Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Spegling i Fabric ger en enkel upplevelse för att undvika komplex ETL (Extrahera, Transformera, Ladda) och integrera din befintliga Azure Databas för PostgreSQL– flexibla servertillstånd med övriga dina data i Microsoft Fabric. Du kan kontinuerligt replikera din befintliga flexibla Azure Database for PostgreSQL-server direkt till Fabrics OneLake. I Fabric kan du låsa upp kraftfull business intelligence, artificiell intelligens, datateknik, datavetenskap och datadelningsscenarier.
För en handledning om hur du konfigurerar din flexibla Azure Database for PostgreSQL-server för spegling i Fabric, se Handledning: Konfigurera Microsoft Fabric-speglade databaser från en flexibel Azure Database for PostgreSQL-server.
Varför ska du använda mirroring i Fabric?
Med spegling i Fabric behöver du inte pussla ihop olika tjänster från flera leverantörer. I stället kan du njuta av en mycket integrerad produkt från slutpunkt till slutpunkt och lätt att använda som är utformad för att förenkla dina analysbehov och som skapats för öppenhet och samarbete mellan Microsoft, Azure Database for PostgreSQL – flexibel server och 1000-tals tekniklösningar som kan läsa Delta Lake-tabellformatet med öppen källkod.
Vilka analysupplevelser är inbyggda?
Speglade databaser är ett objekt i Fabric Data Warehousing som skiljer sig från slutpunkten för lager- och SQL-analys.
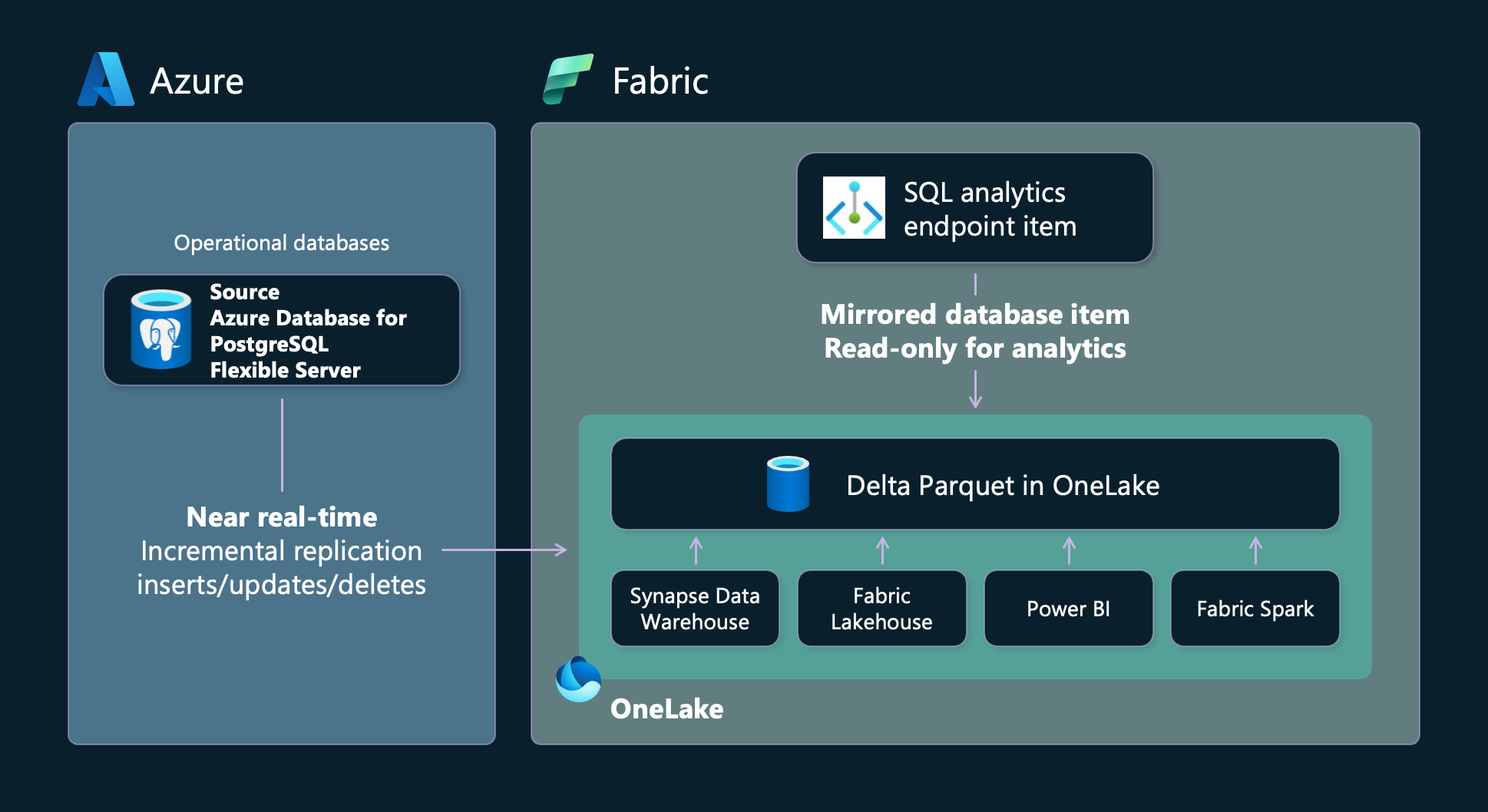
Spegling skapar dessa objekt på din Fabric-arbetsyta:
- Det speglade databasobjektet. Spegling hanterar replikering av data till OneLake och konvertering till Parquet i ett analysklart format. Detta möjliggör nedströmsscenarier som datateknik, datavetenskap med mera.
- En SQL-analysslutpunkt
Varje speglad databas i Azure Database for PostgreSQL – flexibel server har en automatiskt genererad SQL-analysslutpunkt som ger en omfattande analysupplevelse ovanpå deltatabellerna som skapats av speglingsprocessen. Användare har åtkomst till välbekanta T-SQL-kommandon som kan definiera och köra frågor mot dataobjekt men inte manipulera data från SQL-analysslutpunkten, eftersom det är en skrivskyddad kopia. Du kan utföra följande åtgärder i SQL-analysslutpunkten:
- Utforska tabellerna som refererar till data i dina Delta Lake-tabeller från Azure Database for PostgreSQL – flexibel server.
- Skapa inga kodfrågor och vyer och utforska data visuellt utan att skriva en kodrad.
- Utveckla SQL-vyer, infogade TVF:er (Tabellvärdesfunktioner) och lagrade procedurer för att kapsla in din semantik och affärslogik i T-SQL.
- Hantera behörigheter för objekten.
- Hämta data i andra lager och lakehouses i samma miljö.
Förutom SQL-frågeredigeraren finns det ett brett ekosystem med verktyg som kan köra frågor mot SQL-analysslutpunkten, inklusive SQL Server Management Studio (SSMS),mssql-tillägget med Visual Studio Code och till och med GitHub Copilot.
Nätverkskrav
Om din flexibla server inte är offentligt tillgänglig och inte tillåter att Azure-tjänster ansluter till den kan du skapa en virtuell nätverksdatagateway för att spegla data. Kontrollera att Azure Virtual Network eller gatewaydatorns nätverk kan ansluta till den flexibla Azure Database for PostgreSQL-servern via en privat slutpunkt eller att den tillåts av brandväggsregeln.
Aktiva transaktioner, arbetsbelastningar och replikeringsmotorbeteenden
Aktiva transaktioner fortsätter att hålla WAL-trunkeringen kvar tills transaktionen genomförs och den speglade Azure Database for PostgreSQL flexibla servern hinner ifatt, eller tills transaktionen avbryts. Långvariga transaktioner kan leda till att WAL fylls i mer än vanligt. WAL på källan Azure Database for PostgreSQL – flexibel server bör övervakas så att lagringen inte fylls. Mer information finns i WAL växer på grund av långvariga transaktioner och CDC.
Varje användararbetsbelastning varierar. Under den första ögonblicksbilden kan det finnas mer resursanvändning i källdatabasen, för både CPU och IOPS (indata-/utdataåtgärder per sekund, för att läsa sidorna). Tabelluppdateringar/borttagningsåtgärder kan leda till ökad logggenerering. Läs mer om hur du övervakar resurser för din flexibla Azure Database for PostgreSQL-server.
Stöd för beräkningsnivå
Källan Azure Database for PostgreSQL flexibla server kan vara antingen en allmänt ändamål eller minnesoptimerad beräkningsnivå. Burstbar beräkningsnivå stöds inte som källa för spegling.
Mer information om beräkningsnivåer som är tillgängliga i flexibel Azure Database for PostgreSQL-server finns i Beräkningsalternativ i Azure Database for PostgreSQL – flexibel server.
Nästa steg
Relaterat innehåll
- Så här gör du: Skydda data i Microsoft Fabric-speglade databaser från Azure Database for PostgreSQL flexibel server
- Begränsningar i replikerade databaser i Microsoft Fabric från Azure Database för PostgreSQL-flexibel server
- Övervaka Fabric-replikering av databaser
- Felsöka infrastrukturspeglingsdatabaser från Azure Database for PostgreSQL – flexibel server