Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Lär dig hur du enkelt berikar dina data i dedikerade SQL-pooler med förutsägande maskininlärningsmodeller. De modeller som dina dataforskare skapar är nu lättillgängliga för dataproffs för förutsägelseanalys. En datatekniker i Azure Synapse Analytics kan helt enkelt välja en modell från Azure Machine Learning-modellregistret för distribution i Azure Synapse SQL-pooler och starta förutsägelser för att utöka data.
I den här självstudien får du lära dig att:
- Träna en förutsägande maskininlärningsmodell och registrera modellen i Azure Machine Learning-modellregistret.
- Använd SQL-bedömningsguiden för att starta förutsägelser i en dedikerad SQL-pool.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Azure Synapse Analytics-arbetsyta med ett Azure Data Lake Storage Gen2-lagringskonto konfigurerat som standardlagring. Du måste vara Storage Blob Data-bidragsgivare för Data Lake Storage Gen2-filsystemet som du arbetar med.
- Dedikerad SQL-pool på din Azure Synapse Analytics-arbetsyta. Mer information finns i Skapa en dedikerad SQL-pool.
- Länkad Azure Machine Learning-tjänst på din Azure Synapse Analytics-arbetsyta. Mer information finns i Skapa en länkad Azure Machine Learning-tjänst i Azure Synapse.
Logga in på Azure-portalen
Logga in på Azure-portalen.
Träna en modell i Azure Machine Learning
Innan du börjar kontrollerar du att din version av sklearn är 0.20.3.
Innan du kör alla celler i notebook-filen, se till att beräkningsinstansen är igång.
Gå till din Azure Machine Learning-arbetsyta.
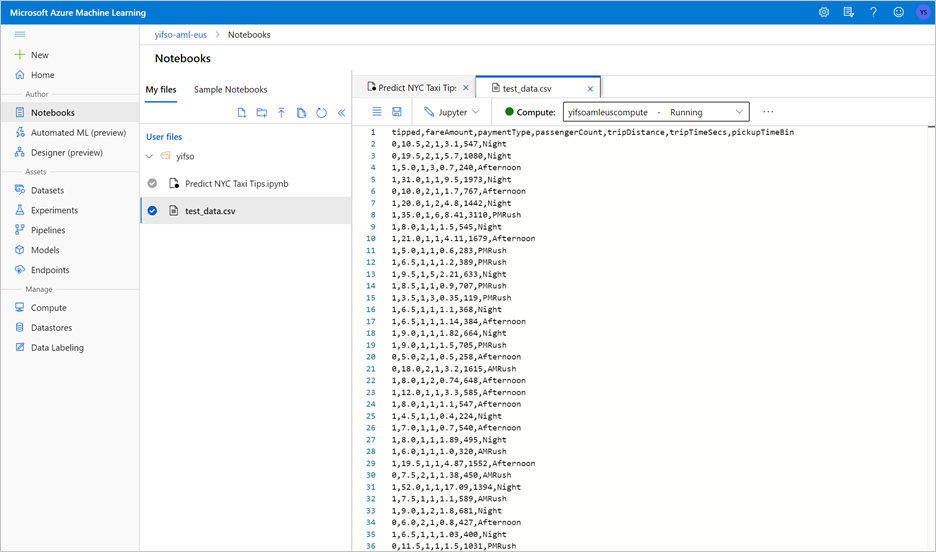
Ladda ned Predict NYC Taxi Tips.ipynb.
Öppna Azure Machine Learning-arbetsytan i Azure Machine Learning Studio.
Gå till Anteckningsböcker>Ladda upp filer. Välj sedan filen Predict NYC Taxi Tips.ipynb som du laddade ned och laddade upp den.
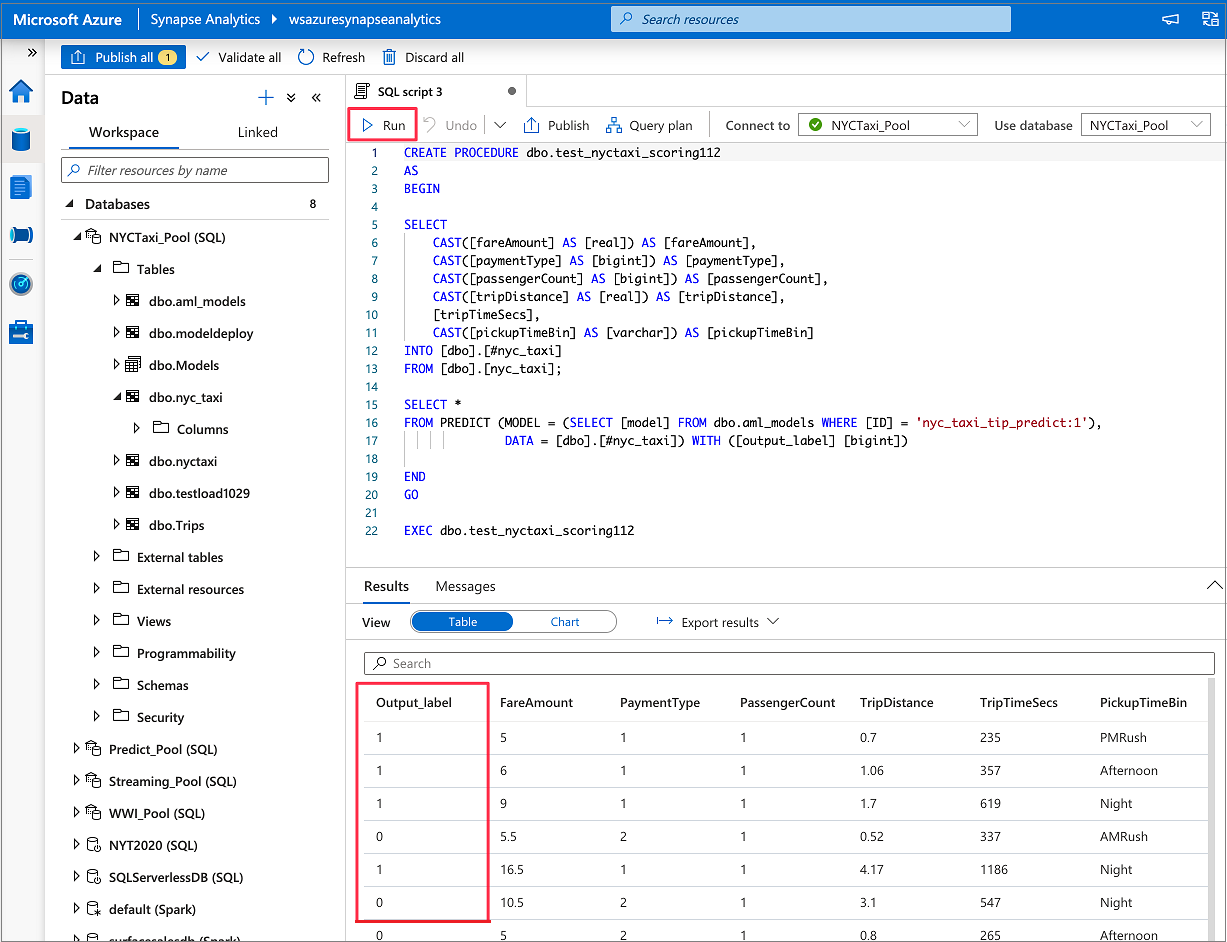
När anteckningsboken har laddats upp och öppnats väljer du Kör alla celler.
En av cellerna kan misslyckas och be dig att autentisera till Azure. Håll utkik efter detta i cellutdata och autentisera i webbläsaren genom att följa länken och ange koden. Kör sedan anteckningsboken igen.
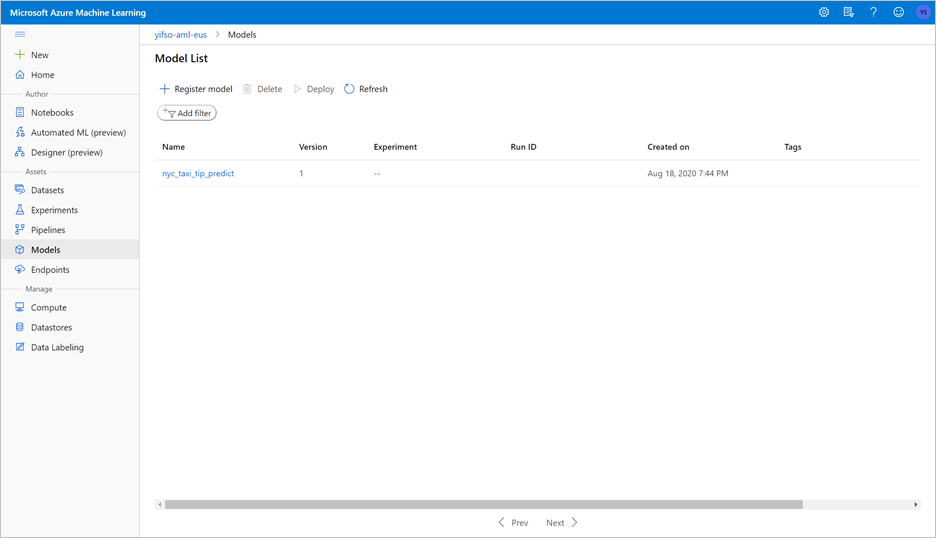
Anteckningsboken tränar en ONNX-modell och registrerar den med MLflow. Gå till modeller för att kontrollera att den nya modellen är korrekt registrerad.
När du kör notebook exporteras även testdata till en CSV-fil. Ladda ned CSV-filen till ditt lokala system. Senare importerar du CSV-filen till en dedikerad SQL-pool och använder data för att testa modellen.
CSV-filen skapas i samma mapp som notebook-filen. Välj Uppdatera i Utforskaren om du inte ser det direkt.
Starta förutsägelser med SQL-bedömningsguiden
Öppna Azure Synapse-arbetsytan med Synapse Studio.
Gå till Data>Länkade>Lagringskonton. Ladda upp
test_data.csvtill standardlagringskontot.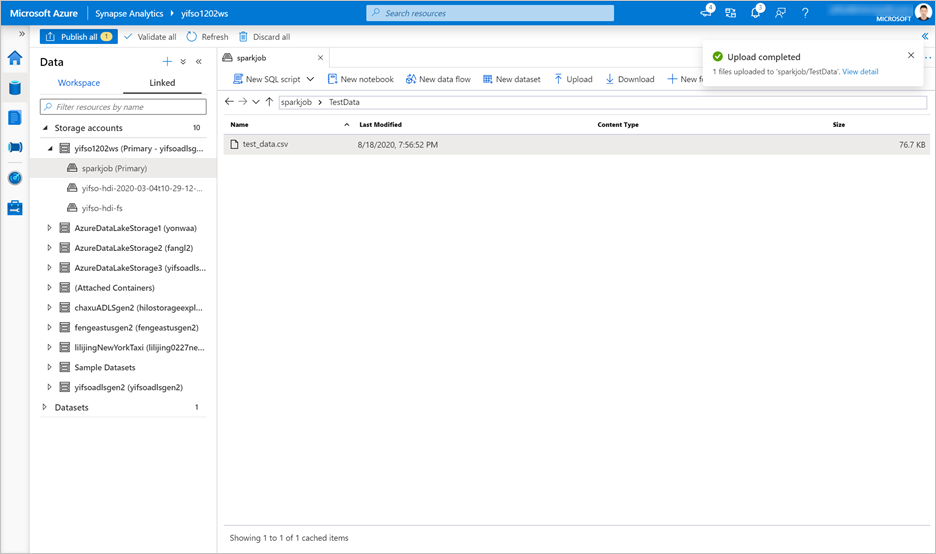
Gå till Utveckla>SQL-skript. Skapa ett nytt SQL-skript för att läsa in
test_data.csvi din dedikerade SQL-pool.Anmärkning
Uppdatera fil-URL:en i det här skriptet innan du kör den.
IF NOT EXISTS (SELECT * FROM sys.objects WHERE NAME = 'nyc_taxi' AND TYPE = 'U') CREATE TABLE dbo.nyc_taxi ( tipped int, fareAmount float, paymentType int, passengerCount int, tripDistance float, tripTimeSecs bigint, pickupTimeBin nvarchar(30) ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ) GO COPY INTO dbo.nyc_taxi (tipped 1, fareAmount 2, paymentType 3, passengerCount 4, tripDistance 5, tripTimeSecs 6, pickupTimeBin 7) FROM '<URL to linked storage account>/test_data.csv' WITH ( FILE_TYPE = 'CSV', ROWTERMINATOR='0x0A', FIELDQUOTE = '"', FIELDTERMINATOR = ',', FIRSTROW = 2 ) GO SELECT TOP 100 * FROM nyc_taxi GO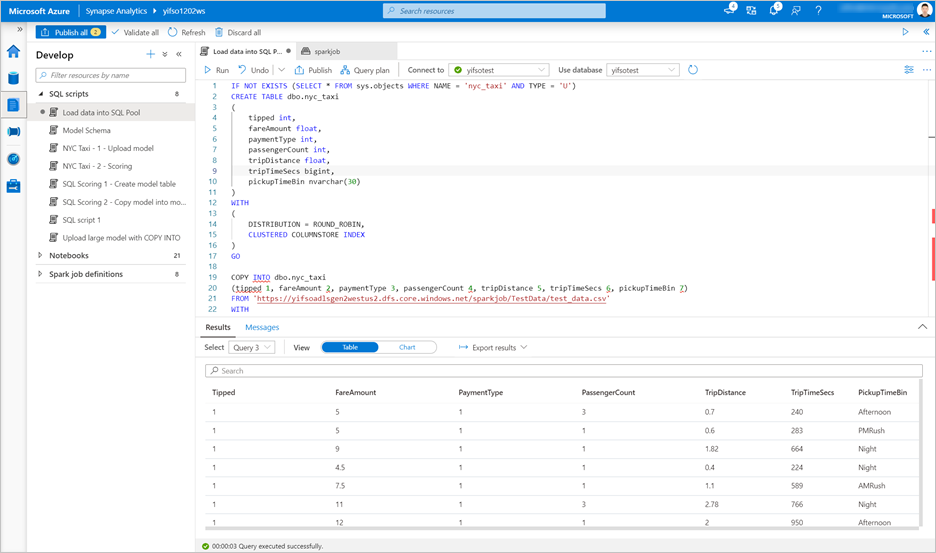
Gå till Data>Workspace. Öppna SQL-bedömningsguiden genom att högerklicka på den dedikerade SQL-pooltabellen. Välj Machine Learning>Förutsäg med en modell.
Anmärkning
Maskininlärningsalternativet visas inte om du inte har en länkad tjänst som skapats för Azure Machine Learning. (Se förutsättningar i början av den här guiden.)
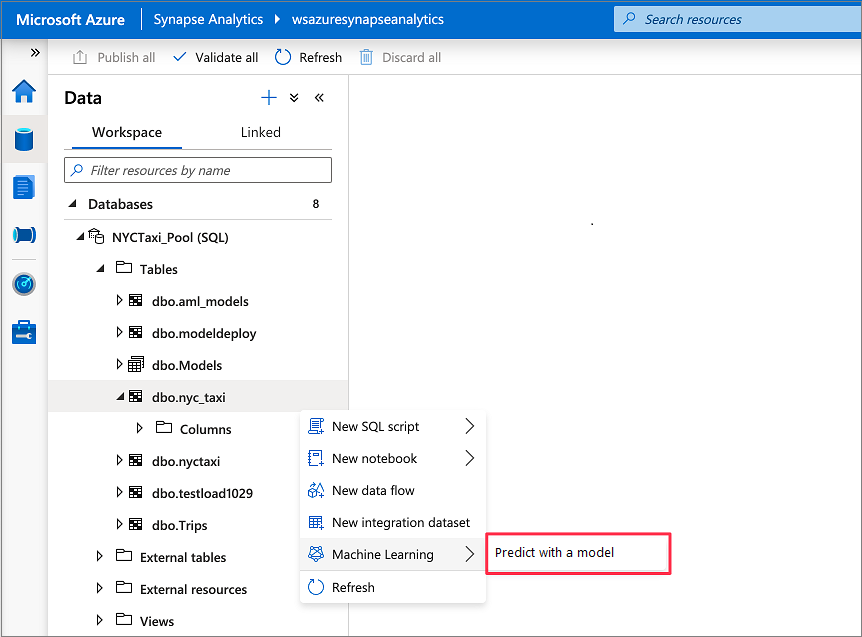
Välj en länkad Azure Machine Learning-arbetsyta i listrutan. Det här steget läser in en lista över maskininlärningsmodeller från modellregistret för den valda Azure Machine Learning-arbetsytan. För närvarande stöds endast ONNX-modeller, så det här steget visar endast ONNX-modeller.
Välj den modell som du precis har tränat och välj sedan Fortsätt.
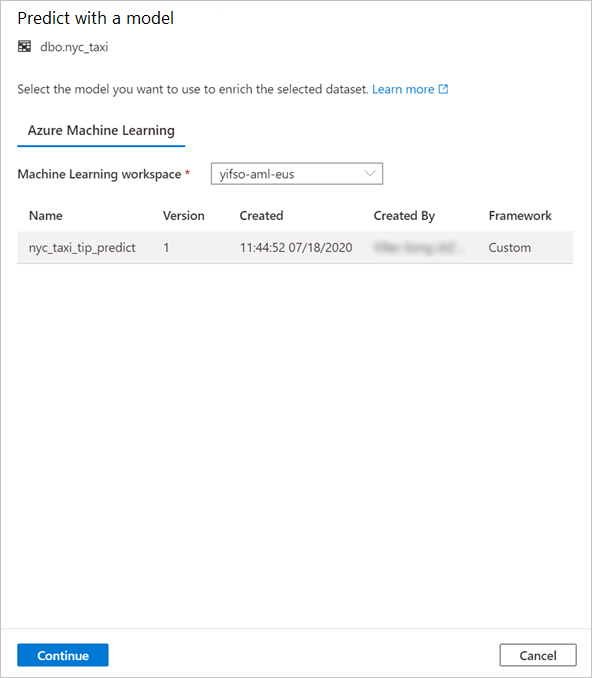
Mappa tabellkolumnerna till modellindata och ange modellutdata. Om modellen sparas i MLflow-format och modellsignaturen fylls i görs mappningen automatiskt åt dig med hjälp av en logik som baseras på likheten mellan namn. Gränssnittet stöder även manuell mappning.
Välj Fortsätt.
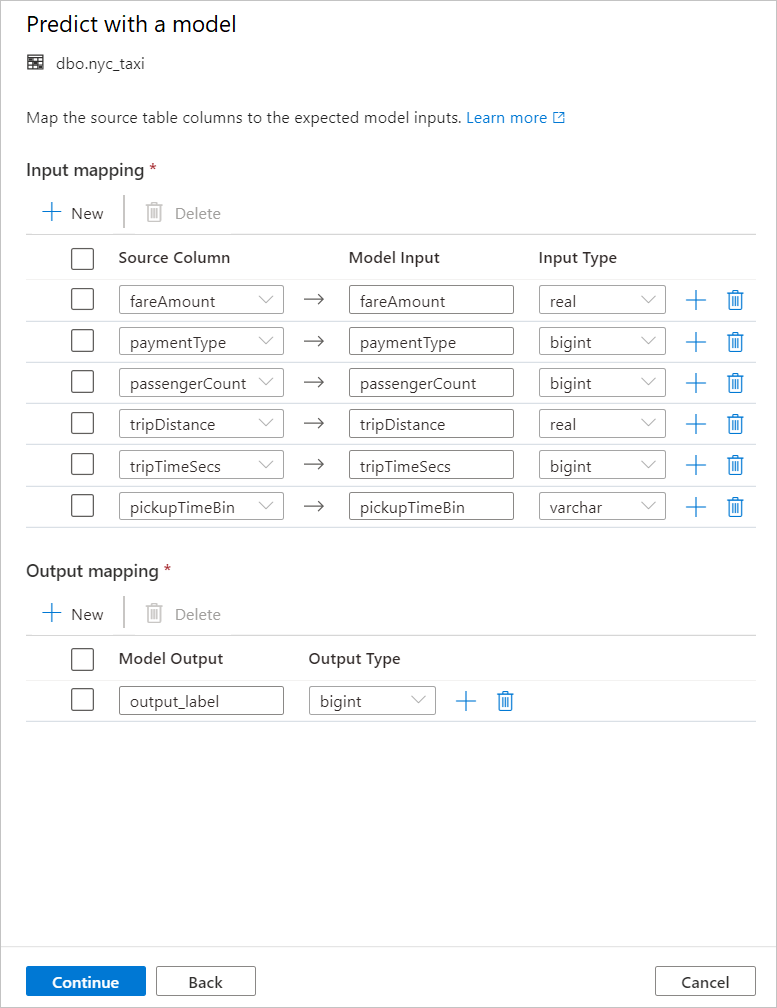
Den genererade T-SQL-koden omsluts i en lagrad procedur. Därför måste du ange ett lagrat procedurnamn. Modellbinärfilen, inklusive metadata (version, beskrivning och annan information), kopieras fysiskt från Azure Machine Learning till en dedikerad SQL-pooltabell. Så du måste ange vilken tabell som modellen ska sparas i.
Du kan välja antingen Befintlig tabell eller Skapa ny. När du är klar väljer du Distribuera modell + öppna skript för att distribuera modellen och generera ett T-SQL-förutsägelseskript.
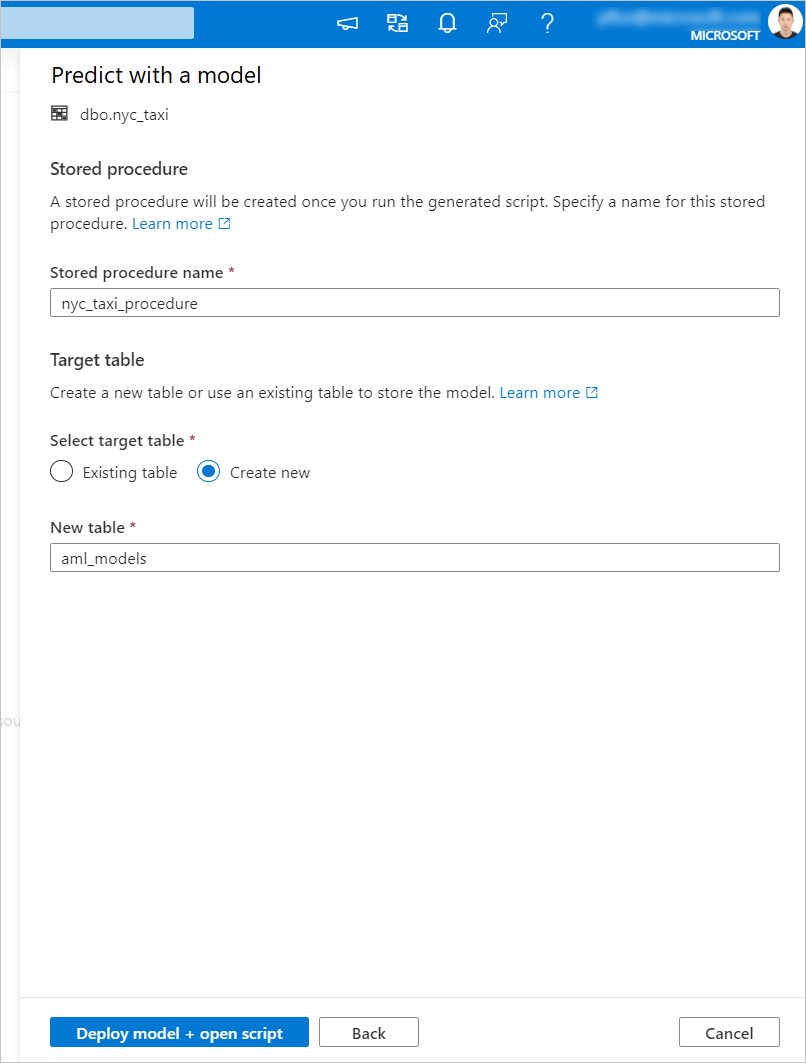
När skriptet har genererats väljer du Kör för att köra poängsättningen och hämta förutsägelser.