Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller felsökningsvägledning för problem där en Microsoft SQL Server-fråga tar för lång tid att avsluta (timmar eller dagar).
Symptoms
Den här artikeln fokuserar på frågor som verkar köras eller kompileras utan slut. Processoranvändningen fortsätter alltså att öka. Den här artikeln gäller inte för frågor som blockeras eller väntar på en resurs som aldrig släpps. I dessa fall förblir CPU-användningen konstant eller ändras bara något.
Viktigt!
Om en fråga är kvar för att fortsätta köras kan den så småningom slutföras. Den här processen kan ta bara några sekunder eller flera dagar. I vissa situationer kan frågan vara oändlig, till exempel när en WHILE-loop inte avslutas. Termen "never-ending" används här för att beskriva uppfattningen av en fråga som inte slutförs.
Orsak
Vanliga orsaker till långvariga (oändliga) frågor är:
-
Kapslade loopkopplingar (NL) i mycket stora tabeller: På grund av NL-kopplingar kan en fråga som ansluter till tabeller som har många rader köras under lång tid. Mer information finns i Kopplingar.
- Ett exempel på en NL-koppling är användningen av
TOP,FASTellerEXISTS. Även om en hash- eller sammanslagningskoppling kan vara snabbare kan optimeraren inte använda någon av operatorerna på grund av radmålet. - Ett annat exempel på en NL-koppling är användningen av en ojämlikhetskopplingspredikat i en fråga. Till exempel
SELECT .. FROM tab1 AS a JOIN tab 2 AS b ON a.id > b.id. Optimeraren kan inte heller använda sammanfognings- eller hashkopplingar här.
- Ett exempel på en NL-koppling är användningen av
- Inaktuell statistik: Frågor som väljer en plan baserat på inaktuell statistik kan vara suboptimala och ta lång tid att köra.
- Ändlösa loopar: T-SQL-frågor som använder WHILE-loopar kan vara felaktigt skrivna. Den resulterande koden lämnar aldrig loopen och körs oändligt. De här frågorna slutar verkligen aldrig. De springer tills de dödas manuellt.
- Komplexa frågor som har många kopplingar och stora tabeller: Frågor som omfattar många anslutna tabeller skulle vanligtvis ha komplexa frågeplaner som kan ta lång tid att köra. Det här scenariot är vanligt i analysfrågor som inte filtrerar bort rader och som omfattar ett stort antal tabeller.
- Index saknas: Frågor kan köras betydligt snabbare om lämpliga index används i tabeller. Med index kan du välja en delmängd av data för att ge snabbare åtkomst.
Lösning
Steg 1: Identifiera oändliga frågor
Leta efter en oändlig fråga som körs i systemet. Du måste avgöra om en fråga har lång körningstid, lång väntetid (fastnat på en flaskhals) eller en lång kompileringstid.
1.1 Kör en diagnostik
Kör följande diagnostikfråga på din SQL Server-instans där den oändliga frågan är aktiv:
DECLARE @cntr INT = 0
WHILE (@cntr < 3)
BEGIN
SELECT TOP 10 s.session_id,
r.status,
CAST(r.cpu_time / (1000 * 60.0) AS DECIMAL(10,2)) AS cpu_time_minutes,
CAST(r.total_elapsed_time / (1000 * 60.0) AS DECIMAL(10,2)) AS elapsed_minutes,
r.logical_reads,
r.wait_time,
r.wait_type,
r.wait_resource,
r.reads,
r.writes,
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count,
atrn.name as transaction_name,
atrn.transaction_id,
atrn.transaction_state
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id
CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
LEFT JOIN (sys.dm_tran_session_transactions AS stran
JOIN sys.dm_tran_active_transactions AS atrn
ON stran.transaction_id = atrn.transaction_id)
ON stran.session_id =s.session_id
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
SET @cntr = @cntr + 1
WAITFOR DELAY '00:00:05'
END
1.2 Granska utdata
Det finns flera scenarier som kan orsaka att en fråga körs under lång tid: lång körning, lång väntan och lång kompilering. Mer information om varför en fråga kan köras långsamt finns i Köra jämfört med väntar: varför är frågorna långsamma?
Lång körningstid
Felsökningsstegen i den här artikeln gäller när du får utdata som liknar följande, där CPU-tiden ökar proportionellt till den förflutna tiden utan betydande väntetider.
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | körs | 64.40 | 23.50 | 0 | 0.00 | NULL |
Frågan körs kontinuerligt om den har:
- En ökande CPU-tid
- Status för
runningellerrunnable - Minimal eller noll väntetid
- Ingen wait_type
I den här situationen läser frågan rader, sammanfogar, bearbetar resultat, beräknar eller formaterar. Dessa aktiviteter är alla CPU-bundna åtgärder.
Kommentar
Ändringar i logical_reads är inte relevanta i det här fallet eftersom vissa CPU-bundna T-SQL-begäranden, till exempel att utföra beräkningar eller en WHILE loop, kanske inte gör några logiska läsningar alls.
Om den långsamma frågan uppfyller dessa kriterier fokuserar du på att minska körningen. Att minska körningen innebär vanligtvis att minska antalet rader som frågan måste bearbeta under hela sin livslängd genom att tillämpa index, skriva om frågan eller uppdatera statistik. Mer information finns i avsnittet Lösning .
Lång väntetid
Den här artikeln gäller inte för scenarier med långa väntetider. I ett väntescenario kan du få utdata som liknar följande exempel där processoranvändningen inte ändras eller ändras något eftersom sessionen väntar på en resurs:
| session_id | status | cpu_time_minutes | elapsed_time_minutes | logical_reads | wait_time_minutes | wait_type |
|---|---|---|---|---|---|---|
| 56 | upphängd | 0.03 | 4.20 | 50 | 4.10 | LCK_M_U |
Väntetypen anger att sessionen väntar på en resurs. En lång tid och lång väntetid indikerar att sessionen väntar på det mesta av sin livslängd för den här resursen. Kort CPU-tid indikerar att lite tid faktiskt användes för att bearbeta frågan.
Information om hur du felsöker frågor som är långa på grund av väntetider finns i Felsöka långsamma frågor i SQL Server.
Lång kompileringstid
I sällsynta fall kan du observera att CPU-användningen ökar kontinuerligt över tid men inte drivs av frågekörningen. I stället kan en alltför lång kompilering (parsning och kompilering av en fråga) vara orsaken. I dessa fall kontrollerar du utdatakolumnen transaction_name efter värdet sqlsource_transform. Det här transaktionsnamnet anger en kompilering.
Steg 2: Samla in diagnostikloggar manuellt
När du har fastställt att det finns en oändlig fråga i systemet kan du samla in frågans plandata för att felsöka ytterligare. Om du vill samla in data använder du någon av följande metoder, beroende på din version av SQL Server.
- SQL Server 2008 – SQL Server 2014 (tidigare än SP2)
- SQL Server 2014 (senare än SP2) och SQL Server 2016 (tidigare än SP1)
- SQL Server 2016 (senare än SP1) och SQL Server 2017
- SQL Server 2019 och senare versioner
Följ dessa steg för att samla in diagnostikdata med hjälp av SQL Server Management Studio (SSMS):
Samla in xml-koden för den uppskattade frågekörningsplanen .
Granska frågeplanen för att ta reda på om data visar tydliga indikationer på vad som orsakar långsamheten. Exempel på typiska indikationer är:
- Tabell- eller indexgenomsökningar (titta på uppskattade rader)
- Kapslade loopar som drivs av en enorm datauppsättning för yttre tabeller
- Kapslade loopar som har en stor gren på den inre sidan av slingan
- Tabellpooler
- Funktioner i
SELECTlistan som tar lång tid att bearbeta varje rad
Om frågan körs snabbare när som helst kan du samla in "snabba" körningar (faktisk XML-körningsplan) för att jämföra resultat.
Använda SQL LogScout för att samla in oändliga frågor
Du kan använda SQL LogScout för att samla in loggar medan en oändlig fråga körs. Använd det oändliga frågescenariot med följande kommando:
.\SQL_LogScout.ps1 -Scenario "NeverEndingQuery" -ServerName "SQLInstance"
Kommentar
Den här logginsamlingsprocessen kräver att den långa frågan förbrukar minst 60 sekunders CPU-tid.
SQL LogScout samlar in minst tre frågeplaner för varje fråga med hög CPU-användning. Du hittar filnamn som liknar servername_datetime_NeverEnding_statistics_QueryPlansXml_Startup_sessionId_#.sqlplan. Du kan använda dessa filer i nästa steg när du granskar planer för att identifiera orsaken till lång frågekörning.
Steg 3: Granska de insamlade planerna
I det här avsnittet beskrivs hur du granskar insamlade data. Den använder flera XML-frågeplaner (med tillägget .sqlplan) som samlas in i Microsoft SQL Server 2016 SP1 och senare versioner.
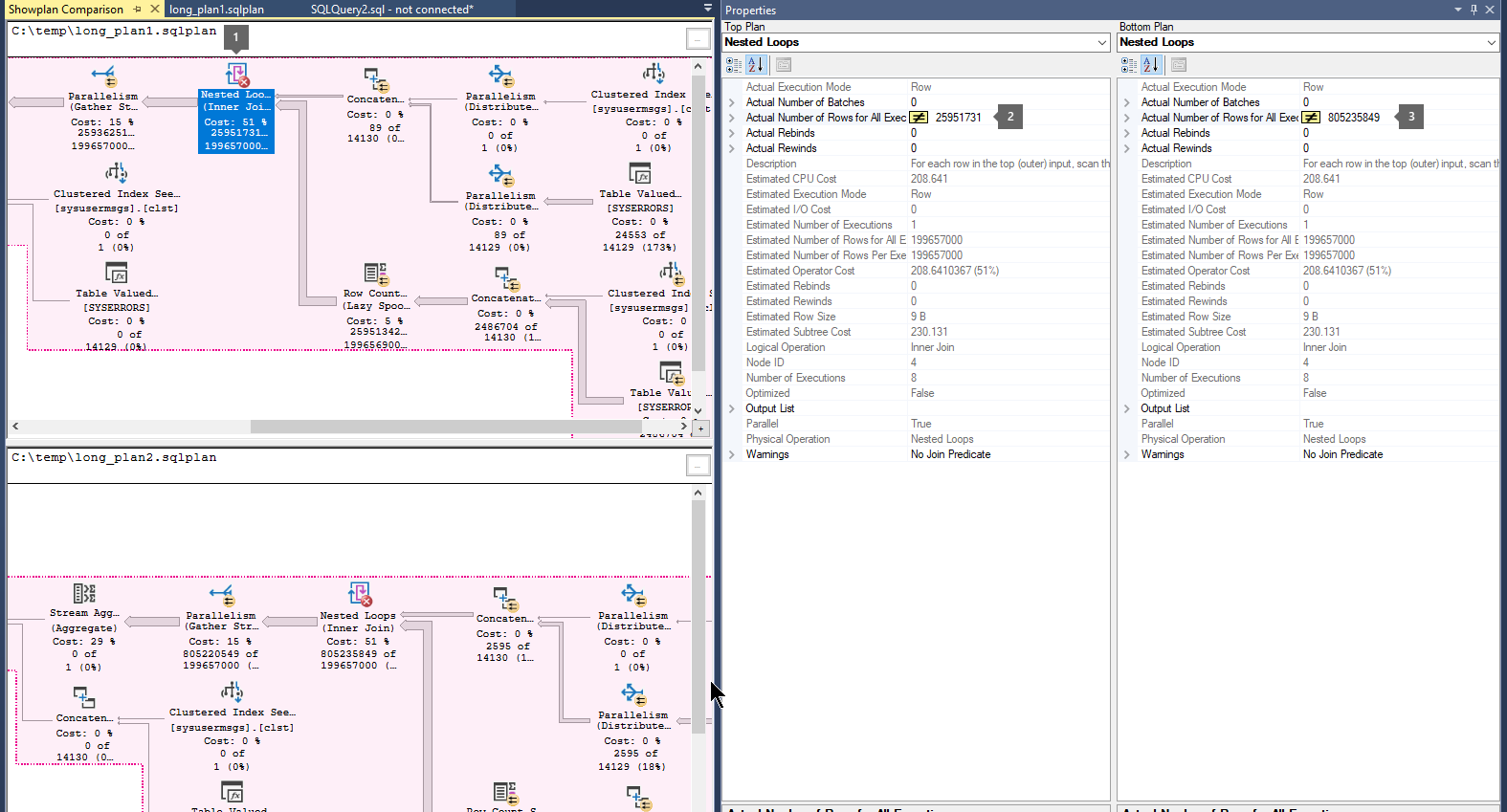
Jämför körningsplaner genom att följa dessa steg:
Öppna en tidigare sparad frågekörningsplanfil (
.sqlplan).Högerklicka i ett tomt område i körningsplanen och välj Jämför Showplan.
Välj den andra frågeplansfilen som du vill jämföra.
Leta efter tjocka pilar som anger ett stort antal rader som flödar mellan operatorer. Välj sedan operatorn före eller efter pilen och jämför antalet faktiska rader mellan de två planerna.
Jämför den andra och tredje planen för att lära dig om det största flödet av rader inträffar i samma operatorer.
Till exempel:

Steg 4: Lösning
Kontrollera att statistiken uppdateras för de tabeller som används i frågan.
Leta efter saknade indexrekommendationer i frågeplanen och tillämpa alla som du hittar.
Förenkla frågan:
- Använd mer selektiva
WHEREpredikat för att minska de data som bearbetas i förväg. - Bryt isär den.
- Välj vissa delar i temporära tabeller och anslut dem senare.
- Ta bort
TOP,EXISTSochFAST(T-SQL) i de frågor som körs under lång tid på grund av ett radmål för optimeraren.- Du kan också använda
DISABLE_OPTIMIZER_ROWGOAL. Mer information finns i Row Goals Gone Rogue.
- Du kan också använda
- Undvik att använda Vanliga tabelluttryck (CTE) i sådana fall eftersom de kombinerar instruktioner till en enda stor fråga.
- Använd mer selektiva
Prova att använda frågetips för att skapa en bättre plan:
-
HASH JOINellerMERGE JOINtips -
FORCE ORDERantydan -
FORCESEEKantydan RECOMPILE- USE
PLAN N'<xml_plan>'(om du har en snabb frågeplan som du kan framtvinga)
-
Använd Query Store (QDS) för att framtvinga en bra känd plan om en sådan plan finns och om din SQL Server-version stöder Query Store.