Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() SQL Server
SQL Server
Den här artikeln beskriver hur du utför en tvingad redundansväxling (med möjlig dataförlust) i en AlwaysOn-tillgänglighetsgrupp med hjälp av SQL Server Management Studio, Transact-SQL eller PowerShell i SQL Server. En tvingad redundansväxling är en form av manuell redundans som är avsedd enbart för haveriberedskap, när en planerad manuell redundansväxling inte är möjlig. Om du tvingar övergång till en osynkroniserad sekundär replik är viss dataförlust möjlig. Därför rekommenderar vi starkt att du endast framtvingar redundansväxling om du måste återställa tjänsten till tillgänglighetsgruppen omedelbart och du är villig att riskera att förlora data.
Efter en tvingad överflyttning blir målsystemet som tillgänglighetsgruppen överflyttades till den nya primärreplikan. De sekundära databaserna i de återstående sekundära replikerna pausas och måste återupptas manuellt. När den tidigare primära repliken blir tillgänglig övergår den till den sekundära rollen, vilket gör att de tidigare primära databaserna blir sekundära databaser och övergår till SUSPENDED tillståndet. Innan du återupptar en viss sekundär databas kanske du kan återställa förlorade data från den. Observera dock att trunkering av transaktionsloggar fördröjs på en viss primär databas medan någon av dess sekundära databaser är avstängd.
Viktig
Datasynkronisering med den primära databasen sker inte förrän den sekundära databasen återupptas. För att återuppta en sekundär databas, se Uppföljning: Viktiga uppgifter efter en tvingad omkoppling längre fram i artikeln.
Det är nödvändigt att utföra en tvingad redundansväxling i följande nödsituationer:
När du har tvingat kvorum på WSFC-klustret (framtvingad kvorum) måste du framtvinga en failover för varje tillgänglighetsgrupp (med möjlig dataförlust). Att tvinga fram redundans krävs eftersom det verkliga tillståndet för WSFC-klustervärdena kan ha gått förlorat. Du kan dock undvika dataförlust om du kan tvinga fram en failover på den serverinstans som var värd för den primära repliken innan du aktiverade kvorum, eller till en sekundär replik som var synkroniserad innan du aktiverade kvorum. Mer information finns i Potentiella sätt att undvika dataförlust när kvorum har tvingats, senare i den här artikeln.
Viktig
Om kvorumet återfås på naturligt sätt istället för att forceras, genomgår tillgänglighetsreplikerna normal återhämtning. Om den primära repliken fortfarande är otillgänglig även efter att quorum har återställts, kan du utföra en manuell planerad övergång till en synkroniserad sekundär replik.
Information om hur du tvingar kvorum finns i WSFC-haveriberedskap via forcerad kvorum (SQL Server). Information om varför tvingad redundans krävs efter att kvorum har tvingats fram finns i redundanslägen och redundanslägen (AlwaysOn-tillgänglighetsgrupper).
Om den primära repliken blir otillgänglig när WSFC-klustret har ett felfritt kvorum kan du framtvinga failover (med möjlig dataförlust) till vilken replik som helst vars roll är i
SECONDARY-tillståndet ellerRESOLVING-tillståndet. Om möjligt framtvingar du redundans till en synkron-commit sekundär replik som synkroniserades när den primära repliken förlorades.Tips
När WSFC-klustret har ett hälsosamt kvorum, om du utfärdar ett *force failover*-kommando på en synkroniserad sekundär replik, utför repliken faktiskt en planerad manuell failover.
Mer information om förutsättningar och rekommendationer för att tvinga redundans och ett exempelscenario som använder en tvingad redundansväxling för att återställa från ett oåterkalleligt fel finns i Exempelscenario: Använd en tvingad redundansväxling för att återställa från ett oåterkalleligt fel senare i den här artikeln.
Begränsningar
Den enda gången du inte kan utföra en tvingad redundansväxling är när WSFC-klustret (Windows Server Failover Clustering) saknar kvorum.
Dataförlust är möjlig i samband med en tvingad överflyttning av en tillgänglighetsgrupp. Om den primära repliken körs när du initierar en tvingad redundansväxling kan klienterna dessutom fortfarande vara anslutna till tidigare primära databaser. Därför rekommenderar vi starkt att du endast framtvingar redundansväxling om den primära repliken inte längre körs och om du är villig att riskera att förlora data för att återställa åtkomsten till databaser i tillgänglighetsgruppen.
När en sekundär databas är i
REVERTING- ellerINITIALIZING-tillstånd, skulle en framtvingad övertagande leda till att databasen inte kan starta som en primär databas. Om databasen var i tillståndetINITIALIZINGmåste du tillämpa de saknade loggposterna från en databassäkerhetskopia eller helt återställa databasen från grunden. Om databasen var i tillståndetREVERTINGmåste du helt återställa databasen från säkerhetskopior.Ett redundanskommando returneras så snart redundansmålet har godkänt kommandot. Databasåterställning sker dock asynkront när tillgänglighetsgruppen är klar med redundansväxlingen.
Konsekvens mellan databaser i tillgänglighetsgruppen kanske inte underhålls vid växling.
Not
Stöd för transaktioner mellan databaser och distribuerade transaktioner varierar beroende på versionerna av SQL Server och operativsystemet. Mer information finns i Transaktioner – tillgänglighetsgrupper och databasspegling.
Förutsättningar
WSFC-klustret har kvorum. Om klustret saknar kvorum, se havariåterställning för WSFC genom forcerad kvorum (SQL Server).
Du måste kunna ansluta till en serverinstans som är värd för en replik vars roll är i
SECONDARYtillståndet ellerRESOLVING.
Rekommendationer
Tvinga inte övergång medan den primära kopian fortfarande körs.
Om möjligt tvingar du endast redundans till ett redundansmål vars sekundära databaser antingen är i
NOT SYNCHRONIZEDtillståndet ,SYNCHRONIZEDellerSYNCHRONIZING. För information om konsekvenserna av att tvinga redundans när en sekundär databas är i tillståndetINITIALIZINGellerREVERTING, se Begränsningar tidigare i den här artikeln.Normalt bör svarstiden för en viss sekundär databas, i förhållande till den primära databasen, vara liknande på olika asynkrona sekundära repliker. Men när du tvingar fram en failover kan dataförlust vara ett stort problem. Överväg därför att ta tid att fastställa den relativa svarstiden för kopiorna av databaserna på olika sekundära repliker. Om du vill ta reda på vilken kopia av en viss sekundär databas som har minst svarstid jämför du deras LSN i slutet av loggen. En högre LSN i slutet av loggen anger mindre svarstid.
Tips
Om du vill jämföra LSN:er i slutet av loggen ansluter du till varje sekundär onlinereplik och frågar
end_of_log_lsnefter värdet för varje lokal sekundär databas. Jämför sedan LSN:erna för slutet av loggen för de olika kopiorna av varje databas. Olika databaser kan ha sina högsta LSN på olika sekundära repliker. I det här fallet beror det lämpligaste redundansmålet på den relativa betydelse som du lägger på data i de olika databaserna. Vilket av dessa databaser vill du minimera möjliga dataförluster för?Om klienter kan ansluta till den ursprungliga primära kan en tvingad omkoppling medföra en viss risk för splitbrain-beteende. Innan du tvingar fram redundans rekommenderar vi starkt att du hindrar klienter från att komma åt den ursprungliga primära repliken. När övertagningen har tvingats kan de ursprungliga och aktuella primära databaserna uppdateras oberoende av de andra.
Möjliga sätt att undvika dataförlust efter att quorum har tvingats
Under vissa felförhållanden när kvorumet har gått förlorat kan du förhindra dataförlust på följande sätt:
Om den ursprungliga primära repliken är online
Om kvorum går förlorat och tvingar WSFC-kvorumet att återställa klusternoden som är värd för den primära repliken för en tillgänglighetsgrupp, kan du förhindra dataförlust för den här tillgänglighetsgruppen. Anslut till den primära repliken och utför en tvingad failover (FAILOVER_ALLOW_DATA_LOSS). Detta gör att den primära repliken är online igen. Eftersom du utför den tvingade övergången till den ursprungliga primära repliken sker ingen dataförlust.
Om en synkroniserad sekundär replik med synkron incheckning kommer online
Om kvorum går förlorat och därmed tvingar WSFC-kvorumet att återställa en klusternod som är värd för den synkroniserade sekundära repliken i tillgänglighetsgruppen, bör du kunna förhindra dataförlust för denna tillgänglighetsgrupp. Om den återställda noden var igång när kvorumet gick förlorat kan du avgöra om det finns risk för dataförlust i en viss databas genom att fråga efter kolumnen i
is_failover_readysys.dm_hadr_database_replica_cluster_states dynamisk hanteringsvy. För en serverinstans med namnetsql108w2k8r22utfärdar du till exempel följande fråga:SELECT * FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id = ( SELECT replica_id FROM sys.availability_replicas WHERE replica_server_name = 'sql108w2k8r22' );Försiktighet
Om den återställda noden inte var uppe när kvorumet förlorades kan
is_failover_readykanske inte återspegla klustrets verkliga tillstånd när den primära replikan gick offline. Därföris_failover_readyär värdet bara bra om värdnoden vid tidpunkten för felet. För mer information, se "Varför tvingad omkoppling krävs efter att kvorum har tvingats fram" i omkoppling och omkopplingslägen (Always On tillgänglighetsgrupper).Om
is_failover_ready = 1är uppfyllt markeras databasen som synkroniserad i klustret och är redo för en redundansväxling. Om du på varje databas på en given sekundär replik kan utföra en tvingad failover (FORCE_FAILOVER_ALLOW_DATA_LOSS) utan dataförlust på denna sekundära replik. Den synkroniserade sekundära repliken är online i den primära rollen, dvs. som den nya primära repliken, med alla data intakta.Om
is_failover_ready = 0är databasen markerad som icke-synkroniserad i klustret och inte redo för en planerad manuell övergång. Om du tvingar en failover till den sekundära värdrepliken, förloras data i denna databas.Not
När du tvingar överflyttning till en sekundär instans beror mängden dataförlust på hur långt överflyttningsmålet släpar efter den primära instansen. Tyvärr, när WSFC-klustret saknar kvorum eller när kvorum har tvingats, kan du inte bedöma mängden potentiell dataförlust. Observera dock att när WSFC-klustret återfår ett felfritt kvorum kan du börja spåra potentiell dataförlust. Mer information finns i "Spåra potentiell dataförlust" i redundans och redundanslägen (Always On-tilgänglighetsgrupper).
Behörigheter
Kräver ALTER AVAILABILITY GROUP behörighet för tillgänglighetsgruppen, CONTROL AVAILABILITY GROUP behörigheten, ALTER ANY AVAILABILITY GROUP behörigheten eller CONTROL SERVER behörigheten.
Använda SQL Server Management Studio
I Object Explorer ansluter du till en serverinstans som är värd för en replik vars roll är i
SECONDARY- ellerRESOLVING-läget i tillgänglighetsgruppen som måste växlas över, och expanderar serverträdet.Expandera noden Always On High Availability och noden Tillgänglighetsgrupper.
Högerklicka på tillgänglighetsgruppen som ska överväxlas och välj kommandot Växla över.
Det här startar guiden för Failover-tillgänglighetsgruppen. Mer information finns i Använda guiden För redundansväxlingstillgänglighetsgrupp (SQL Server Management Studio).
När du har tvingat en tillgänglighetsgrupp att växla över, slutför du de nödvändiga uppföljningsstegen. Mer information finns i Uppföljning: Viktiga uppgifter efter en tvingad felövergång, senare i den här artikeln.
Använd Transact-SQL
Anslut till en serverinstans som är värd för en replik vars roll är i tillståndet
SECONDARYellerRESOLVINGi tillgänglighetsgruppen som behöver genomgå en failover.Använd ALTER AVAILABILITY GROUP-instruktionen , enligt följande, där group_name är namnet på tillgänglighetsgruppen:
ALTER AVAILABILITY GROUP <group_name> FORCE_FAILOVER_ALLOW_DATA_LOSS.I följande exempel tvingas tillgänglighetsgruppen
AccountsAGatt växla över till den lokala sekundära repliken.ALTER AVAILABILITY GROUP AccountsAG FORCE_FAILOVER_ALLOW_DATA_LOSS;När du har tvingat en tillgänglighetsgrupp att växla över, slutför du de nödvändiga uppföljningsstegen. Mer information finns i Viktiga uppgifter efter en tvingad systemövergång, senare i den här artikeln.
Använda PowerShell
Byt katalog (
cd) till en serverinstans som värdar en replik med en roll som är i tillståndetSECONDARYellerRESOLVINGi tillgänglighetsgruppen som behöver växlas över.Använd cmdleten
Switch-SqlAvailabilityGroupmed parameternAllowDataLossi något av följande formulär:-AllowDataLossSom standardinställning orsakar parametern
-AllowDataLossattSwitch-SqlAvailabilityGroupuppmanar dig att komma ihåg att tvungen redundansväxling kan leda till förlust av obekräftade transaktioner samt att begära bekräftelse. Om du vill fortsätta anger duY; om du vill avbryta åtgärden anger duN.I följande exempel utförs en tvingad failover (med möjlig dataförlust) till den sekundära repliken av tillgänglighetsgruppen
MyAgpå serverinstansen med namnetSecondaryServer\InstanceName. Du uppmanas att bekräfta den här åtgärden.Switch-SqlAvailabilityGroup ` -Path SQLSERVER:\Sql\SecondaryServer\InstanceName\AvailabilityGroups\MyAg ` -AllowDataLoss-AllowDataLoss-ForceOm du vill initiera en tvingad failover utan bekräftelse anger du både parametrarna
-AllowDataLossoch-Force. Detta är användbart om du vill inkludera kommandot i ett skript och köra det utan användarinteraktion. Använd dock alternativet-Forcemed försiktighet eftersom en tvingad redundansväxling kan leda till förlust av data från databaser som deltar i tillgänglighetsgruppen.I följande exempel utförs en tvingad redundansväxling (med möjlig dataförlust) av tillgänglighetsgruppen
MyAgtill serverinstansen med namnetSecondaryServer\InstanceName. Alternativet-Forceundertrycker bekräftelsen av den här åtgärden.Switch-SqlAvailabilityGroup ` -Path SQLSERVER:\Sql\SecondaryServer\InstanceName\AvailabilityGroups\MyAg ` -AllowDataLoss -Force
Not
Om du vill visa syntaxen för en cmdlet använder du cmdleten
Get-Helpi SQL Server PowerShell-miljön. Mer information finns i Hämta hjälp för SQL Server PowerShell.När du har tvingat en tillgänglighetsgrupp att växla över, slutför du de nödvändiga uppföljningsstegen. För mer information, se Uppföljning: Viktiga uppgifter efter en tvingad övertagning, senare i den här artikeln.
Konfigurera och använda SQL Server PowerShell-providern
Uppföljning: Viktiga uppgifter efter en tvungen övergång till reservsystem
Efter ett tvingat felövergång blir den sekundära repliken som du växlade över till den nya primära repliken. För att göra tillgänglighetsrepliken tillgänglig för klienter kan du dock behöva konfigurera om WSFC-kvorumet eller justera tillgänglighetsgruppens konfiguration av tillgänglighetsläget på följande sätt:
Om du utförde redundansväxling utanför den automatiska redundansuppsättningen: Justera kvorumrösterna för WSFC-noderna så att de återspeglar den nya konfigurationen av din tillgänglighetsgrupp. Om WSFC-noden som värdar den sekundära målrepliken inte har en WSFC-kvorumröstning kan du behöva tvinga fram ett WSFC-kvorum.
En automatisk redundansuppsättning finns bara om två tillgänglighetsrepliker (inklusive den tidigare primära repliken) har konfigurerats för synkront incheckningsläge med automatisk redundans.
Justera kvorumröster
Om du växlat över utanför failover-uppsättningen för synkron commit: Vi rekommenderar att du överväger att justera tillgänglighetsläget och failover-läget på den nya primära repliken och på återstående sekundära repliker för att återspegla önskad synkron commit och automatisk failoverkonfiguration.
Not
Det finns bara en redundansuppsättning för synkron incheckning om den aktuella primära repliken har konfigurerats för synkront incheckningsläge.
Ändra tillgänglighetsläge och redundansläge
Efter en tvingad överflyttning pausas alla sekundära databaser. Detta omfattar de tidigare primära databaserna, efter att den tidigare primära repliken kommer online igen och upptäcker att den nu är en sekundär replik. Du måste återuppta varje pausad databas manuellt individuellt på varje sekundär replik.
När en sekundär databas återupptas initieras datasynkronisering med motsvarande primära databas. Den sekundära databasen återställer alla loggposter som aldrig har bekräftats i den nya primära databasen. Om du är orolig för eventuell dataförlust på de primära databaserna efter att överföringen till en sekundär databas har misslyckats bör du därför försöka skapa en ögonblicksbild av databasen på de databaser som är i pausat läge i en av de sekundära databaserna med synkron commit.
Viktig
Trunkering av transaktionsloggar fördröjs på en primär databas medan någon av dess sekundära databaser pausas. Statusen för synkronisering av en sekundär replik med synkront åtagande kan inte heller övergå till
HEALTHYså länge någon lokal databas förblir inaktiv.Skapa en databasögonblicksbild
Så här återupptar du en tillgänglighetsdatabas
Försiktighet
Efter att ha återupptagit alla sekundära databaser, innan du försöker att återigen genomföra en failover av gruppen, vänta tills varje sekundär databas på nästa failover-mål går in i
SYNCHRONIZING-tillståndet. Om någon databas ännu inte ärSYNCHRONIZINGförhindras den från att komma online som en primär databas, och för att återupprätta datasynkronisering kan det krävas återställning av transaktionsloggar, återställning av en fullständig databassäkerhetskopia eller växling tillbaka till den tidigare primära repliken.Om en tillgänglighetsreplik som misslyckades inte återgår till tillgänglighetsrepliken eller kan komma tillbaka för sent för att fördröja trunkeringen av transaktionsloggen på den nya primära databasen kan du överväga att ta bort den misslyckade repliken från tillgänglighetsgruppen för att undvika att diskutrymmet för loggfilerna tar slut.
Ta bort en sekundär replik
Om du följer en tvingad redundansväxling med en eller flera ytterligare framtvingade redundansväxlingar utför du en loggsäkerhetskopia efter varje ytterligare tvingad redundansväxling i serien. Information om orsaken till detta finns i "Risker med att tvinga redundans" i avsnittet "Tvingad manuell redundans (med möjlig dataförlust)" i redundans- och redundanslägen (AlwaysOn-tillgänglighetsgrupper).
Så här utför du en loggsäkerhetskopia
Exempelscenario: Använd en tvingad redundansväxling för att återställa från ett oåterkalleligt fel
Om den primära repliken misslyckas och ingen synkroniserad sekundär replik är tillgänglig kan det vara ett lämpligt svar att tvinga över tillgänglighetsgruppen till en failover. Lämpligheten för att tvinga fram en redundansväxling beror på: (1) om du förväntar dig att den primära repliken ska vara offline längre än vad ditt serviceavtal (SLA) tolererar, och (2) om du är villig att riskera potentiell dataförlust för att göra primära databaser tillgängliga snabbt. Om du bestämmer dig för att en tillgänglighetsgrupp kräver en tvingad redundansväxling är den faktiska framtvingade redundansväxlingen bara ett steg i en process i flera steg.
För att illustrera de steg som krävs för att använda en tvingad failover för att återhämta sig från ett katastrofalt fel presenterar den här artikeln ett möjligt återställningsscenario. Exempelscenariot tar hänsyn till en tillgänglighetsgrupp vars ursprungliga topologi består av ett huvuddatacenter som är värd för tre synkrona tillgänglighetsrepliker, inklusive den primära repliken och ett fjärrdatacenter som är värd för två asynkrona sekundära repliker. Följande bild illustrerar den ursprungliga topologin för den här exempeltillgänglighetsgruppen. Tillgänglighetsgruppen hanteras av ett WSFC-kluster med flera undernät med tre noder i huvuddatacentret (Node 01, Node 02och Node 03) och två noder i ett fjärranslutet datacenter (Node 04 och Node 05).

Huvuddatacentret stängs oväntat av. Deras tre tillgänglighetsrepliker går offline, och deras databaser blir otillgängliga. Följande bild illustrerar effekten av det här felet på tillgänglighetsgruppens topologi.

Databasadministratören (DBA) fastställer att det bästa möjliga svaret är att tvinga en failover av tillgänglighetsgruppen till en av de fjärranslutna, asynkront commit sekundära replikerna. Det här exemplet illustrerar de typiska stegen när du tvingar fram överflyttning av tillgänglighetsgruppen till en fjärrreplik och till sist återställer tillgänglighetsgruppen till dess ursprungliga topologi.
Felsvaret som visas här består av följande två faser:
- Svara på det katastrofala felet i huvuddatacentret
- Returnera tillgänglighetsgruppen till den ursprungliga topologin
Svara på det katastrofala felet i huvuddatacentret
Följande bild visar serien med åtgärder som utförs i fjärrdatacentret som svar på ett oåterkalleligt fel i huvuddatacentret.

Stegen i den här bilden anger följande steg:
| Steg | Handling | Länkar |
|---|---|---|
1. |
DBA eller nätverksadministratören ser till att WSFC-klustret har ett felfritt kvorum. I det här exemplet måste kvorum tvingas fram. |
WSFC-kvorumlägen och röstningskonfiguration (SQL Server) WSFC-katastrofåterställning genom tvingat kvorum (SQL Server) |
2. |
DBA ansluter till serverinstansen med minst latens (på Node 04) och utför en tvingad manuell övertagning. Den framtvingade övergången överför den här sekundära repliken till den primära rollen och suspenderar de sekundära databaserna på den återstående sekundära repliken (på Node 05). | sys.dm_hadr_database_replica_states (Fråga efter kolumnen end_of_log_lsn. Se Rekommendationer tidigare i den här artikeln för mer information.) |
3. |
DBA återupptar var och en av de sekundära databaserna manuellt på den återstående sekundära repliken. | Återuppta en tillgänglighetsdatabas (SQL Server) |
Returnera tillgänglighetsgruppen till den ursprungliga topologin
Följande bild illustrerar de åtgärder som returnerar tillgänglighetsgruppen till den ursprungliga topologin när huvuddatacentret är online igen och WSFC-noderna återupprättar kommunikationen med WSFC-klustret.
Viktig
Om WSFC-klusterkvorumet har tvingats kan de offline noderna, när de startar om, bilda ett nytt kvorum om båda följande villkor är uppfyllda: (a) det finns ingen nätverksanslutning mellan någon av noderna i den tvingade kvorumuppsättningen och (b) de omstartande noderna utgör majoriteten av klusternoderna. Detta skulle resultera i ett "delat hjärntillstånd" där tillgänglighetsgruppen skulle ha två oberoende primära repliker, en i varje datacenter. Innan du tvingar kvorumet att skapa en minoritetskvorumuppsättning kan du läsa WSFC Disaster Recovery through Forced Quorum (SQL Server).
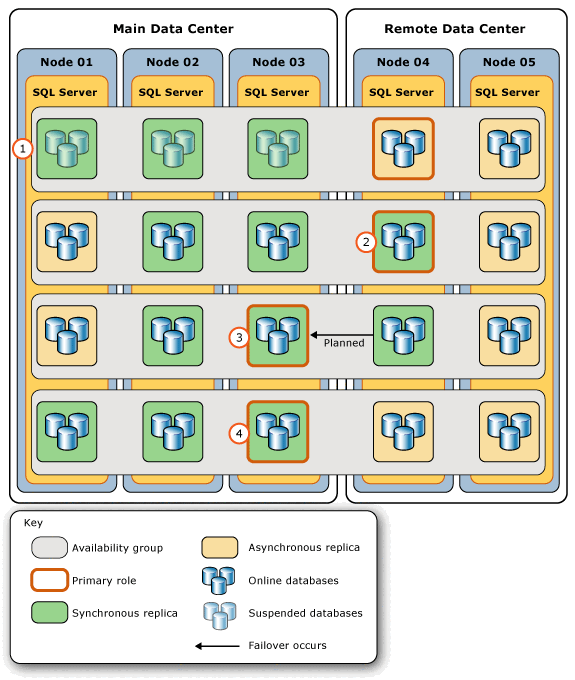
Stegen i den här bilden anger följande steg:
| Steg | Handling | Länkar |
|---|---|---|
1. |
Noderna i huvuddatacentret är online igen och återupprättar kommunikationen med WSFC-klustret. Deras tillgänglighetsrepliker är online som sekundära repliker med inaktiverade databaser, och DBA måste återuppta var och en av dessa databaser manuellt snart. |
Återuppta en tillgänglighetsdatabas (SQL Server) Tips: Om du är orolig för eventuell dataförlust i de primära databaserna efter failover, bör du försöka skapa en ögonblicksbild av databasen på de avstängda databaserna på en sekundär databas med synkron commit. Tänk på att trunkeringen av transaktionsloggen fördröjs på en primär databas medan någon av dess sekundära databaser avbryts. Synkroniseringshälsan för den sekundära repliken synchronous-commit kan inte heller övergå till HEALTHY så länge någon lokal databas förblir avstängd. |
2. |
När databaserna har återupptagits ändrar DBA tillfälligt den nya primära repliken till synkron-committläge. Detta omfattar två steg: 1. Ändra en tillgänglighetsreplik som är offline till asynkront committläge. 2. Ändra den nya primära repliken till synkron commit-läge. Notera: Det här steget gör det möjligt för återupptagen synkron-commit av sekundära databaser att bli SYNCHRONIZED. |
Ändra tillgänglighetsläget för en replik i en AlwaysOn-tillgänglighetsgrupp |
3. |
När den synkrona commit på den sekundära repliken på Nod 03 (den ursprungliga primära repliken) går in i HEALTHY synkroniseringstillstånd utför DBA en planerad manuell omväxling till den repliken för att åter göra den till den primära repliken. Kopian på Node 04 återgår till att vara en sekundär kopia. |
sys.dm_hadr_database_replica_states Använda AlwaysOn-principer för att visa hälsotillståndet för en tillgänglighetsgrupp (SQL Server) Genomföra en planerad manuell redundansväxling för en Always On-tillgänglighetsgrupp (SQL Server) |
4. |
DBA ansluter till den nya primära repliken och: 1. Ändrar tillbaka den tidigare primära repliken (i fjärrcenter) till asynkront commit-läge. 2. Ändrar den sekundära repliken med asynkron-commit i huvuddatacentret tillbaka till synkron-commit-läge. |
Ändra tillgänglighetsläget för en replik i en AlwaysOn-tillgänglighetsgrupp |
Relaterade uppgifter
Justera kvorumröster
- Visa nodviktsinställningar för klusterkvorum
- Konfigurera nodviktsinställningar för klusterkvorum
- Tvinga ett WSFC-kluster att starta utan kvorum
Planerad manuell omställning
- Utföra en planerad manuell redundansväxling av en AlwaysOn-tillgänglighetsgrupp (SQL Server)
- Använd guiden Växla över till en Tillgänglighetsgrupp (SQL Server Management Studio)
Felsökning
- Felsöka Konfiguration av AlwaysOn-tillgänglighetsgrupper (SQL Server)
- Felsöka en misslyckad Add-File åtgärd (Always On-tillgänglighetsgrupper)
Relaterat innehåll
- SQL Server Always On Team-bloggar: Den officiella SQL Server Always On Team-bloggen
- CSS SQL Server Engineers-bloggar
- Microsoft SQL Server Always On Solutions Guide för hög tillgänglighet och katastrofåterställning
- Vad är en AlwaysOn-tillgänglighetsgrupp?
- Skillnader mellan tillgänglighetslägen för en AlwaysOn-tillgänglighetsgrupp
- Failover och failover-lägen (Always On-tilgänglighetsgrupper)
- Typer av klientanslutningar till repliker i en AlwaysOn-tillgänglighetsgrupp
- Verktyg för att övervaka AlwaysOn-tillgänglighetsgrupper
- Windows Server-redundansklustring med SQL Server