Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln innehåller lösningar på vanliga problem som kan uppstå när du använder typen EventProcessorClient . Om du letar efter lösningar på andra vanliga problem som du kan stöta på när du använder Azure Event Hubs kan du läsa Felsöka Azure Event Hubs.
412 förhandsvillkorsfel när du använder en händelseprocessor
412 förhandsvillkorsfel uppstår när klienten försöker ta eller förnya ägarskapet för en partition, men den lokala versionen av ägarskapsposten är inaktuell. Det här problemet uppstår när en annan processorinstans stjäl partitionsägarskapet. Mer information finns i nästa avsnitt.
Ägarskap för partitioner ändras ofta
När antalet EventProcessorClient instanser ändras (det vill säga läggs till eller tas bort) försöker de körande instanserna att fördela belastningen på partitionerna mellan sig. Under några minuter efter att antalet processorer har ändrats förväntas partitionerna ändra ägare. När den är balanserad bör partitionsägarskapet vara stabilt och ändras sällan. Om partitionsägarskapet ändras ofta när antalet processorer är konstant indikerar det sannolikt ett problem. Vi rekommenderar att du skapar ett GitHub-ärende med loggar och en reproduktion av problemet.
Partitionsägarskapet bestäms via ägandeposterna i CheckpointStore. Vid varje belastningsutjämningsintervall EventProcessorClient utför will följande uppgifter:
- Hämta de senaste ägardokumenten.
- Kontrollera posterna för att se vilka poster som inte har uppdaterat tidsstämpeln inom förfallointervallet för partitionsägarskapet. Endast poster som matchar detta villkor beaktas.
- Om det finns några obeägda partitioner och belastningen inte balanseras mellan instanser av
EventProcessorClientförsöker händelseprocessorklienten göra anspråk på en partition. - Uppdatera ägarskapsposten för de partitioner som den äger och som har en aktiv länk till partitionen.
Du kan konfigurera intervaller för belastningsutjämning och förfallotider för ägarskap när du skapar EventProcessorClient via EventProcessorClientBuilder, enligt beskrivningen i följande lista:
- Metoden loadBalancingUpdateInterval(Duration) anger hur ofta belastningsutjämningscykeln körs.
- Metoden partitionOwnershipExpirationInterval(Duration) anger den minsta tiden sedan ägarskapsposten har uppdaterats, innan processorn anser att en partition är obevakad.
Om en förändring av ägarregister till exempel uppdaterades klockan 09:30 och partitionOwnershipExpirationInterval tar 2 minuter. När en cykel för belastningsutjämning inträffar och den märker att ägarskapsregistret inte har uppdaterats inom de senaste 2 minuterna eller senast kl. 09:32, kommer partitionen att betraktas som oägd.
Om ett fel inträffar i en av partitionskonsumenterna stänger den motsvarande konsumenten men försöker inte återta den förrän nästa belastningsbalanseringscykel.
Den aktuella mottagaren "<RECEIVER_NAME>" med epok "0" kopplas från.
Hela felmeddelandet ser ut ungefär så här:
New receiver 'nil' with higher epoch of '0' is created hence current receiver 'nil' with epoch '0'
is getting disconnected. If you are recreating the receiver, make sure a higher epoch is used.
TrackingId:<GUID>, SystemTracker:<NAMESPACE>:eventhub:<EVENT_HUB_NAME>|<CONSUMER_GROUP>,
Timestamp:2022-01-01T12:00:00}"}
Det här felet förväntas när belastningsutjämning inträffar när EventProcessorClient instanser har lagts till eller tagits bort. Belastningsutjämning är en pågående process. När du använder BlobCheckpointStore med din konsument kontrollerar konsumenten var ~30:e sekund (som standard) vilka konsumenter som har ett anspråk för varje partition och kör sedan viss logik för att avgöra om den behöver "stjäla" en partition från en annan konsument. Den servicemekanism som används för att hävda exklusivt ägande över en partition kallas Epoch.
Men om inga instanser läggs till eller tas bort finns det ett underliggande problem som bör åtgärdas. Mer information finns i avsnittet Ändringar av partitionsägarskap sker ofta och Rapportera GitHub-problem.
Hög processoranvändning
Hög CPU-användning beror vanligtvis på att en instans äger för många partitioner. Vi rekommenderar att du inte har fler än tre partitioner för varje processorkärna. Det är bättre att börja med 1,5 partitioner för varje CPU-kärna och sedan testa genom att öka antalet partitioner som ägs.
Slut på minne och välja heapstorlek
Problemet med slut på minne (OOM) kan inträffa om den aktuella maxhögen för JVM inte är tillräcklig för att köra programmet. Du kanske vill mäta applikationens minnesbehov. Baserat på resultatet ändrar du sedan storleken på heapen genom att ange lämpligt maximalt heapminne med hjälp av -Xmx JVM-alternativet.
Du bör inte ange -Xmx som ett värde större än det tillgängliga minnet eller gränsen som satts för värden (den virtuella datorn eller containern) – till exempel det minne som begärdes i containerns konfiguration. Du bör allokera tillräckligt med minne för värden för att stödja Java-heapen.
Följande steg beskriver ett typiskt sätt att mäta värdet för maximal Java Heap:
Kör programmet i en miljö nära produktion, där programmet skickar, tar emot och bearbetar händelser under den högsta belastning som förväntas i produktionen.
Vänta tills programmet når ett stabilt tillstånd. I det här skedet skulle programmet och JVM ha läst in alla domänobjekt, klasstyper, statiska instanser, objektpooler (TCP, DB-anslutningspooler) osv.
I det stadiga tillståndet ser du det stabila sågtandsformade mönstret för heap-samlingen, som visas i följande skärmbild.
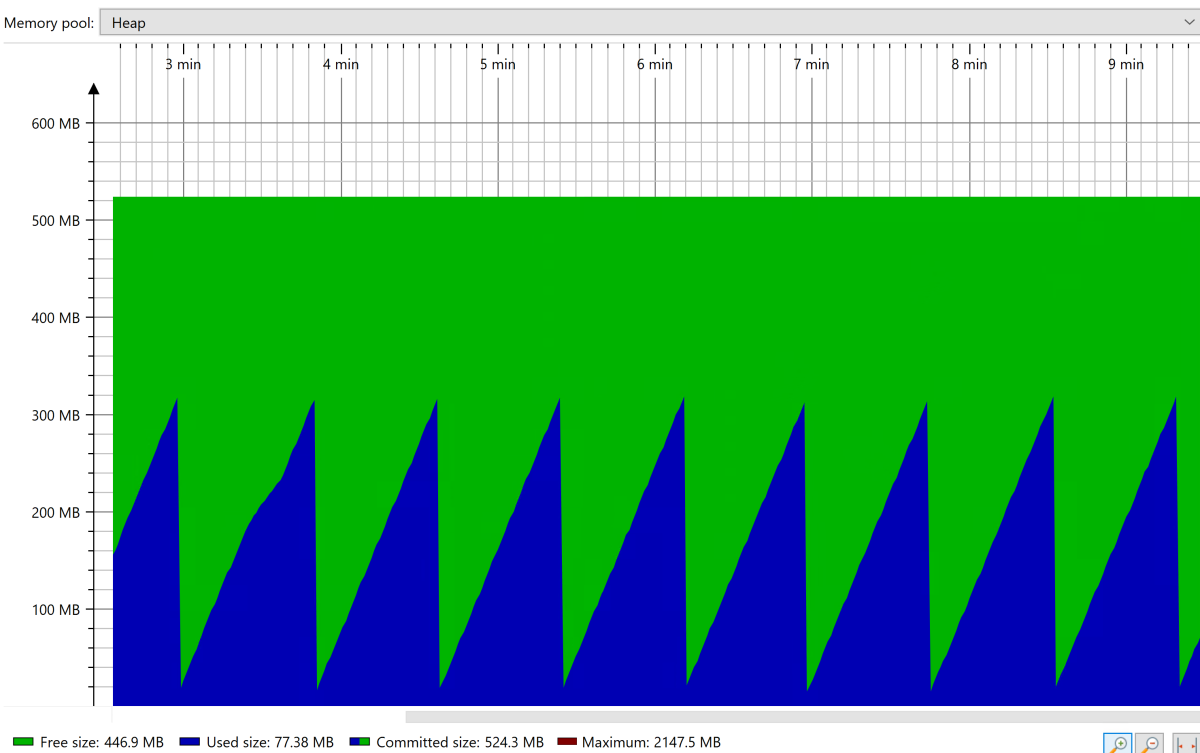
När programmet har nått stabilt tillstånd framtvingar du en fullständig skräpinsamling (GC) med hjälp av verktyg som JConsole. Observera det minne som upptas efter den fullständiga GC:en. Du vill anpassa högen så att endast 30% är upptagna efter fullständig GC. Du kan använda det här värdet för att ange maximal heapstorlek (med
-Xmx).

Om du använder containern ska du ändra storleken på containern så att den har ytterligare ~1 GB minne för det icke-heap minnesbehov som behövs för JVM-instansen.
Processorklienten upphör att ta emot
Processorklienten körs ofta kontinuerligt i ett värdprogram i flera dagar i sträck. Ibland märker den att EventProcessorClient inte bearbetar en eller flera partitioner. Vanligtvis finns det inte tillräckligt med information för att avgöra varför undantaget inträffade. Stoppet EventProcessorClient är symptomet på en underliggande orsak (dvs. kapplöpningstillståndet) som inträffade när man försökte återhämta sig från ett tillfälligt fel. Den informationen vi behöver finns i Rapportera GitHub-ärenden.
Duplicera EventData som tas emot när processorn startas om
Event EventProcessorClient Hubs-tjänsten och garanterar en leverans minst en gång . Du kan lägga till metadata för att urskilja duplicerade händelser. Mer information finns i Garanterar Azure Event Hubs en leverans minst en gång? på Stack Overflow. Om du bara behöver leverans en gång bör du överväga Service Bus, som väntar på en bekräftelse från klienten. En jämförelse av meddelandetjänsterna finns i Välja mellan Azure-meddelandetjänster.
Konsumentklient på låg nivå slutar ta emot
EventHubConsumerAsyncClient är en konsumentklient på låg nivå som tillhandahålls av Event Hubs-biblioteket, utformat för avancerade användare som behöver större kontroll och flexibilitet för sina reaktiva program. Den här klienten erbjuder ett lågnivågränssnitt som gör det möjligt för användare att hantera mottryck, trådhantering och återhämtning i reaktorflödet. Till skillnad från EventProcessorClientinnehåller EventHubConsumerAsyncClient inte automatiska återställningsmekanismer för alla terminalorsaker. Därför måste användarna hantera terminalhändelser och välja lämpliga reaktoroperatorer för att implementera återställningsstrategier.
Metoden EventHubConsumerAsyncClient::receiveFromPartition genererar ett terminalfel när anslutningen stöter på ett fel som inte kan försökas igen eller när en serie anslutningsåterställningsförsök misslyckas i följd, vilket uttömmer den maximala återförsöksgränsen. Även om mottagaren på låg nivå försöker återställa från tillfälliga fel förväntas användare av konsumentklienten hantera terminalhändelser. Om kontinuerlig händelsemottagning önskas bör programmet justera reaktorkedjan för att skapa en ny konsumentklient för en terminalhändelse.
Migrera från äldre till nytt klientbibliotek
Migreringsguiden innehåller steg för att migrera från den äldre klienten och migrera äldre kontrollpunkter.
Nästa steg
Om felsökningsguiden i den här artikeln inte hjälper dig att lösa problem när du använder Azure SDK för Java-klientbibliotek rekommenderar vi att du ange ett problem i Azure SDK för Java GitHub-lagringsplatsen.