Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller lösningar på problem som rör återställningsköer.
Vad är återställningsköer?
Ändringar som görs på den primära repliken i databasen för en tillgänglighetsgrupp skickas till alla sekundära repliker som är definierade i samma tillgänglighetsgrupp. När ändringarna kommer till de sekundära replikerna skrivs de först till transaktionsloggfilen för tillgänglighetsgruppens databas. Microsoft SQL Server använder sedan återställnings - eller gör om-åtgärden för att uppdatera databasfilerna.
Om ändringarna i en tillgänglighetsgrupp anländer och hårdnar i databasens transaktionsloggfil snabbare än de kan återställas, skapas en återställningskö . Den här kön består av härdade loggtransaktioner som inte har återställts till databasen.
Symtom och effekt av återställning (gör om) kö
Att köra frågor mot primära och sekundära repliker returnerar olika resultat
Skrivskyddade arbetsbelastningar som kör frågor mot sekundära repliker kan köra frågor mot inaktuella data. Om återställningsköer inträffar kanske ändringar av data i den primära replikdatabasen inte återspeglas i den sekundära databasen när du kör frågor mot samma data.
Även om ändringarna kommer till den sekundära databasen och skrivs till databasloggfilen, kommer ändringarna inte att efterfrågas förrän de återställs och återställs till databasfilerna. Återställningsåtgärden gör dessa ändringar läsbara.
Mer information finns i avsnittet Datasvarstid på sekundär replik i "Skillnader mellan tillgänglighetslägen för en AlwaysOn-tillgänglighetsgrupp".
Redundanstiden är längre eller rto överskrids
Mål för återställningstid (RTO) är den maximala databasavbrott som en organisation kan hantera. RTO beskriver också hur snabbt organisationen kan återfå åtkomsten till databasen efter ett avbrott. Om det finns omfattande återställningsköer på en sekundär replik när en redundansväxling inträffar kan återställningen ta längre tid. Efter återställningen övergår databasen till den primära rollen och representerar tillståndet för databasen som fanns före redundansväxlingen. En längre återställningstid kan fördröja hur snabbt produktionen återupptas efter en redundansväxling.
Olika diagnostikfunktioner rapporterar återställningsköer för tillgänglighetsgrupp
När det gäller återställningsköer kan AlwaysOn-instrumentpanelen i SQL Server Management Studio (SSMS) rapportera en tillgänglighetsgrupp som inte är felfri.
Så här söker du efter köer för återställning (gör om)
Återställningskö är ett mått per databas som kan kontrolleras med instrumentpanelen AlwaysOn på den primära repliken eller med hjälp av sys.dm_hadr_database_replica_states Dynamic Management View (DMV) på den primära eller sekundära repliken. Prestandaövervakarens räknare kontrollerar återställningsköer och återställningshastighet. Dessa räknare måste kontrolleras mot den sekundära repliken.
I nästa avsnitt finns metoder för att aktivt övervaka återställningskön för tillgänglighetsgruppens databas.
Fråga sys.dm_hadr_database_replica_states
sys.dm_hadr_database_replica_states DMV rapporterar en rad för varje tillgänglighetsgruppdatabas. En kolumn i rapporten är redo_queue_size. Det här värdet är återställningsköstorleken mätt i kilobyte. Du kan konfigurera en fråga som liknar följande fråga för att övervaka eventuella trender i återställningsköstorleken var 30:e sekund. Frågan körs på den primära repliken. Den använder predikatet is_local=0 för att rapportera data för den sekundära repliken, där redo_queue_size och redo_rate är relevanta.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.redo_queue_size, drs.redo_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Så här ser utdata ut.

Granska återställningskö i AlwaysOn-instrumentpanelen
Följ dessa steg för att granska återställningskön:
Öppna Instrumentpanelen Alltid på i SSMS genom att högerklicka på en tillgänglighetsgrupp i SSMS Object Explorer.
Välj Visa instrumentpanel.
Tillgänglighetsgruppens databaser visas sist och vissa data rapporteras om databaserna. Även om Redo Queue Size (KB) och Redo Rate (KB/sec) inte visas som standard kan du lägga till dem i den här vyn, som du ser i skärmbilden i nästa steg.
Om du vill lägga till dessa räknare högerklickar du på rubriken ovanför databasrapporterna och väljer i listan över tillgängliga kolumner.
Om du vill lägga till Redo Queue Size (KB) och Redo Rate (KB/sek) högerklickar du på rubriken som visas som markerat i rött på följande skärmbild.
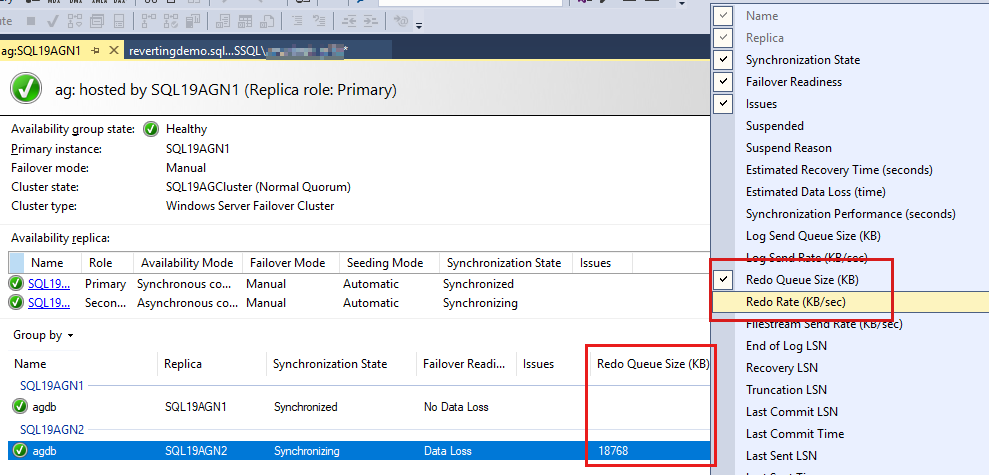
Som standard uppdaterar AlwaysOn-instrumentpanelen automatiskt Redo Queue Size (KB) och Redo Rate (KB/sek) var 60:e sekund.



Granska återställningskön i Prestandaövervakaren
Återställningsköstorleken är unik för varje sekundär replik och databas. Följ därför dessa steg för att granska återställningskön för en tillgänglighetsgruppdatabas:
Öppna Prestandaövervakaren på den sekundära repliken.
Välj knappen Lägg till (räknare).
Under Tillgängliga räknare väljer du SQLServer:Database Replica och sedan Återställningskö och Gör om byte/sek-räknare .
I listrutan Instans väljer du den tillgänglighetsgruppdatabas som du vill övervaka för återställningsköer.
Välj Lägg till>OK.
Så här kan ökad återställningskö se ut.
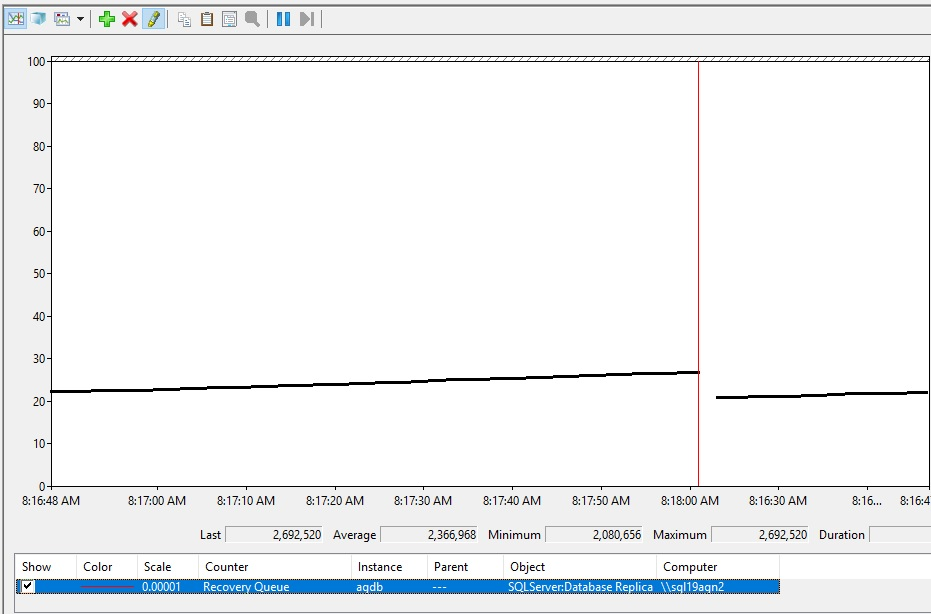

Tolka värden för återställningsköer
I det här avsnittet beskrivs hur du kan tolka de värden som är relaterade till återställningsköer som du fastställde i föregående avsnitt.
När är återställningskön ett problem? Hur mycket återställningskö ska du tolerera?
Du kan anta att om återställningskön rapporterar värdet 0 innebär det att ingen återställningskö inträffar vid tidpunkten för rapporten. Men när produktionsmiljön är upptagen bör du förvänta dig att observera att återställningskön ofta rapporterar ett annat värde än noll även i en felfri AlwaysOn-miljö. Under typisk produktion bör du förvänta dig att observera att det här värdet varierar mellan 0 och ett värde som inte är noll.
Om du ser ökad återställningskö över tid är ytterligare undersökning berättigad. Den här extra aktiviteten anger att något har ändrats. Om du ser en plötslig ökning i återställningskön är följande mått användbara för felsökning:
- Log Redo Rate (KB/s) (AlwaysOn-instrumentpanel)
- Redo_rate i DMV-sys.dm_hadr_database_replica_states
Hämta baslinjepriser för omdubblingsfrekvens
Under felfria AlwaysOn-prestanda övervakar du omfrekvensen för dina upptagna tillgänglighetsgruppdatabaser. Hur ser de ut under vanligtvis upptagna kontorstider? Vilka är dessa priser under underhållsperioder, när stora transaktioner (återskapade index, ETL-processer) ger högre transaktionsdataflöde i systemet? Du kan jämföra dessa värden när du observerar tillväxt i återställningsköer för att avgöra vad som har ändrats. Arbetsbelastningen kan vara större än vanligt. Om omdubblingsfrekvensen är lägre kan ytterligare undersökning krävas för att avgöra varför.
Arbetsbelastningsvolymer spelar roll
När du har stora arbetsbelastningar (till exempel en UPDATE-instruktion mot en miljon rader, ett index som återskapas på en tabell på 1 terabyte eller till och med en ETL-batch som infogar miljontals rader), bör du förvänta dig att se en viss tillväxt i återställningsköer, antingen omedelbart eller över tid. Detta förväntas när ett stort antal ändringar plötsligt görs i tillgänglighetsgruppdatabasen.
Diagnostisera köer för återställning (gör om)
När du har identifierat återställningsköer för en specifik sekundär repliktillgänglighetsgruppdatabas ansluter du till den sekundära repliken och frågar sys.dm_exec_requests sedan för att fastställa wait_type och wait_time för återställningstrådar. Här är en fråga som kan köras i en loop. Du letar efter en hög frekvens av en eller flera väntetyper och till och med väntetider för dessa väntetyper. Här är en exempelfråga som körs varje sekund och rapporterar väntetyper och väntetider för tillgänglighetsgruppen agdb:
WHILE (1=1)
BEGIN
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')
waitfor delay '00:00:05.000'
END
Viktigt!
För meningsfulla utdata av väntetyp bör återställningsköer observeras öka när du använder någon av de metoder som beskrivs tidigare för att övervaka det här villkoret.
I det här exemplet rapporteras vissa I/O-relaterade väntetyper (PAGEIOLATCH_UP, PAGEIOATCH_EX). Övervaka för att kontrollera om dessa väntetyper fortsätter att ha de största wait_times värdena, enligt rapporten i nästa kolumn.

SQL Server gör om väntetyper
När en väntetyp identifieras läser du följande artikel SQL Server 2016/2017: Tillgänglighetsgruppens sekundära replik gör om modell och prestanda – Microsoft Tech Community som en korsreferens för vanliga väntetyper som orsakar återställningsköer och för att få hjälp med att lösa problemet.
Blockerade gör om trådar på sekundära rapporteringsservrar
Om din lösning dirigerar rapportering (fråga) mot tillgänglighetsgruppdatabaser på den sekundära repliken, låser sig dessa skrivskyddade frågor schemastabilitet (Sch-S). Dessa Sch-S-lås kan blockera ombytestrådar från att hämta sch-M-lås (även kallade "schemaändringslås" eller LCK_M_SCH_M) för att göra ändringar i datadefinitionsspråk (DDL), till exempel ALTER TABLE eller ALTER INDEX. En blockerad gör om-tråd kan inte tillämpa loggposter förrän den har avblockerats. Detta kan orsaka återställningsköer.
Om du vill söka efter historiska bevis för en blockerad omdaning öppnar du AlwaysOn_health Xevent-spårningsfiler på den sekundära repliken med hjälp av SSMS. Leta lock_redo_blocked efter händelser.

Använd Prestandaövervakaren för att aktivt övervaka blockerad omgörningspåverkan för återställningskö. Lägg till SQL Server::D atabase Replica::Redo blocked/sec och SQL Server::D atabase Replica::Recovery Queue counters. Följande skärmbild visar ett ALTER TABLE ALTER COLUMN kommando som körs mot den primära repliken medan en tidskrävande fråga körs mot samma tabell på den sekundära repliken. Räknaren ALTER TABLE ALTER COLUMN Gör om blockerad/sek anger att kommandot körs. Medan den långvariga frågan körs i samma tabell på den sekundära repliken, kommer eventuella efterföljande ändringar i den primära att orsaka en ökning i återställningskön.

Övervaka väntetypen schemaändringslås som ska göras om-tråden försöker hämta. Det gör du genom att använda den fråga som beskrevs tidigare för att kontrollera de väntetyper som rapporteras för omgjorda åtgärder mot sys.dm_exec_requests. Du kan se den ökande väntetiden LCK_M_SCH_M för den pågående omlagringen.

Gör om med en tråd
SQL Server introducerade parallell återställning för sekundära replikdatabaser i Microsoft SQL Server 2016. Om du har återställningsköer när du kör SQL Microsoft Server 2012 eller Microsoft SQL Server 2014 kan du uppgradera till en senare version av programmet för att förbättra prestandan för att göra om i produktionsmiljön.
En enkeltrådad omdaning kan ske i ännu senare, mer avancerade SQL Server-versioner där parallell återställningsarkitektur används. I dessa versioner kan en SQL Server-instans använda upp till 100 trådar för en parallell omgörning. Beroende på antalet processorer och tillgänglighetsgruppdatabaser allokeras parallella ombearbetningstrådar upp till högst 100 trådar totalt. Om gränsen på 100 trådar har uppnåtts tilldelas vissa databaser i tillgänglighetsgruppen en enda om-tråd.
För att avgöra om tillgänglighetsgruppdatabasen använder parallell återställning ansluter du till den sekundära repliken och använder följande fråga för att fastställa antalet rader (trådar) som tillämpar återställning för tillgänglighetsgruppdatabasen. I följande exempel kan återställningsarbetsbelastningen dra nytta av parallell återställning om "agdb"-databasen är en enda tråd och dess kommando är DB STARTUP.
SELECT db_name(database_id) AS dbname, command, session_id, database_id, wait_type, wait_time,
os.runnable_tasks_count, os.pending_disk_io_count FROM sys.dm_exec_requests der JOIN sys.dm_os_schedulers os
ON der.scheduler_id=os.scheduler_id
WHERE command IN ('PARALLEL REDO HELP TASK', 'PARALLEL REDO TASK', 'DB STARTUP')
AND database_id= db_id('agdb')

Om du verifierar att databasen använder en enkeltrådad omdaning granskar du algoritmen som beskrevs tidigare för att avgöra om SQL Server överskrider antalet 100 arbetstrådar som är dedikerade för parallell återställning. Ett sådant villkor kan vara anledningen till att "agdb"-databasen endast använder en enda tråd för återställning.
SQL Server 2022 använder nu en ny parallell återställningsalgoritm så att arbetstrådar tilldelas för parallell återställning baserat på arbetsbelastningen. Detta eliminerar risken för att en upptagen databas förblir i en enkeltrådad återställning. Mer information finns i avsnittet Trådanvändning efter tillgänglighetsgrupper i "Krav, begränsningar och rekommendationer för AlwaysOn-tillgänglighetsgrupper".