你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure AI Foundry 门户 模型目录 提供 1,600 多个模型。 部署这些模型的一种常见方法是使用托管计算部署选项。 此选项有时也称为托管联机部署。
部署大型语言模型(LLM)时,可以将其用于网站、应用程序或其他生产环境。 部署通常涉及到将模型托管在服务器或云中,并创建 API 或其他接口供用户与模型交互。 你可以调用部署来实时推理生成式 AI 应用程序(例如聊天和 Copilot)。
本文介绍如何使用托管计算部署选项部署模型,并针对已部署的模型执行推理。
先决条件
具有有效付款方式的 Azure 订阅。 免费或试用 Azure 订阅不起作用。 如果没有 Azure 订阅,请先创建一个付费的 Azure 帐户。
如果没有项目, 请创建一个基于中心的项目。
来自合作伙伴和社区的 Foundry 模型需要访问 Azure 市场,而由 Azure 直接销售的 Foundry 模型不需要此要求。 确保 Azure 订阅具有订阅 Azure 市场中模型产品/服务所需的权限。 请参阅 “启用 Azure 市场购买 ”了解详细信息。
Azure 基于角色的访问控制(Azure RBAC)允许访问 Azure AI Foundry 门户的操作权限。 若要执行本文中的步骤,必须为用户帐户分配资源组的“Azure AI 开发人员”角色。 有关权限详细信息,请参阅 Azure AI Foundry 门户中基于角色的访问控制。
在模型目录中查找模型
- 登录到 Azure AI Foundry。
- 如果你还没有进入你的项目,请选择它。
- 从左窗格中选择 “模型目录 ”。
在“部署选项”筛选器中,选择“托管计算”。
小窍门
由于可以在 Azure AI Foundry 门户中 自定义左窗格 ,因此你可能会看到与这些步骤中显示的项不同。 如果未看到要查找的内容,请选择 ... 左窗格底部的更多内容。
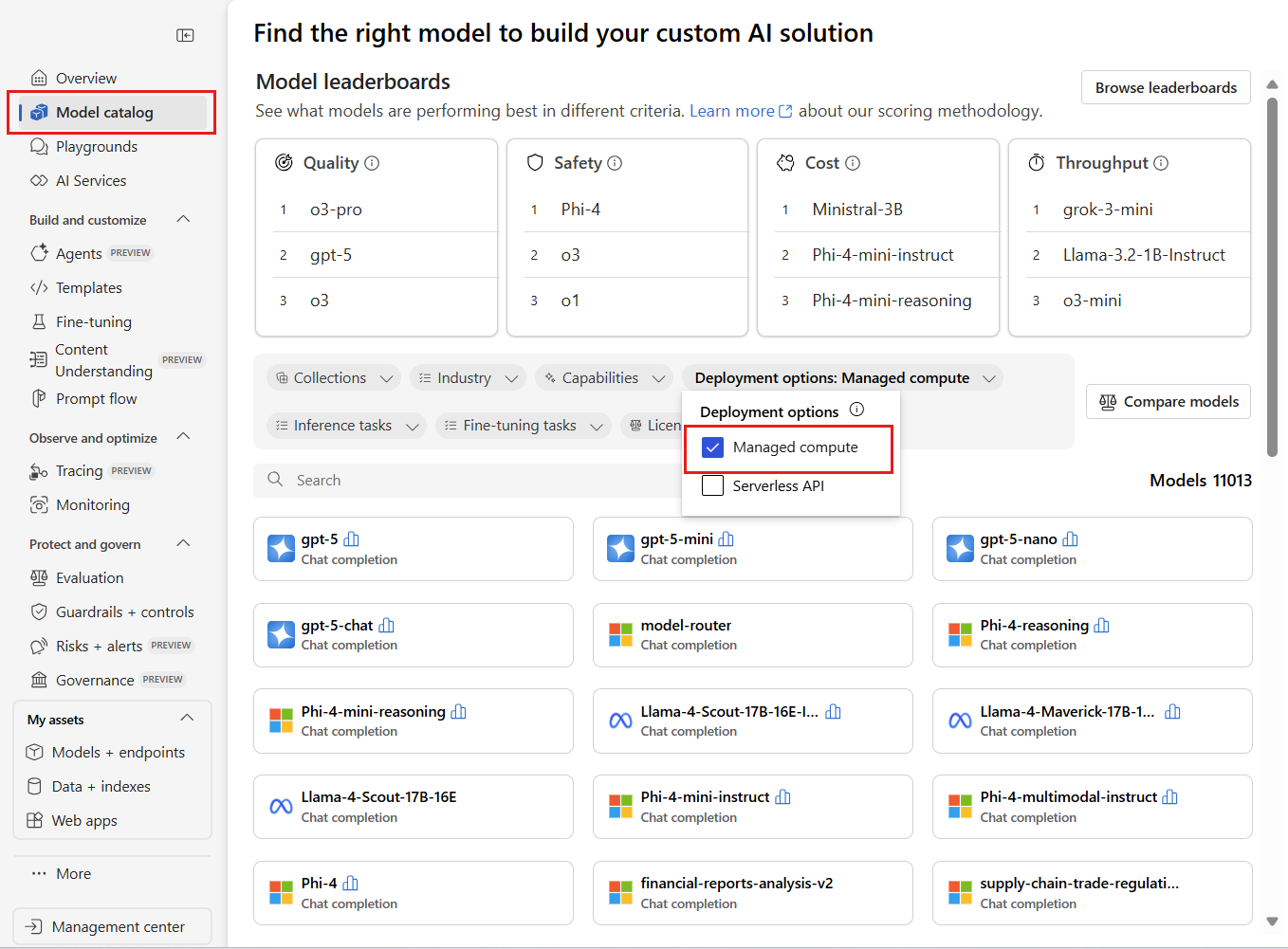
选择一个模型以打开其模型卡。 在本文中,请使用模型
deepset-roberta-base-squad2。

部署模型
在模型的页面中,选择“ 使用此模型 ”打开部署窗口。
部署窗口预先填充了一些选择和参数值。 可以保留它们,也可以根据需要更改它们。 还可以为部署选择现有终结点或创建新的终结点。 对于此示例,请指定实例计数
1并为部署创建新终结点。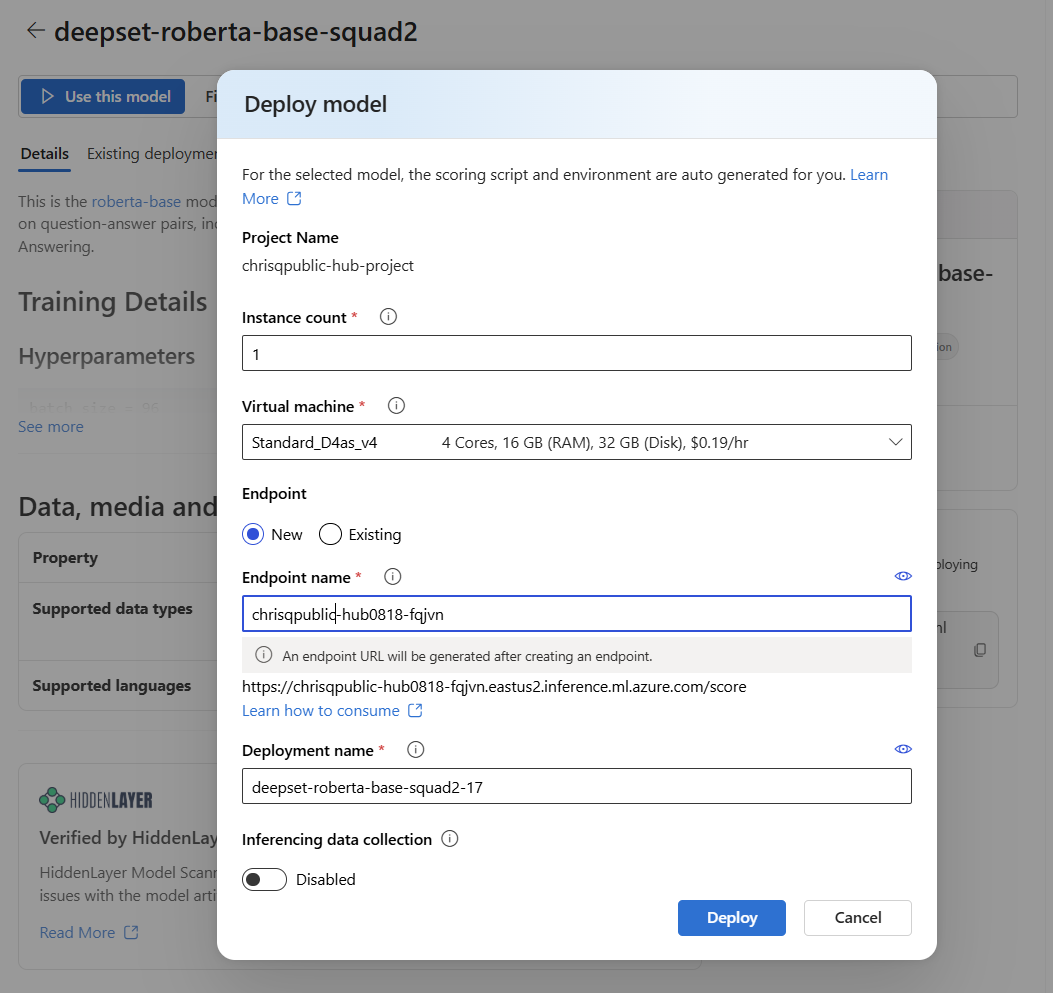
选择 “部署 ”以创建部署。 创建过程可能需要几分钟才能完成。 完成后,门户将打开模型部署页。
小窍门
若要查看部署到项目的终结点,请转到左窗格的 “我的资产 ”部分,然后选择 “模型 + 终结点”。
创建的终结点使用密钥身份验证进行授权。 若要获取与给定终结点关联的密钥,请执行以下步骤:
- 选择部署,并记下终结点的目标 URI 和密钥。
- 使用这些凭据调用部署并生成预测。

使用部署
创建部署后,请按照以下步骤使用部署:
- 在 Azure AI Foundry 项目中的“我的资产”部分下选择“模型 + 终结点”。
- 从 “模型部署 ”选项卡中选择部署。
- 转到“ 测试 ”选项卡,获取对终结点的示例推理。
- 返回到“ 详细信息 ”选项卡,复制部署的“目标 URI”,可以使用该 URI 通过代码运行推理。
- 转到部署的“使用”选项卡,查找可供使用的代码示例。
- 从所选模型的详细信息页面中复制模型 ID。 对于所选模型,它如下所示:
azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/17
部署模型
安装 Azure 机器学习 SDK。
pip install azure-ai-ml pip install azure-identity使用 Azure 机器学习进行身份验证并创建客户端对象。 请将占位符替换为你的订阅 ID、资源组名称和 Azure AI Foundry 项目名称。
from azure.ai.ml import MLClient from azure.identity import InteractiveBrowserCredential workspace_ml_client = MLClient( credential=InteractiveBrowserCredential, subscription_id="your subscription ID goes here", resource_group_name="your resource group name goes here", workspace_name="your project name goes here", )创建终结点。 对于托管计算部署选项,需要在模型部署之前创建一个终结点。 将终结点视为可容纳多个模型部署的容器。 终结点名称在区域中必须唯一,因此在本示例中,使用时间戳创建唯一的终结点名称。
import time, sys from azure.ai.ml.entities import ( ManagedOnlineEndpoint, ManagedOnlineDeployment, ProbeSettings, ) # Make the endpoint name unique timestamp = int(time.time()) online_endpoint_name = "customize your endpoint name here" + str(timestamp) # Create an online endpoint endpoint = ManagedOnlineEndpoint( name=online_endpoint_name, auth_mode="key", ) workspace_ml_client.online_endpoints.begin_create_or_update(endpoint).wait()创建部署。 将下一个代码中的模型 ID 替换为从模型目录部分的“ 查找模型 ”部分中选择的模型的详细信息页复制的模型 ID。
model_name = "azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/17" demo_deployment = ManagedOnlineDeployment( name="demo", endpoint_name=online_endpoint_name, model=model_name, instance_type="Standard_DS3_v2", instance_count=2, liveness_probe=ProbeSettings( failure_threshold=30, success_threshold=1, timeout=2, period=10, initial_delay=1000, ), readiness_probe=ProbeSettings( failure_threshold=10, success_threshold=1, timeout=10, period=10, initial_delay=1000, ), ) workspace_ml_client.online_deployments.begin_create_or_update(demo_deployment).wait() endpoint.traffic = {"demo": 100} workspace_ml_client.online_endpoints.begin_create_or_update(endpoint).result()
推理部署
需要使用示例 json 数据来测试推理。 使用以下示例创建
sample_score.json。{ "inputs": { "question": [ "Where do I live?", "Where do I live?", "What's my name?", "Which name is also used to describe the Amazon rainforest in English?" ], "context": [ "My name is Wolfgang and I live in Berlin", "My name is Sarah and I live in London", "My name is Clara and I live in Berkeley.", "The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species." ] } }使用
sample_score.json进行推理。 根据保存示例 json 文件的位置,更改下一个代码中评分文件的位置。scoring_file = "./sample_score.json" response = workspace_ml_client.online_endpoints.invoke( endpoint_name=online_endpoint_name, deployment_name="demo", request_file=scoring_file, ) response_json = json.loads(response) print(json.dumps(response_json, indent=2))
配置自动缩放
若要为部署配置自动缩放,请执行以下步骤:
- 登录到 Azure 门户。
- 找到刚刚在 AI 项目的资源组中部署的模型的 Azure 资源类型
Machine learning online deployment。 - 从左窗格中选择 “设置>缩放 ”。
- 选择 “自定义自动缩放 ”并配置自动缩放设置。 有关自动缩放的详细信息,请参阅 Azure 机器学习文档中的自动缩放联机终结点。
删除部署
若要在 Azure AI Foundry 门户中删除部署,请在部署详细信息页的顶部面板中选择 “删除部署 ”。
配额注意事项
若要通过实时终结点进行部署和推理,您将消耗 Azure 按区域分配给订阅的虚拟机 (VM) 核心配额。 注册 Azure AI Foundry 时,你会收到可以在所在区域中使用的多个 VM 系列的默认 VM 配额。 你可以继续创建部署,直到达到配额上限。 发生这种情况后,可以请求增加配额。
相关内容
- 详细了解可在 Azure AI Foundry 中执行哪些操作
- 在 Azure AI 常见问题解答文章中获取常见问题的解答