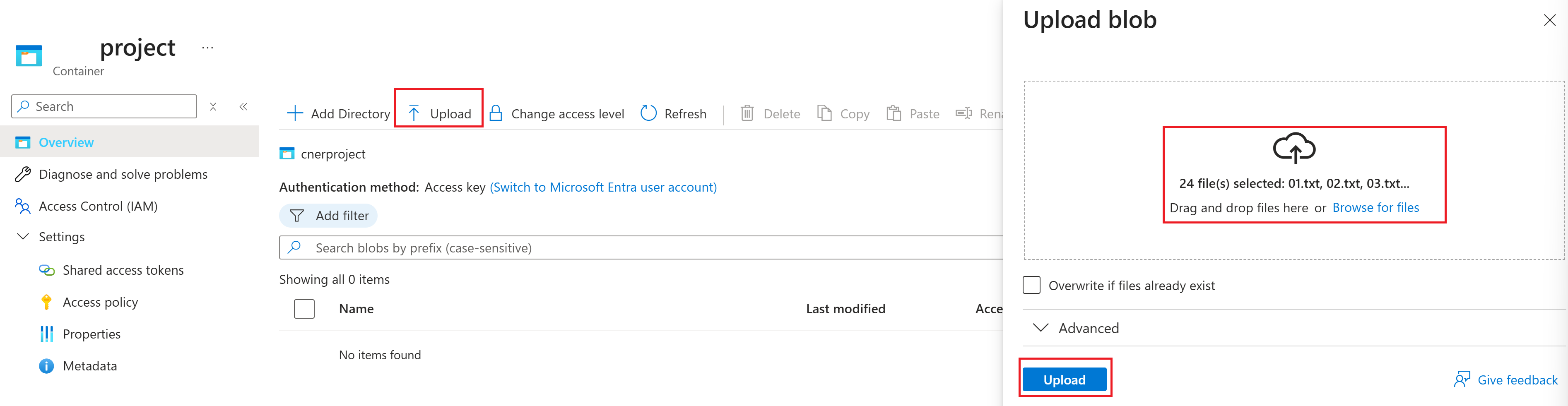
在 Azure 门户中预配和配置所需的 Azure 资源后,让我们在 Azure AI Foundry 中使用这些资源来创建经过微调的自定义命名实体识别(NER)模型。
步骤 3:连接 Azure AI 语言资源
接下来,我们将创建与 Azure AI 语言资源的连接,以便 Azure AI Foundry 可以安全地访问它。 此连接提供安全的标识管理和身份验证,以及对数据的受控和隔离访问。
返回到 Azure AI Foundry。
在本次快速入门中,访问您基于 Azure AI Foundry 中心的现有项目。
从左侧导航菜单中选择 管理中心 。
从管理中心菜单的“Hub”部分选择“已连接资源”。
在主窗口中,选择“ + 新建连接 ”按钮。
从“将连接添加到外部资产”窗口中选择“Azure AI 语言”。
选择 “添加连接”,然后选择“ 关闭”。

步骤 4:微调自定义 NER 模型
现在,我们已准备好创建自定义 NER 微调模型。
从管理中心菜单的“项目”部分,选择“转到项目”。
从 “概述 ”菜单中,选择 “微调”。
在主窗口中,选择“AI 服务微调”选项卡,然后选择“+ 微调”按钮。
在 “创建服务微调 ”窗口中,选择“ 自定义命名实体识别 ”选项卡,然后选择“ 下一步”。

在 “创建服务微调任务 ”窗口中,完成字段,如下所示:
连接服务。 默认情况下,语言服务资源的名称应已在此字段中显示。 如果不是,请从下拉菜单添加它。
名称。 请为微调任务项目命名。
语言。 英语设置为默认值,并且已在字段中显示。
说明。 可以选择提供说明或将此字段留空。
Blob 存储容器。 从 步骤 2 中选择工作区 Blob 存储容器,然后选择 “连接 ”按钮。
最后,选择“创建”按钮。 创建操作可能需要几分钟才能完成。

步骤 5:训练模型

- 在 “入门 ”菜单中,选择“ 管理数据”。 在 “添加用于训练和测试的数据 ”窗口中,可以看到之前上传到 Azure Blob 存储容器的示例数据。
- 接下来,从 “入门 ”菜单中,选择“ 训练模型”。
- 选择“ + 训练模型”按钮。 显示 “训练新模型 ”窗口时,输入新模型的名称并保留默认值。 选择“下一步”按钮。
- 在“训练新模型”窗口中,将默认的“自动从训练数据中拆分测试集”选项保持启用,建议训练数据设置为80%,测试数据设置为20%。
- 查看模型配置,然后选择“ 创建 ”按钮。
- 训练模型后,可以从“入门”菜单中选择“评估模型”。 可以从 “评估模型 ”窗口中选择模型,并在必要时进行改进。
步骤 6:部署模型
一般情况下,在训练模型后,你会查看其评估详细信息。 对于此快速入门,只需部署模型并使其可在语言操场中进行测试,或者通过调用预测 API 进行测试。 但是,如果需要,可以花点时间从左侧菜单中选择“评估模型”,并浏览模型的深入遥测数据。 完成以下步骤,在 Azure AI Foundry 中部署模型。
在左侧菜单中,选择“部署模型”。
接下来,从“部署模型”窗口中选择“➕部署已训练的模型”。

确保已选择“创建新部署”按钮。
填写“部署已训练的模型”窗口字段:
- 部署名称。 为模型命名。
- 分配模型。 从下拉菜单中选择已训练的模型。
- 区域。 从下拉菜单中选择一个区域。
最后,选择“创建”按钮。 部署模型可能需要几分钟时间。
成功部署后,可以在“部署模型”页上查看模型的部署状态。 显示的到期日期表示部署模型将不再可用于预测任务的日期。 部署训练配置后,此日期通常为 18 个月。

步骤 7:试用语言体验区
语言场提供了一个沙盒,用于在将模型部署到生产环境之前对其进行测试和配置,而无需编写代码。
- 在顶部菜单栏中,选择“在操场中试用”。
- 在“语言演练”窗口中,选择 “自定义命名实体识别 ”磁贴。
- 在“配置”部分中,从下拉菜单中选择项目名称和部署名称。
- 输入实体并选择“ 运行”。
- 可以在“ 详细信息” 窗口中评估结果。
完成了,恭喜!
在本快速入门中,你创建了经过微调的自定义 NER 模型,在 Azure AI Foundry 中部署了该模型,并在语言场中测试了模型。
清理资源
如果不再需要项目,可以从 Azure AI Foundry 将其删除。
- 导航到 Azure AI Foundry 主页。 除非已完成此步骤且会话处于活动状态,否则请通过登录来启动身份验证过程。
- 从“继续使用 Azure AI Foundry 构建”中选择要删除的项目。
- 选择“管理中心”。
- 选择“ 删除项目”。
删除中心及其所有项目:
导航到“中心”部分中的“概述”选项卡。
在右侧,选择 “删除中心”。
该链接将打开 Azure 门户,以便在那里删除中心。
Prerequisites
- Azure 订阅 - 免费创建订阅
创建新的 Azure AI 语言资源和 Azure 存储帐户
在使用自定义命名实体识别(NER)之前,需要创建一个 Azure AI 语言资源,该资源提供创建项目并开始训练模型所需的凭据。 还需要一个 Azure 存储帐户,可以在其中上传用于生成模型的数据集。
重要说明
若要快速开始,建议创建新的 Azure AI 语言资源。 使用本文中提供的步骤创建语言资源,并同时创建和/或连接存储帐户。 同时创建这两者比稍后创建要容易得多。
如果有想要使用的预先存在的资源,则需要将其连接到存储帐户。 有关信息,请参阅创建项目。
从 Azure 门户创建新资源
若要创建新的 Azure AI 语言资源,请登录 Azure 门户。
在出现的窗口中,从自定义功能中选择“自定义文本分类和自定义命名实体识别”。 单击屏幕底部的“继续创建资源”。
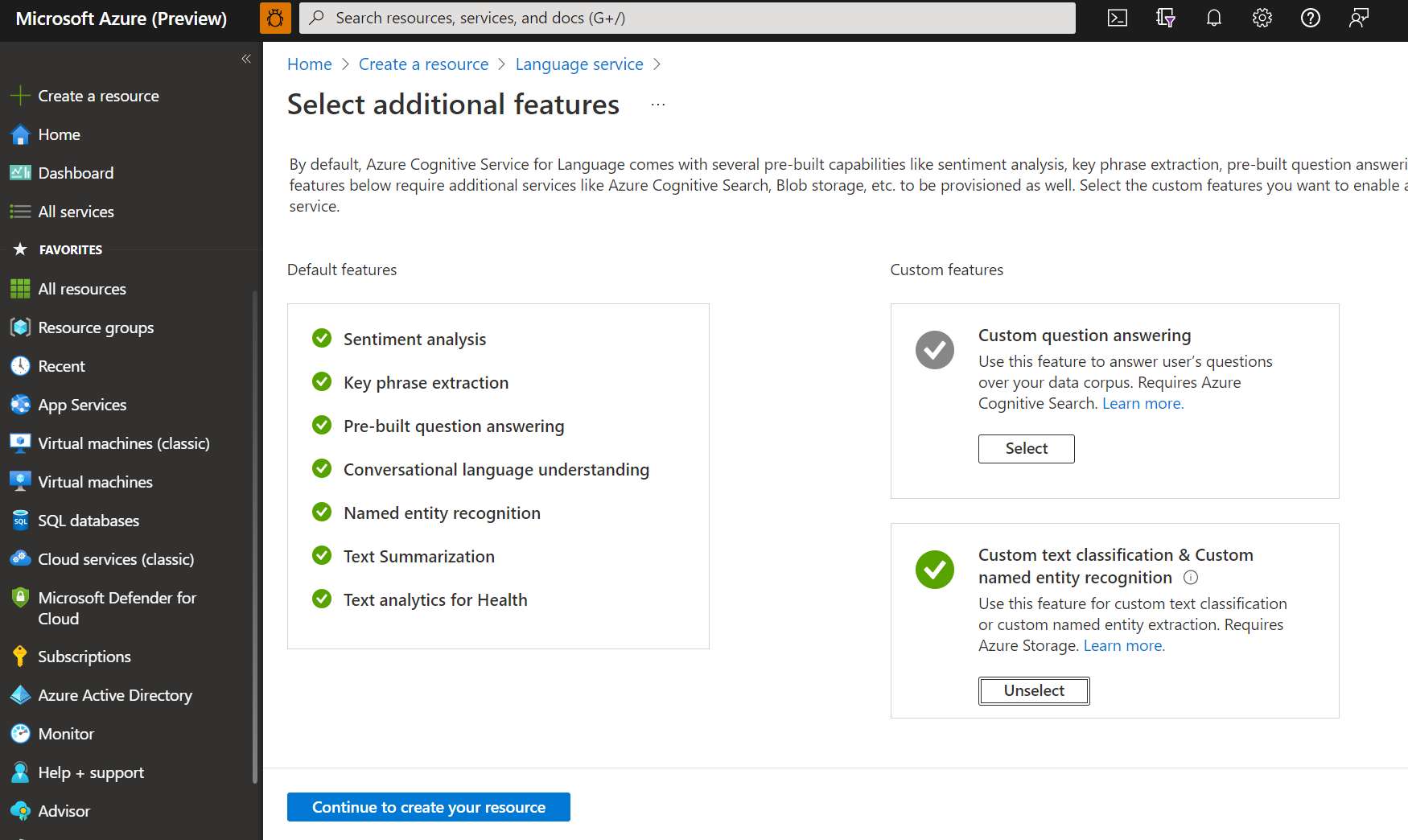
创建包含以下详细信息的语言资源。
名称 说明 订阅 Azure 订阅。 资源组 将包含资源的资源组。 可以使用现有资源组,也可以新建一个。 区域 语言资源的区域。 例如,“美国西部 2”。 名称 资源的名称。 定价层 语言资源的定价层。 可以使用免费 (F0) 定价层试用该服务。 注意
如果收到一条消息“登录帐户不是所选存储帐户资源组的所有者”,则帐户需要在资源组上分配一个所有者角色,然后才能创建语言资源。 请联系 Azure 订阅所有者寻求帮助。
在“自定义文本分类和自定义命名实体识别”部分,选择现有存储帐户或选择“新建存储帐户”。 这些值用于帮助你快速入门,不一定是你希望在生产环境中使用的存储帐户值。 为避免在生成项目时出现延迟,请连接到与语言资源位于同一区域的存储帐户。
存储帐户值 建议的值 存储帐户名称 任何名称 存储帐户类型 标准 LRS 确保选中“负责任的 AI 通知”。 在页面底部选择“查看 + 创建”,然后选择“创建”。

将示例数据上传到 Blob 容器
创建 Azure 存储帐户并将其连接到语言资源后,需要将示例数据集中的文档上传到容器的根目录。 稍后将使用这些文档来训练模型。
从 GitHub 下载示例数据集。
打开 .zip 文件,然后解压缩包含文档的文件夹。
在 Azure 门户中,导航到你创建的存储帐户,然后选择它。
在存储帐户中,从位于“数据存储”下方的左侧菜单中选择“容器”。 在出现的屏幕上,选择“+ 容器”。 将容器命名为“example-data”并保留默认的“公共访问级别”。

创建容器后,选择该容器。 然后选择“上传”按钮以选择之前下载的 和
.txt文件.json。


提供的样本数据集包含 20 个贷款协议。 每份协议包括两方:贷方和借方。 你可使用提供的示例文件来提取双方的相关信息、协议日期、贷款金额以及利率。
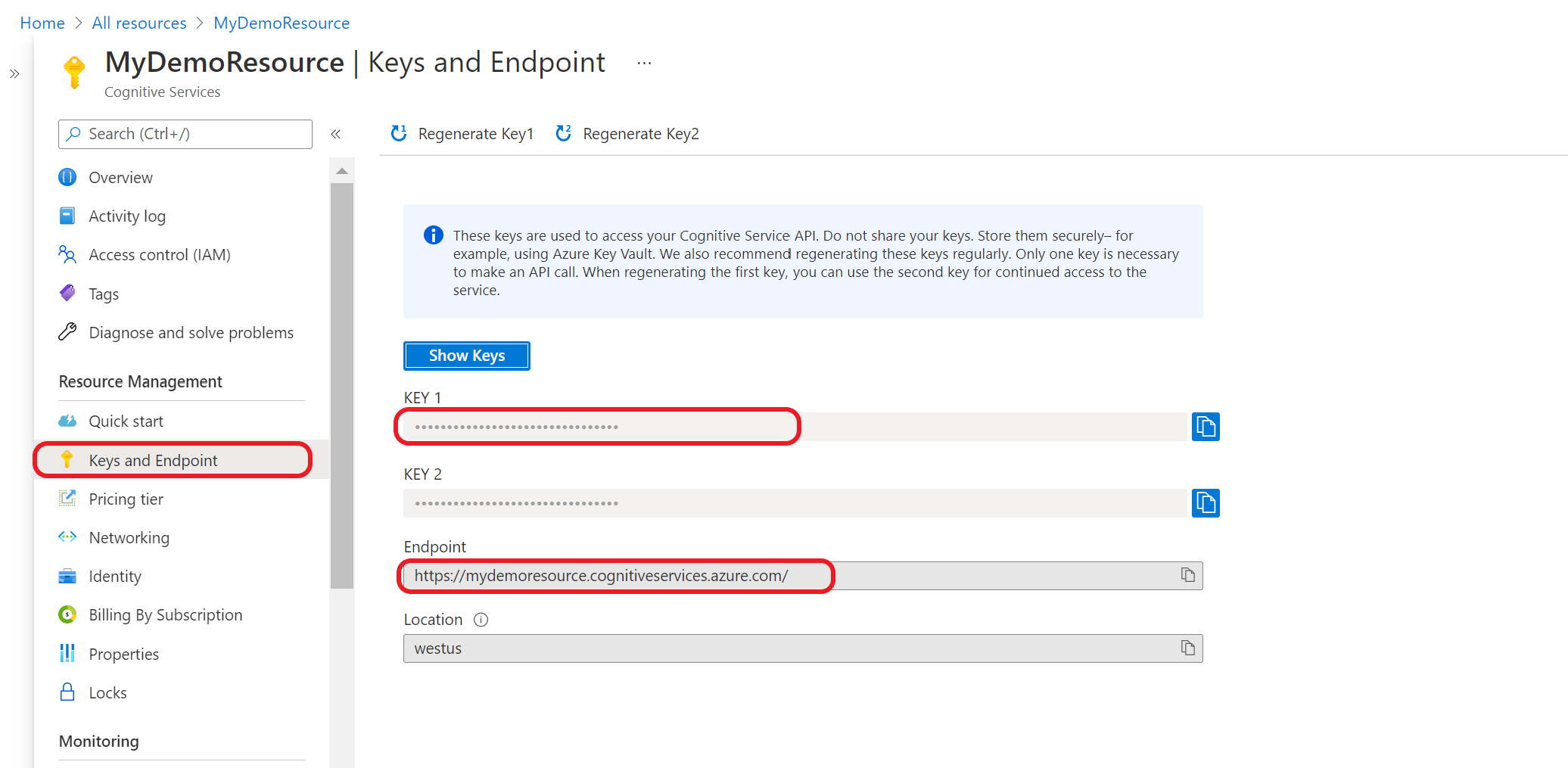
获取资源密钥和终结点
在 Azure 门户中,转到资源概述页
在左侧菜单中,选择"密钥和终结点”。 你将为 API 请求使用终结点和密钥

创建自定义 NER 项目
在配置资源和存储帐户后,创建新的自定义 NER 项目。 项目是一个工作区,用于基于你的数据构建自定义 ML 模型。 你的项目由你和有权访问所用语言资源的其他人访问。
使用在上一步中从示例数据下载的标记文件,并将其添加到以下请求的正文中。
触发导入项目作业
使用以下 URL、标头和 JSON 正文提交 POST 请求,以导入标签文件。 请确保标签文件遵循接受的格式。
如果已存在同名的项目,则替换该项目的数据。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | myProject |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于已发布的最新版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
Body
在请求中使用以下 JSON。 将占位符值替换为你自己的值。
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomEntityRecognition",
"description": "Trying out custom NER",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomEntityRecognition",
"entities": [
{
"category": "Entity1"
},
{
"category": "Entity2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
api-version |
{API-VERSION} |
要调用的 API 的版本。 此处使用的版本必须与 URL 中的 API 版本相同。 详细了解其他可用的 API 版本 | 2022-03-01-preview |
projectName |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | myProject |
projectKind |
CustomEntityRecognition |
项目类型。 | CustomEntityRecognition |
language |
{LANGUAGE-CODE} |
指定项目中所使用文档的语言代码的字符串。 如果项目是多语言项目,请选择大多数文档 的语言代码 。 | en-us |
multilingual |
true |
通过布尔值,你可以在数据集中有多种语言的文档,并且在部署模型时可以使用任何支持的语言(不一定包含在训练文档中)查询模型。 如需了解多语言支持,请参阅语言支持。 | true |
storageInputContainerName |
{CONTAINER-NAME} | 包含已上传文档的 Azure 存储容器的名称。 | myContainer |
entities |
一个数组,其中包含项目中拥有和从文档中提取的所有实体类型。 | ||
documents |
一个数组,其中包含项目中的所有文档和每个文档中标记的实体列表。 | [] | |
location |
{DOCUMENT-NAME} |
存储容器中文档的位置。 | doc1.txt |
dataset |
{DATASET} |
此文件在训练前拆分时将归类到的测试集。 有关详细信息, 请参阅如何训练模型。 此字段的可能值为 Train 和 Test。 |
Train |
发送 API 请求后,会收到一个 202 响应,指示作业已正确提交。 在响应头中,提取 operation-location 值。 下面是格式的示例:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 用于标识请求,因为此操作是异步操作。 使用此 URL 获取导入作业状态。
此请求可能出现的错误场景:
- 所选资源不具有该存储帐户的适当权限。
- 指定的
storageInputContainerName不存在。 - 使用了无效的语言代码,或者语言代码类型不是字符串。
-
multilingual值是一个字符串,而不是布尔值。
获取导入作业状态
使用以下 GET 请求获取导入项目的状态。 将以下占位符值替换为你自己的值。
请求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | myProject |
{JOB-ID} |
用于查找模型训练状态的 ID。 该值位于你在上一步骤中收到的 location 标头值中。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
训练模型
通常,在创建项目后,将继续开始标记连接到项目的容器中的文档。 在本快速入门中,你已导入示例标记数据集,并使用示例 JSON 标记文件初始化项目。
启动训练作业
导入项目后,可以开始训练模型。
使用以下 URL、标头和 JSON 正文提交 POST 请求以提交训练作业。 将以下占位符值替换为你自己的值。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | myProject |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
请求正文
在请求正文中使用以下 JSON。 完成训练后,该模型将命名为 {MODEL-NAME}。 只有成功的训练作业才会生成模型。
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
成功训练后,便会将模型名称分配给模型。 | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
这是用于训练模型的模型版本。 | 2022-05-01 |
| evaluationOptions | 用于将数据拆分为训练集和测试集的选项。 | {} |
|
| kind | percentage |
拆分方法。 可能的值为 percentage 或 manual。 有关详细信息,请参阅如何训练模型。 |
percentage |
| trainingSplitPercentage | 80 |
要包含在训练集中的已标记数据的百分比。 建议的值为 80。 |
80 |
| testingSplitPercentage | 20 |
要包含在测试集中的已标记数据的百分比。 建议的值为 20。 |
20 |
注意
仅当 trainingSplitPercentage 设置为 testingSplitPercentage 时 Kind 和 percentage 才是必需的,并且两个百分比的总和应等于 100。
发送 API 请求后,你将收到 202 响应,这表明作业已正确提交。 在响应头中,提取 location 值。 其格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 用于标识请求,因为此操作是异步操作。 可以使用此 URL 获取训练状态。
获取训练作业状态
对于该示例数据集,训练可能需要 10 - 30 分钟。 可使用以下请求继续轮询训练作业的状态,直到成功完成。
使用以下 GET 请求来获取模型训练过程的状态。 将以下占位符值替换为你自己的值。
请求 URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | myProject |
{JOB-ID} |
用于查找模型训练状态的 ID。 该值位于你在上一步骤中收到的 location 标头值中。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
响应正文
发送请求后,你将获得以下响应。
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
部署模型
通常,训练模型后,你会查看其评估详细信息,并在必要时进行改进。 在本快速入门中,只需部署模型,并使其可用于在 Language Studio 中试用,也可以调用 预测 API。
启动部署作业
使用以下 URL、标头和 JSON 正文提交 PUT 请求,以提交部署作业。 将以下占位符值替换为你自己的值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | myProject |
{DEPLOYMENT-NAME} |
部署的名称。 此值区分大小写。 | staging |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
请求正文
在请求正文中使用以下 JSON。 使用要分配给部署的模型名称。
{
"trainedModelLabel": "{MODEL-NAME}"
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
将要分配给部署的模型名称。 只能分配已成功训练的模型。 此值区分大小写。 | myModel |
发送 API 请求后,你将收到 202 响应,这表明作业已正确提交。 在响应头中,提取 operation-location 值。 其格式如下:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} 用于标识请求,因为此操作是异步操作。 可使用此 URL 获取部署状态。
获取部署作业状态
使用以下 GET 请求来查询部署作业的状态。 可以使用在上一步中收到的 URL,或者将下面的占位符值替换为你自己的值。
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 | myProject |
{DEPLOYMENT-NAME} |
部署的名称。 此值区分大小写。 | staging |
{JOB-ID} |
用于查找模型训练状态的 ID。 它包含在上一步骤中收到的 location 标头值中。 |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
Ocp-Apim-Subscription-Key |
资源的密钥。 用于对 API 请求进行身份验证。 |
响应正文
发送请求后,你将获得以下响应。 继续轮询此终结点,直到“状态”参数变为“已成功”。 应获取一个 200 代码来指示请求的成功。
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
提取自定义实体
部署模型后,可以开始使用模型通过预测 API 从文本中提取实体。 在前面下载的示例数据集中,可以找到可在此步骤中使用的一些测试文档。
提交自定义 NER 任务
使用此 POST 请求启动文本分类任务。
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
| 密钥 | 值 |
|---|---|
| Ocp-Apim-Subscription-Key | 你的密钥,用于提供对此 API 的访问权限。 |
Body
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomEntityRecognition",
"taskName": "Entity Recognition",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| 密钥 | 占位符 | 值 | 示例 |
|---|---|---|---|
displayName |
{JOB-NAME} |
你的作业名称。 | MyJobName |
documents |
[{},{}] | 要对其运行任务的文档列表。 | [{},{}] |
id |
{DOC-ID} |
文档名称或 ID。 | doc1 |
language |
{LANGUAGE-CODE} |
指定文档语言代码的字符串。 如果未指定此键,该服务将采用在创建项目时选择的项目默认语言。 有关支持的语言代码的列表,请参阅语言支持。 | en-us |
text |
{DOC-TEXT} |
要对其运行任务的文档任务。 | Lorem ipsum dolor sit amet |
tasks |
要执行的任务列表。 | [] |
|
taskName |
CustomEntityRecognition |
任务名称 | CustomEntityRecognition |
parameters |
要传递给任务的参数列表。 | ||
project-name |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
部署的名称。 此值区分大小写。 | prod |
响应
你将收到 202 响应,它指示任务已成功提交。 在响应头中,提取 operation-location。
operation-location 的格式如下:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
可以使用此 URL 查询任务完成状态,并在任务完成时获取结果。
获取任务结果
使用以下 GET 请求查询自定义实体识别任务的状态/结果。
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
| 密钥 | 值 |
|---|---|
| Ocp-Apim-Subscription-Key | 你的密钥,用于提供对此 API 的访问权限。 |
响应正文
响应将是具有以下参数的 JSON 文档
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "EntityRecognitionLROResults",
"taskName": "Recognize Entities",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"category": "Event",
"confidenceScore": 0.61,
"length": 4,
"offset": 18,
"text": "trip"
},
{
"category": "Location",
"confidenceScore": 0.82,
"length": 7,
"offset": 26,
"subcategory": "GPE",
"text": "Seattle"
},
{
"category": "DateTime",
"confidenceScore": 0.8,
"length": 9,
"offset": 34,
"subcategory": "DateRange",
"text": "last week"
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
清理资源
当你不再需要项目时,可以使用以下 DELETE 请求将其删除。 将占位符值替换为你自己的值。
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| 占位符 | 值 | 示例 |
|---|---|---|
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
项目的名称。 此值区分大小写。 | myProject |
{API-VERSION} |
要调用的 API 的版本。 此处引用的值适用于最新发布的版本。 请参阅模型生命周期,了解有关其他可用 API 版本的详细信息。 | 2022-05-01 |
头文件
使用以下标头对请求进行身份验证。
| 密钥 | 值 |
|---|---|
| Ocp-Apim-Subscription-Key | 资源的密钥。 用于对 API 请求进行身份验证。 |
发送 API 请求后,你将收到指示成功的 202 响应,这意味着项目已被删除。 带有用于检查作业状态的 Operation-Location 标头的成功调用结果。
相关内容
创建实体提取模型后,可以使用 运行时 API 提取实体。
创建自定义 NER 项目时,请使用我们的操作指南文章详细了解如何标记、训练和应用模型: