你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
溢出通过将超额部分路由到相应的标准部署来管理预配部署的流量波动。 溢出是一项可选功能,可为给定部署上的所有请求设置,也可以按请求进行管理。 启用溢出后,Azure AI Foundry 模型中的 Azure OpenAI 会将任何超额流量从预配部署发送到标准部署进行处理。
注释
溢出当前不适用于 响应 API。
先决条件
需要预先配置的托管部署和标准部署。
预配部署和标准部署必须位于同一 Azure OpenAI 资源中,才有资格进行溢出。
标准部署的数据处理级别必须与预配的部署相匹配(例如,全局预配部署必须与全局标准溢出部署一起使用)。
何时在预配置的部署上启用溢出
若要最大化利用您的预配部署,可以为所有全局和数据区的预配部署启用溢出。 通过溢出,流量的突发或波动可由服务自动管理。 此功能可降低完全利用预配部署时遇到中断的风险。 或者,溢出是按请求配置的,可以跨不同的方案和工作负荷提供灵活性。 溢出现在还可用于 Azure AI Foundry 智能体服务。
溢出何时生效?
当你为某个部署启用了溢出功能,或为特定的推理请求配置了该功能时,在以下任意场景中,一旦某个推理请求返回了非 200 响应代码,溢出机制就会启动:
预配的吞吐量单位(PTU)已完全使用,因此产生
429响应代码。你发送一个长上下文令牌请求,导致出现
400错误代码。 例如,使用gpt 4.1序列模型时,PTU 仅支持小于 128k 的上下文长度,并返回 HTTP 400。处理请求时出现服务器错误,导致错误代码
500或503。
当请求导致出现其中一个非200 响应码时,Azure OpenAI 会自动将请求从预配的部署发送到标准部署进行处理。
注释
即使请求的子集路由到标准部署,服务也会优先将请求发送到预配的部署,然后再将任何超额请求发送到标准部署,这可能会导致额外的延迟。
如何判断一个请求是否发生了溢出
以下 HTTP 响应标头表明某个请求超出限制:
x-ms-spillover-from-<deployment-name>。 此标头包含 PTU 部署名称。 此标头的存在表明请求是溢出请求。x-ms-<deployment-name>。 此标头包含为请求提供服务的部署的名称。 如果请求溢出,则部署名称是标准部署的名称。
对于溢出的请求,如果出于任何原因标准部署请求失败,则会在响应客户时使用原始 PTU 响应。 客户看到一个标头 x-ms-spillover-error ,其中包含溢出请求的响应代码(例如 429 或 500),以便他们知道失败溢出的原因。
溢出如何影响成本?
由于溢出使用预配部署和标准部署的组合来管理流量波动,因此溢出计费涉及两个组件:
对于通过预配部署处理的任何请求,仅应用每小时预配部署的费用。 这些请求不会产生额外的费用。
对于路由到标准部署的任何请求,请求按关联的输入令牌、缓存令牌和指定模型版本和部署类型的输出令牌费率计费。
为预配部署上的所有请求启用溢出
若要部署具有溢出功能的模型,请导航到 Azure AI Foundry。 在左侧导航菜单上,选择“ 部署”。
选择 “部署模型”。 在显示的菜单中,选择“ 自定义”。

将预配选项指定为 部署类型,例如 全局预配吞吐量。 选择 “流量溢出” ,为预配的部署启用溢出。
小窍门
- 若要启用溢出,帐户必须至少有一个与当前预配部署的模型和版本匹配的活动即用即付部署。
- 若要查看如何为选择推理请求启用溢出,请单击上面的 REST API 选项卡。

如何监视溢出使用情况?
由于溢出功能依赖于预配部署和标准部署的组合来管理流量超额,因此可以在每个部署的部署级别进行监视。 若要查看主要预配部署与溢出标准部署上处理的请求数,请应用 Azure Monitor 指标中的拆分功能,以查看每个部署处理的请求及其各自的状态代码。 同样,拆分功能可用于查看在给定时间段内主要预配部署处理的令牌数量与溢出标准部署处理的数量。 有关 Azure OpenAI 中的可观测性的详细信息,请查看 Monitor Azure OpenAI 文档。
在 Azure 门户中监视指标
以下 Azure Monitor 指标图表提供了在启动溢出时在主要预配部署与溢出标准部署之间拆分请求的示例。 若要创建图表,请在 Azure 门户中导航到资源。
从左侧导航菜单中选择监控>指标。
添加请求指标
Azure OpenAI Requests。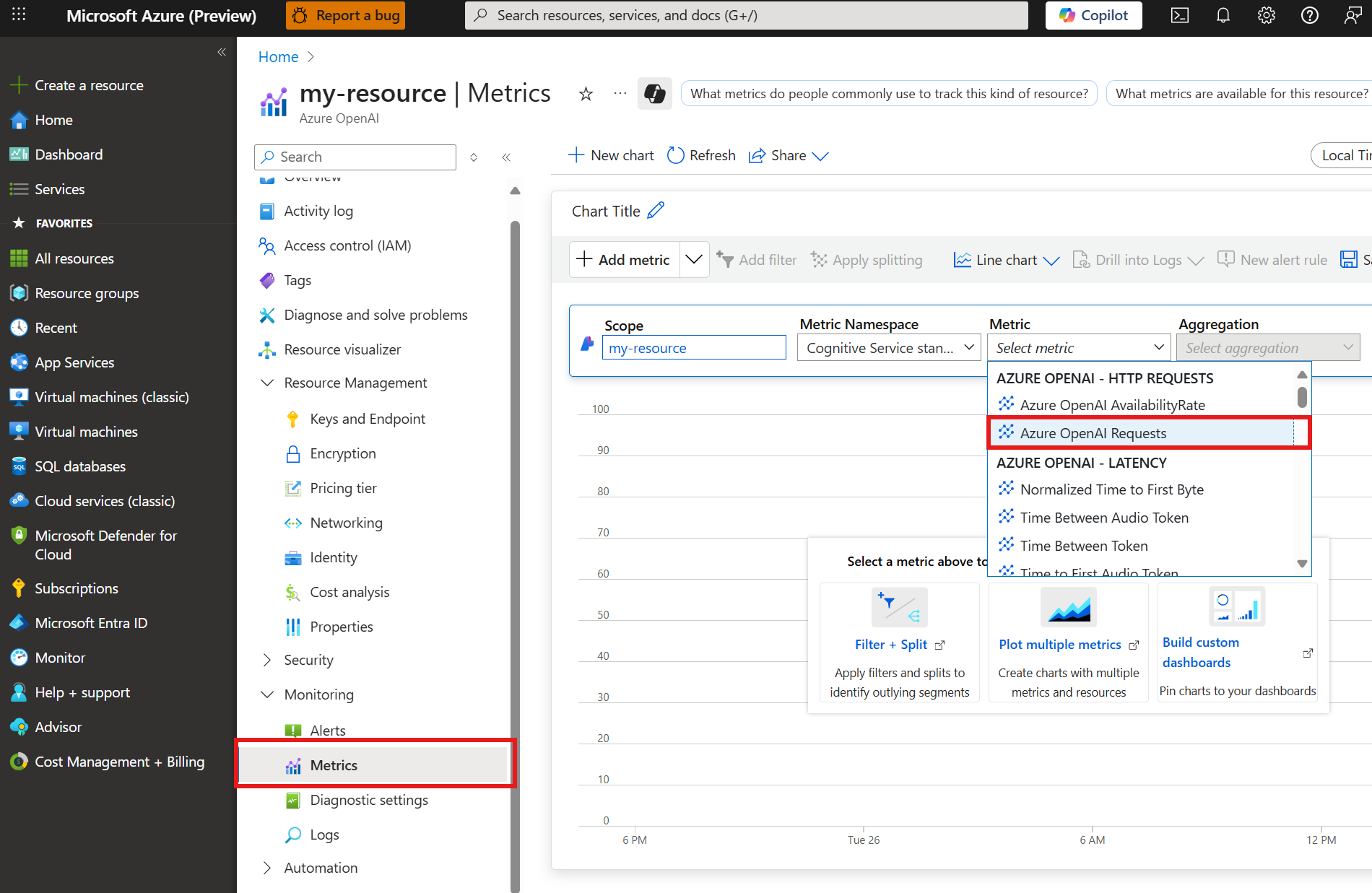
选择“应用拆分”并将
ModelDeploymentName拆分和StatusCode拆分应用于Azure OpenAI Requests指标。 这将为您显示一个包含响应代码的图表,其中200是(成功),429是(请求过多),这些代码是为您的资源生成的。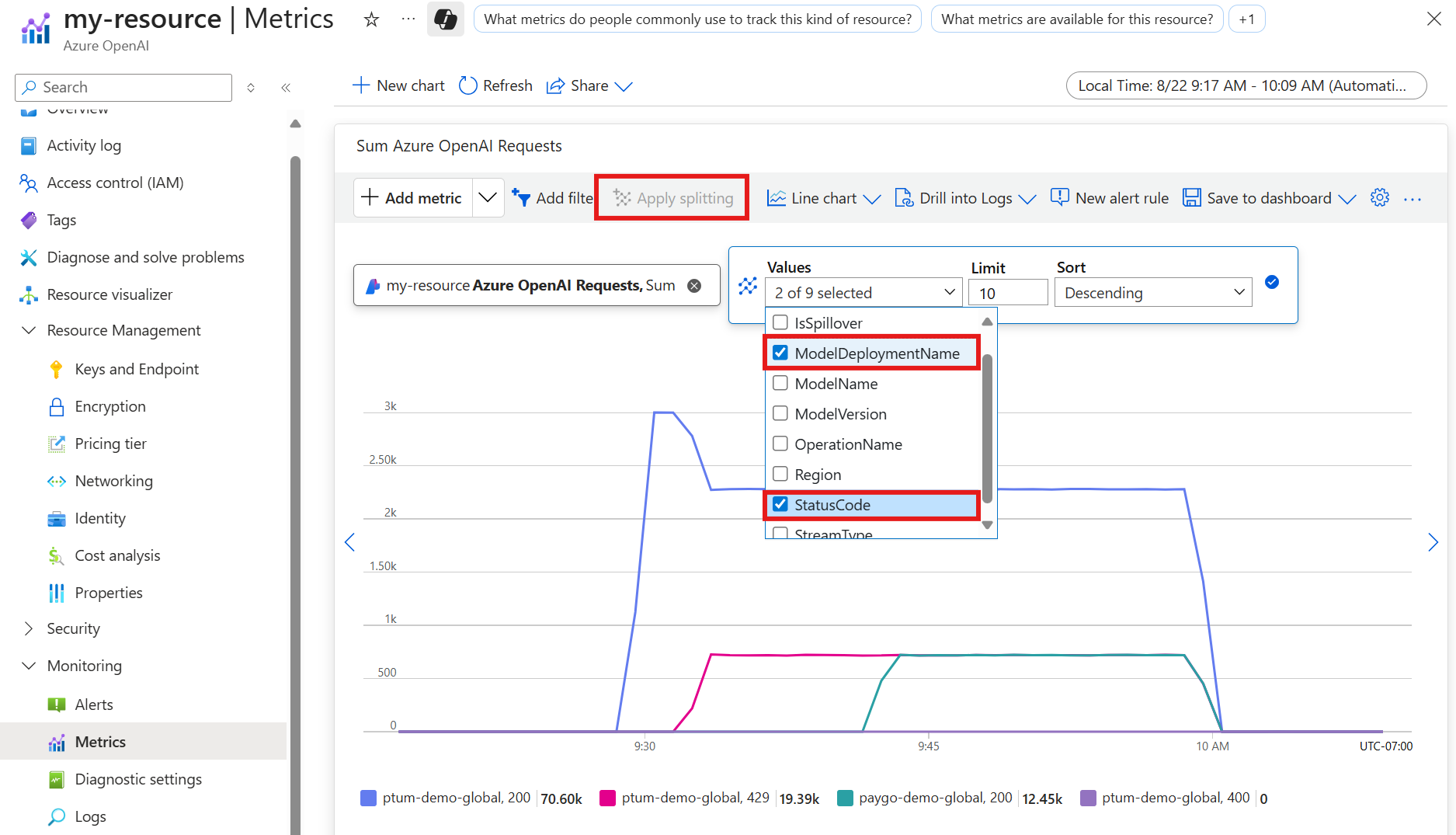
在应用
ModelDeploymentName拆分时请务必添加要查看的模型部署。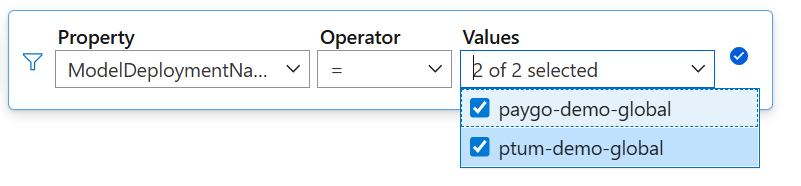
以下示例展示了在请求量激增时,发送到已预置吞吐量部署的实例如何生成
429错误代码。 溢出发生后不久,请求将开始发送到用于溢出的即用即付部署,从而为该部署生成200响应。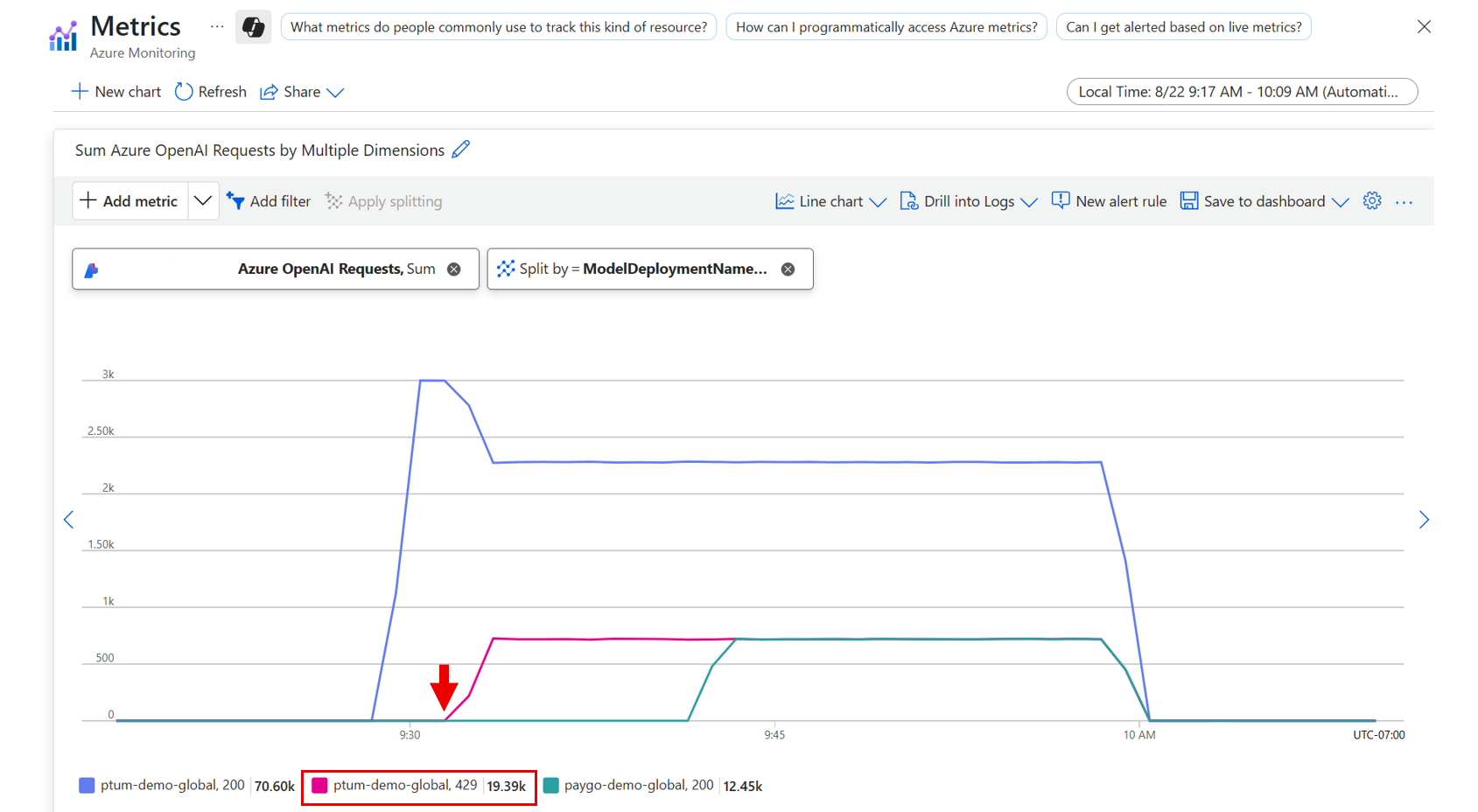
注释
当请求发送到即用即付部署时,在重定向之前,它们仍会在预配的部署上生成 429 个响应代码。






查看溢出指标
通过应用 IsSpillover 拆分,可以查看重定向到溢出部署的请求。 在前面的示例中,可以看到来自主部署的 429 响应如何与溢出部署生成的 200 响应代码相匹配。
