Lär känna Apache Spark
Apache Spark är ett distribuerat databehandlingsramverk som möjliggör storskalig dataanalys genom att samordna arbetet mellan flera bearbetningsnoder i ett kluster.
Så här fungerar Spark
Apache Spark-program körs som oberoende uppsättningar processer i ett kluster, koordinerade av SparkContext-objektet i huvudprogrammet (kallas drivrutinsprogrammet). SparkContext ansluter till klusterhanteraren, som allokerar resurser mellan program med hjälp av en implementering av Apache Hadoop YARN. När Spark har anslutits förvärvar det exekverare på noder inom klustret för att köra din programkod.
SparkContext kör huvudfunktionen och parallella åtgärder på klusternoderna och samlar sedan in resultatet av åtgärderna. Noderna läser och skriver data från och till filsystemet och cachelagrar transformerade data i minnet som Resilient Distributed Datasets (RDD).
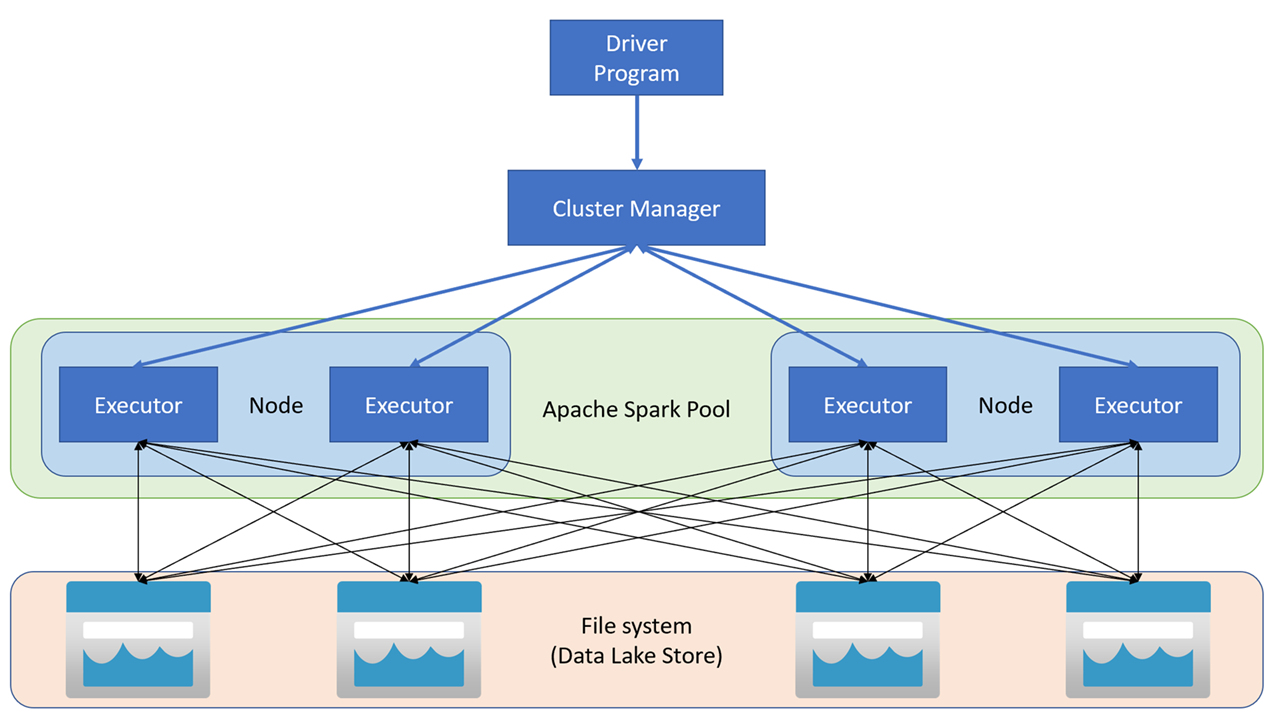
SparkContext ansvarar för att konvertera ett program till en riktad acyklisk graf (DAG). Diagrammet består av enskilda uppgifter som körs i en körprocess på noderna. Varje applikation får en egen körningsprocess som förblir aktiv under applikationens livslängd och kör uppgifter i flera trådar.
Spark-pooler i Azure Synapse Analytics
I Azure Synapse Analytics implementeras ett kluster som en Spark-pool, vilket ger en körning för Spark-åtgärder. Du kan skapa en eller flera Spark-pooler på en Azure Synapse Analytics-arbetsyta med hjälp av Azure Portal eller i Azure Synapse Studio. När du definierar en Spark-pool kan du ange konfigurationsalternativ för poolen, inklusive:
- Ett namn för spark-poolen.
- Storleken på den virtuella datorn (VM) som används för noderna i poolen, inklusive alternativet att använda maskinvaruaccelererade GPU-aktiverade noder.
- Antalet noder i poolen och om poolstorleken är fast eller om enskilda noder kan aktiveras dynamiskt för automatisk skalning av klustret. I så fall kan du ange det lägsta och högsta antalet aktiva noder.
- Den version av Spark Runtime som ska användas i poolen, som avgör vilka versioner av enskilda komponenter som Python, Java och andra som installeras.
Dricks
Mer information om konfigurationsalternativ för Spark-pooler finns i Konfigurationer av Apache Spark-pooler i Azure Synapse Analytics i Dokumentationen om Azure Synapse Analytics.
Spark-pooler i en Azure Synapse Analytics-arbetsyta är serverlösa – de startar på begäran och slutar när de är inaktiva.