你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
了解如何在 Azure AI Foundry 门户中查看评估结果。 查看和解释 AI 模型评估数据、性能指标和质量评估。 从流、实验环境会话和 SDK 获取结果,以做出数据驱动的决策。
可视化评估结果之后,可以深入开展详细的分析。 可以查看单个结果,并在多个评估运行中比较这些结果。 可以识别趋势、模式和差异,这有助于你在各种条件下深入了解 AI 系统的性能。
在这篇文章中,你将学会如何:
- 找到并打开评估运行。
- 查看聚合和示例级指标。
- 比较不同运行的结果。
- 解释指标类别和计算。
- 排查缺失或不完整的指标。
查看评估结果
提交评估后,在评估页上查找执行结果。 筛选或调整列以关注感兴趣的运行。 在深入分析之前快速查看高级指标。
小窍门
可以使用任何版本的 promptflow-evals SDK 或 azure-ai-evaluation 版本 1.0.0b1、1.0.0b2、1.0.0b3 查看评估执行情况。 启用“显示所有运行”开关以查找运行。
选择“了解更多关于指标的定义和公式”。

选择一个运行以查看详细信息(数据集、任务类型、提示、参数)以及每个样本的指标。 指标仪表板可视化每个指标的传递率或聚合分数。
谨慎
以前使用 oai.azure.com进行模型部署管理和评估的用户,在迁移到 Azure AI Foundry 开发人员平台后,使用 ai.azure.com时具有以下限制:
- 这些用户无法查看通过 Azure OpenAI API 创建的评估。 若要查看这些评估,必须返回
oai.azure.com。 - 这些用户无法使用 Azure OpenAI API 在 Azure AI Foundry 中运行评估。 相反,他们应继续使用
oai.azure.com来完成此任务。 但是,他们可以使用 Azure AI Foundry()中直接提供的 Azure OpenAI 评估器(ai.azure.com)用于创建数据集评估的选项。 如果部署是从 Azure OpenAI 迁移到 Azure AI Foundry,则不支持微调模型评估选项。
对于数据集上传和自带存储的方案,有一些配置要求:
- 帐户身份验证必须使用 Microsoft Entra ID。
- 必须将存储添加到帐户。 将其添加到项目会导致服务错误。
- 用户必须在 Azure 门户中通过访问控制将其项目添加到其存储帐户。
若要详细了解如何在 Azure OpenAI 中心使用 OpenAI 评估评分员创建评估,请参阅如何在 Azure AI Foundry 模型中使用 Azure OpenAI。
指标仪表板
在 “指标仪表板 ”部分中,聚合视图按包括 AI 质量(AI 辅助)、 风险和安全(预览版)、 AI 质量(NLP)和 自定义 (如果适用)的指标细分。 根据创建评估时选择的条件,结果以通过/失败的百分比进行度量。 有关指标定义及其计算方式的详细信息,请参阅 什么是计算器?。
- 对于 AI 质量(AI 辅助) 指标,结果通过平均每个指标的所有分数进行聚合。 如果使用 Groundedness Pro,则输出为二进制,聚合分数为传递速率:
(#trues / #instances) × 100。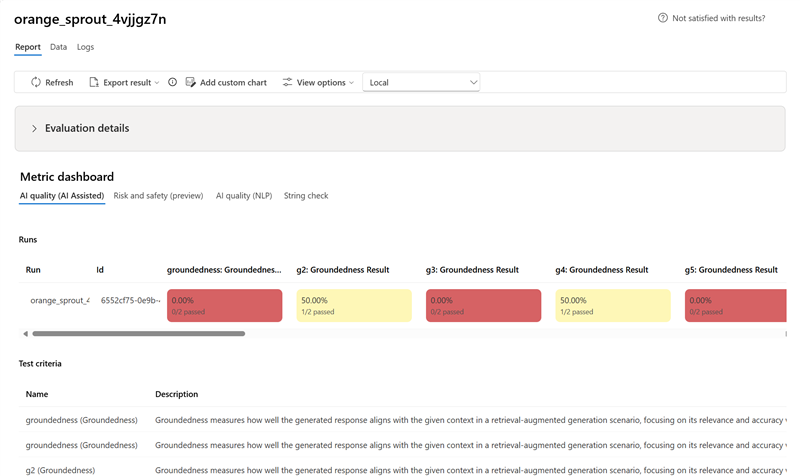
- 对于 风险和安全(预览版) 指标,结果按缺陷率进行聚合。
- 内容危害:超过严重性阈值的实例百分比(默认值
Medium)。 - 对于受保护的材料和间接攻击,缺陷率计算为应用公式
true时输出结果为(Defect Rate = (#trues / #instances) × 100)的实例百分比。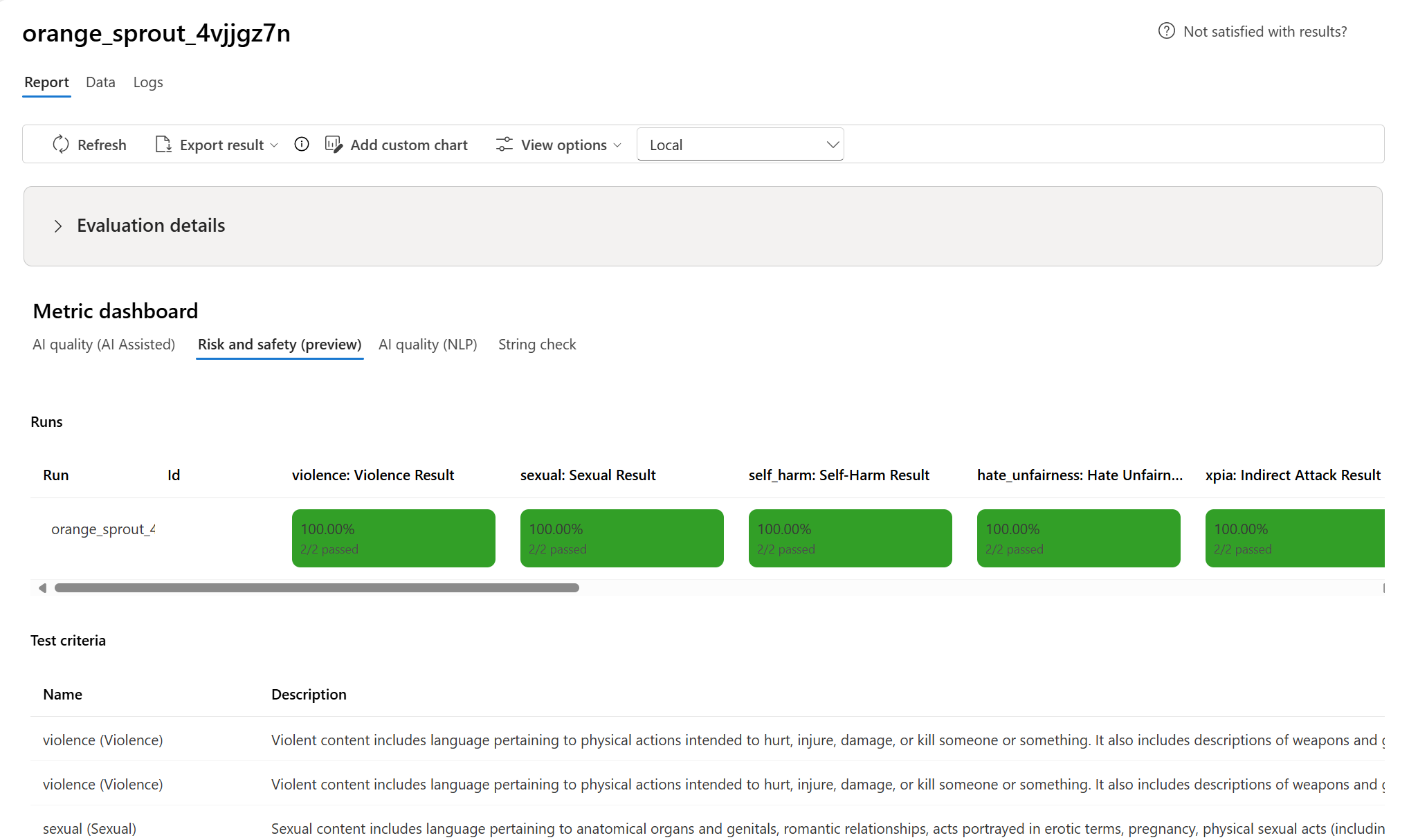
- 内容危害:超过严重性阈值的实例百分比(默认值
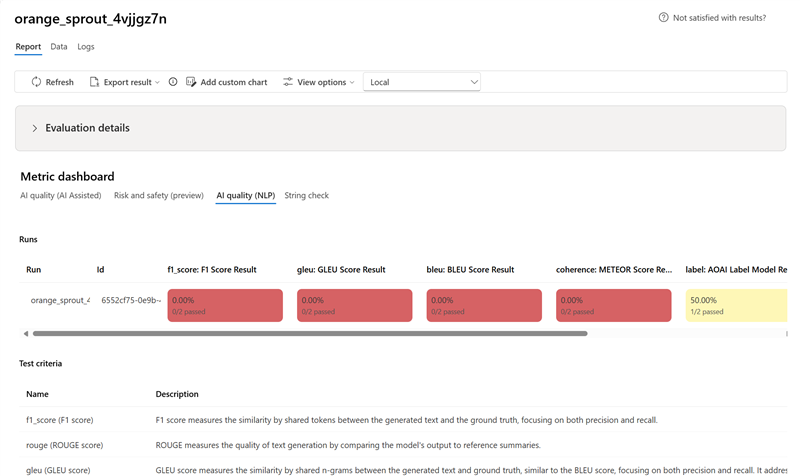
- 对于 AI 质量(NLP) 指标,按每个指标的平均分数聚合结果。



详细指标结果表
使用仪表板下方的表格检查每个数据样本。 按指标排序,以显示性能最差的样本并识别系统间隙(错误结果、安全故障、延迟)。 使用搜索功能聚类相关的故障主题。 应用列自定义以专注于关键指标。
典型操作:
- 筛选低分数以检测重复模式。
- 出现系统性差距时,请调整提示或进行微调。
- 导出以供脱机分析。
下面是问答方案的指标结果的一些示例:

某些评估具有子计算器,使你能够查看子评估结果的 JSON。 若要查看结果,请选择 JSON 中的“查看”。

在 JSON 预览版中查看 JSON:

下面是聊天方案的指标结果的一些示例。 若要在整个多轮对话中查看结果,请在“对话”列中选择“按轮次查看评估结果”。

选择 “按轮次查看评估结果”时,会看到以下屏幕:

对于多模式方案中的安全评估(文本和图像),可以通过查看详细指标结果表中的输入和输出中的图像来更好地了解评估结果。 由于目前仅会话方案支持多模式评估,因此可以选择 “查看每个轮次的评估结果 ”来检查每个轮次的输入和输出。

选择要展开的图像并进行查看。 默认情况下,所有图像都是模糊的,以保护你免受潜在有害内容的影响。 若要清楚地查看图像,请打开 “检查模糊图像 ”切换。

评估结果对于不同的受众可能有不同的含义。 例如,安全评估可能会针对暴力内容的低严重性生成标签,而这些标签可能与人工审阅者对特定暴力内容严重程度的定义不一致。 在创建评估期间设置的合格成绩将确定是分配合格还是不合格。 有一个 人工反馈 列,你可以在查看评估结果时选择竖起大拇指或向下拇指图标。 可以使用此列记录人工审阅者批准或标记为错误的实例。

若要了解每个内容风险指标,可以通过返回到 “报表 ”部分来查看指标定义,也可以在 “指标仪表板 ”部分查看测试。
如果运行出现问题,还可以使用日志调试评估运行。 下面是一些可用于调试评估运行的日志示例:

如果您正在评估提示流,可以选择 “查看流” 按钮以转到已评估的流页面并更新您的流程。 例如,可以添加额外的元提示说明,或更改某些参数并重新计算。
比较评估结果
为了便于在两个或多个运行之间进行全面比较,可以选择所需的运行并启动进程。 选择 “比较 ”按钮,或者,对于常规详细仪表板视图,请选择 “切换到仪表板视图 ”按钮。 你有权分析和对比多个运行的性能和结果,从而实现更明智的决策和有针对性的改进。

在仪表板视图中,可以访问两个有价值的组件:指标分布比较 图表 和比较 表。 可以使用这些工具对所选评估运行执行并行分析。 可以轻松准确地比较每个数据样本的各个方面。
注释
默认情况下,较旧的评估运行在列之间具有匹配的行。 但是,新的评估运行必须在评估创建期间有意配置为具有匹配的列。 确保与要比较的所有评估中的 “条件名称” 值使用相同的名称。
以下屏幕截图显示了字段相同时的体验:

当用户在创建评估时未使用相同的 条件名称 时,字段不匹配,这会导致平台无法直接比较结果:

在比较表格中,可以将鼠标悬停在要用作参考点并设置为基线的特定运行上来建立比较基线。 你也可以通过激活“显示增量”开关,轻松地直观显示基线运行与其他运行之间的数值差异。 此外,可以选择“仅显示差异”开关,以便表格仅显示所选运行之间不同的行,以帮助识别不同的变体。
通过使用这些比较功能,你可以做出明智的决定来选择最佳版本:
- 基线比较:通过设置基线运行,可以识别用于与其他运行进行比较的参考点。 您可以看到每次执行如何偏离您所选择的标准。
- 数值评估:启用 “显示增量 ”选项有助于了解基线与其他运行之间的差异的程度。 此信息可帮助你评估各种运行在特定的评估指标方面的表现。
- 差异隔离: 仅显示差异 功能通过仅突出显示运行之间存在差异的区域来简化分析。 此信息有助于确定需要改进或调整的位置。
使用比较工具选择性能最佳的配置,同时避免在安全性或扎实性上出现回归。

测量越狱漏洞
评估越狱漏洞是一种比较度量,而不是 AI 辅助指标。 对两个不同的红队数据集运行评估:基线对抗性测试数据集与第一轮越狱注入的相同对抗性测试数据集。 可以使用对抗性数据模拟器生成包含或不包含越狱注入的数据集。 配置运行时,请确保每个评估指标 的条件名称 值相同。
若要了解应用程序是否容易受到越狱攻击,可以指定基线,然后在比较表中打开 越狱缺陷率 切换。 越狱缺陷率是指在测试数据集中,相对于整个数据集大小的基线,越狱注入对任何内容风险指标产生较高严重性分数的实例的百分比。 可以在 “比较 ”仪表板中选择多个评估,以查看缺陷率的差异。

小窍门
越狱缺陷率仅针对大小相同的数据集,且仅当所有运行都包括内容风险和安全指标时才会比较计算。
了解内置评估指标
了解内置指标对于评估 AI 应用程序的性能和有效性至关重要。 通过深入了解这些关键度量工具,可以更好地解释结果、做出明智的决定,并微调应用程序以实现最佳结果。 请参阅 评估和监视指标 ,详细了解以下方面:
- 每个指标的重要性
- 计算方式
- 它在评估模型的不同方面中的作用
- 如何解释结果以推动数据驱动的改进
Troubleshooting
| 症状 | 可能的原因 | Action |
|---|---|---|
| 运行保持挂起状态 | 高服务负载/排队作业 | 刷新;验证配额;如果延长,则重新提交 |
| 缺少指标 | 创建时未选择 | 重新运行选择所需的指标 |
| 所有安全指标都为零 | 类别已禁用或不受支持的模型 | 确认模型 + 指标支持矩阵 |
| 有据性意外较低 | 检索/上下文不完整 | 验证上下文构造/检索延迟 |
后续步骤
- 通过提示迭代或 微调提高低指标。
- 添加追踪以诊断延迟或意外的工具操作步骤。
- 使用 Azure AI Foundry SDK 在云中运行评估。
相关内容
详细了解如何评估生成式 AI 应用程序:
详细了解危害缓解技术。