Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här självstudien vägleder dig genom grunderna i att utföra undersökande dataanalys (EDA) med python i en Azure Databricks-anteckningsbok, från att läsa in data till att generera insikter via datavisualiseringar.
Anteckningsboken som används i den här handledningen undersöker globala energi- och utsläppsdata och visar hur man läser in, rensar och utforskar data.
Du kan följa exempelanteckningsboken eller skapa en egen anteckningsbok från grunden.
Vad är EDA?
Undersökande dataanalys (EDA) är ett viktigt första steg i datavetenskapsprocessen som omfattar analys och visualisering av data för att:
- Upptäck dess viktigaste egenskaper.
- Identifiera mönster och trender.
- Identifiera avvikelser.
- Förstå relationer mellan variabler.
EDA ger insikter om datamängden, vilket underlättar välgrundade beslut om ytterligare statistiska analyser eller modellering.
Med Azure Databricks-notebook-filer kan dataforskare utföra EDA med hjälp av välbekanta verktyg. I den här självstudien används till exempel några vanliga Python-bibliotek för att hantera och rita data, inklusive:
- Numpy: ett grundläggande bibliotek för numerisk databehandling som ger stöd för arrayer, matriser och en mängd olika matematiska funktioner för att arbeta med dessa datatyper.
- Pandas: ett kraftfullt datamanipulerings- och analysbibliotek som bygger på NumPy och som erbjuder datastrukturer som DataFrames för att effektivt hantera strukturerade data.
- Plotly: ett interaktivt grafbibliotek som gör det möjligt att skapa interaktiva visualiseringar av hög kvalitet för dataanalys och presentation.
- Matplotlib: ett omfattande bibliotek för att skapa statiska, animerade och interaktiva visualiseringar i Python.
Azure Databricks innehåller också inbyggda funktioner som hjälper dig att utforska dina data i notebook-utdata, till exempel att filtrera och söka efter data i tabeller och zooma in på visualiseringar. Du kan också använda Databricks Assistant för att skriva kod för EDA.
Innan du börjar
För att slutföra den här självstudien behöver du följande:
- Du måste ha behörighet att använda en befintlig beräkningsresurs eller skapa en ny beräkningsresurs. Se Beräkna.
- [Valfritt] Den här guiden beskriver hur du använder assistenten för att generera kod. Om du vill använda assistenten måste assistenten vara aktiverad på ditt konto och din arbetsyta. Mer information finns i Använda Databricks Assistant .
Ladda ned datauppsättningen och importera CSV-filen
Den här handledningen visar tekniker för explorativ dataanalys genom att undersöka den globala energidatan och utsläppsdatan. För att följa med, ladda ner Our World in Datas Energy Consumption Dataset från Kaggle. I den här handledningen används filen owid-energy-data.csv.
Så här importerar du datauppsättningen till din Azure Databricks-arbetsyta:
I sidofältet på arbetsytan klickar du på Arbetsyta för att navigera till arbetsytans webbläsare.
Dra och släpp CSV-filen
owid-energy-data.csvtill din arbetsyta.Då öppnas modalen Import. Observera mappen Target som anges här. Detta är inställt på den aktuella mappen i arbetsytans webbläsare och blir den importerade filens mål.
Klicka på Importera. Filen ska visas i målmappen i din arbetsyta.
Du behöver filsökvägen för att öppna filen i din notebook senare. Leta reda på filen i arbetsytans webbläsare. För att kopiera filsökvägen till klippbordet, högerklicka på filnamnet och välj sedan Kopiera URL/sökväg>Fullständig sökväg.
Skapa en ny notebook
Om du vill skapa en ny notebook-fil i användarens hemmapp klickar du på ![]() Ny i sidofältet och väljer Notebook på menyn.
Ny i sidofältet och väljer Notebook på menyn.
Längst upp, bredvid anteckningsbokens namn, väljer du Python som standardspråk för notebook-filen.
Mer information om hur du skapar och hanterar notebook-filer finns i Hantera notebook-filer.
Lägg till vart och ett av kodexemplen i den här artikeln i en ny cell i anteckningsboken. Eller, använd exempelanteckningsboken som tillhandahålls för att följa med i handledningen.
Läs in CSV-fil
I en ny notebookcell läser du in CSV-filen. Det gör du genom att importera numpy och pandas. Det här är användbara Python-bibliotek för datavetenskap och analys.
Skapa en Pandas DataFrame från datauppsättningen för enklare bearbetning och visualisering. Ersätt filsökvägen nedan med den som du kopierade tidigare.
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
Kör cellen. Utdata ska returnera Pandas DataFrame, inklusive en lista över varje kolumn och dess typ.

Förstå datan
Att förstå grunderna i datamängden är avgörande för alla datavetenskapsprojekt. Det handlar om att bekanta sig med strukturen, typerna och kvaliteten på de data som finns till hands.
I en Azure Databricks-notebook-fil kan du använda kommandot display(df) för att visa datauppsättningen.

Eftersom datamängden har fler än 10 000 rader returnerar det här kommandot en trunkerad datauppsättning. Till vänster om varje kolumn kan du se kolumnens datatyp. För att lära dig mer, se Formatera kolumner.
Använda Pandas för datainsikter
Om du vill förstå din datauppsättning effektivt använder du följande Pandas-kommandon:
Kommandot
df.shapereturnerar dataramens dimensioner, vilket ger dig en snabb översikt över antalet rader och kolumner.
Kommandot
df.dtypesinnehåller datatyperna för varje kolumn, vilket hjälper dig att förstå vilken typ av data du hanterar. Du kan också se datatypen för varje kolumn i resultattabellen.
Kommandot
df.describe()genererar beskrivande statistik för numeriska kolumner, till exempel medelvärde, standardavvikelse och percentiler, som kan hjälpa dig att identifiera mönster, identifiera avvikelser och förstå fördelningen av dina data. Använd den meddisplay()för att se sammanfattningsstatistik i ett tabellformat som du kan interagera med. Se Utforska datan med Databricks anteckningsboksutdattabell.
Generera en dataprofil
Anmärkning
Finns i Databricks Runtime 9.1 LTS och senare.
Azure Databricks-notebook-filer innehåller inbyggda funktioner för dataprofilering. När du visar en DataFrame med Azure Databricks-visningsfunktionen kan du generera en dataprofil från tabellutdata.
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)

Klicka på +>Dataprofil bredvid Tabell i utdata. Detta kör ett nytt kommando som genererar en profil för data i DataFrame.

Dataprofilen innehåller sammanfattningsstatistik för numeriska kolumner, sträng- och datumkolumner samt histogram över värdefördelningen för varje kolumn. Du kan också generera dataprofiler programmatiskt. se kommandot summarize (dbutils.data.summarize).
Rensa data
Att rensa data är ett viktigt steg i EDA för att säkerställa att datamängden är korrekt, konsekvent och redo för meningsfull analys. Den här processen omfattar flera viktiga uppgifter för att säkerställa att data är redo för analys, inklusive:
- Identifiera och ta bort dubblettdata.
- Hantering av saknade värden, vilket kan innebära att ersätta dem med ett visst värde eller ta bort de berörda raderna.
- Standardisera datatyper (till exempel konvertera strängar till
datetime) genom konverteringar och omvandlingar för att säkerställa konsekvens. Du kanske också vill konvertera data till ett format som är enklare för dig att arbeta med.
Den här rengöringsfasen är viktig eftersom den förbättrar datakvaliteten och tillförlitligheten, vilket möjliggör mer exakt och insiktsfull analys.
Tips: Använd Databricks Assistant för att hjälpa till med datarensningsuppgifter
Du kan använda Databricks Assistant för att generera kod. Skapa en ny kodcell och klicka på generera länk eller använd assistentikonen längst upp till höger för att öppna assistenten. Ange en fråga för assistenten. Assistenten kan antingen generera Python- eller SQL-kod eller generera en textbeskrivning. Om du vill ha olika resultat klickar du på Återskapa.
Prova till exempel följande uppmaningar om att använda assistenten för att rensa data:
- Kontrollera om
dfinnehåller dubbletter av kolumner eller rader. Skriv ut dubbletterna. Ta sedan bort dubbletterna. - Vilket format är datumkolumner i? Ändra den till
'YYYY-MM-DD'. - Jag tänker inte använda
XXXkolumnen. Ta bort den.
Se Få kodningshjälp från Databricks Assistant.
Ta bort dubbeldata
Kontrollera om data har dubbletter av rader eller kolumner. I så fall tar du bort dem.
Tips
Använd assistenten för att generera kod åt dig.
Försök att skriv in följande kommando: "Kontrollera om df innehåller några dubbletter av kolumner eller av rader." Skriv ut dubbletterna. Ta sedan bort dubbletterna." Assistenten kan generera kod som exemplet nedan.
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
I det här fallet har datasetet inga dubbletter av data.
Hantera null- eller saknade värden
Ett vanligt sätt att behandla NaN- eller Null-värden är att ersätta dem med 0 för enklare matematisk bearbetning.
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
Detta säkerställer att saknade data i DataFrame ersätts med 0, vilket kan vara användbart för efterföljande dataanalyser eller bearbetningssteg där saknade värden kan orsaka problem.
Formatera om datum
Datum formateras ofta på olika sätt i olika datauppsättningar. De kan vara i datumformat, strängar eller heltal.
För den här analysen behandlar du kolumnen year som ett heltal. Följande kod är ett sätt att göra detta:
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
Detta säkerställer att kolumnen year endast innehåller heltal för årtal, med ogiltiga poster som konverterats till NaT (Inte en Tid).
Utforska data med hjälp av Databricks notebook-utdatatabell
Azure Databricks innehåller inbyggda funktioner som hjälper dig att utforska dina data med hjälp av utdatatabellen.
I en ny cell använder du display(df) för att visa datamängden som en tabell.

Med hjälp av utdatatabellen kan du utforska dina data på flera sätt:
- Sök efter en specifik sträng eller ett visst värde
- Filtrera efter specifika villkor
- Skapa visualiseringar med hjälp av datauppsättningen
Sök efter en specifik sträng eller ett visst värde i data
Klicka på sökikonen längst upp till höger i tabellen och ange din sökning.

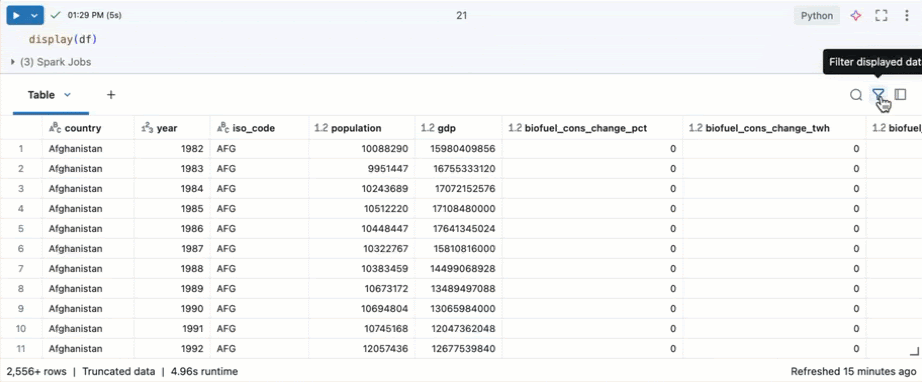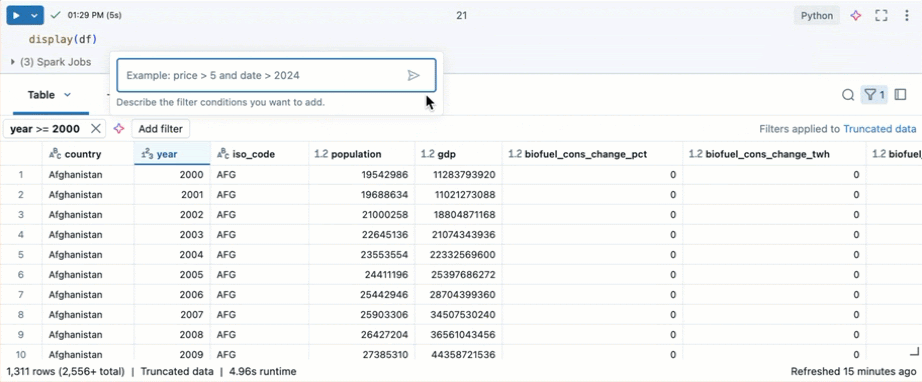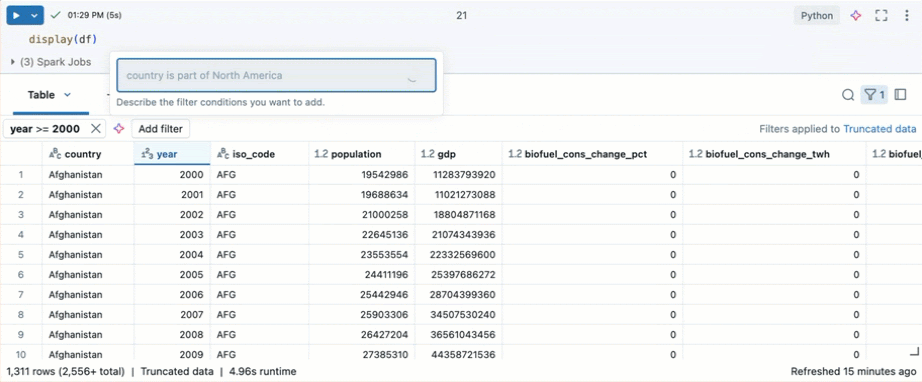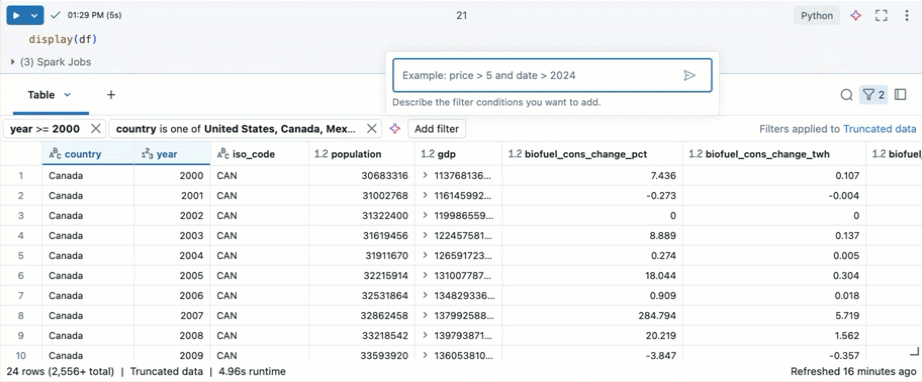
Filtrera efter specifika villkor
Du kan använda inbyggda tabellfilter för att filtrera kolumnerna efter specifika villkor. Det finns flera sätt att skapa ett filter. Se Filterresultat.
Tips
Använd Databricks Assistant för att skapa filter. Klicka på filterikonen i det övre högra hörnet i tabellen. Ange ditt filtervillkor. Databricks Assistant genererar automatiskt ett filter åt dig.
Skapa visualiseringar med hjälp av datauppsättningen
Längst upp i utdatatabellen klickar du på +>Visualisering för att öppna visualiseringsredigeraren.

Välj den visualiseringstyp och de kolumner som du vill visualisera. Redigeraren visar en förhandsgranskning av diagrammet baserat på din konfiguration. Bilden nedan visar till exempel hur du lägger till flera linjediagram för att visa förbrukningen av olika förnybara energikällor över tid.

Klicka på Spara för att lägga till visualiseringen som en flik i cellutdata.
Utforska och visualisera data med hjälp av Python-bibliotek
Att utforska data med hjälp av visualiseringar är en grundläggande aspekt av EDA. Visualiseringar hjälper till att upptäcka mönster, trender och relationer i data som kanske inte är direkt synliga enbart genom numerisk analys. Använd bibliotek som Plotly eller Matplotlib för vanliga visualiseringstekniker som punktdiagram, stapeldiagram, linjediagram och histogram. Dessa visuella verktyg gör det möjligt för dataexperter att identifiera avvikelser, förstå datadistributioner och observera korrelationer mellan variabler. Punktdiagram kan till exempel markera extremvärden, medan tidsseriediagram kan visa trender och säsongsvariationer.
- Skapa en matris för unika länder
- Diagrammets utsläppstrender för de 10 främsta utsläpparna (200–2022)
- Filtrera och kartlägga utsläpp efter region
- Beräkna och utföra en graf över tillväxten av andelen förnybar energi
- punktdiagram: Visa effekten av förnybar energi för de främsta utsläpparna
- Modell beräknad global energiförbrukning
Skapa en matris för unika länder
Granska de länder som ingår i datamängden genom att skapa en matris för unika länder. När du skapar en matris visas de entiteter som anges som country.
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
utdata:

Insikt:
Kolumnen country innehåller olika entiteter, inklusive Världen, Höginkomstländer, Asien och USA, som inte alltid är direkt jämförbara. Det kan vara mer användbart att filtrera data efter region.
Diagram över utsläppstrender för de 10 främsta utsläpparna (200–2022)
Låt oss säga att du vill fokusera din undersökning på de 10 länder som har de högsta utsläppen av växthusgaser på 2000-talet. Du kan filtrera data för de år du vill titta på och de tio länder med flest utsläpp och sedan använda plottigt för att skapa ett linjediagram som visar deras utsläpp över tid.
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
utdata:

Insikt:
Utsläppen av växthusgaser ökade från 2000–2022, med undantag för ett fåtal länder där utsläppen var relativt stabila med en liten minskning under den tidsramen.
Filtrera och kartlägga utsläpp efter region
Filtrera bort data efter region och beräkna de totala utsläppen för varje region. Rita sedan data som ett stapeldiagram:
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
utdata:

Insikt:
Asien har de högsta utsläppen av växthusgaser. Oceanien, Sydamerika och Afrika producerar de lägsta utsläppen av växthusgaser.
Beräkna och grafera tillväxt av andelen förnybar energi
Skapa en ny funktion/kolumn som beräknar andelen förnybar energi som ett förhållande mellan den förnybara energiförbrukningen och den primära energiförbrukningen. Rangordna sedan länderna baserat på deras genomsnittliga andel förnybar energi. För de 10 främsta länderna planerar de sin andel förnybar energi över tid:
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
utdata:

Insikt:
Norge och Island är ledande i världen inom förnybar energi, och mer än hälften av deras förbrukning kommer från förnybar energi.
Island och Sverige såg den största ökningen av andelen förnybar energi. Alla länder såg tillfälliga nedgångar och ökningar, vilket visar hur tillväxten av förnybar energi inte nödvändigtvis är linjär. Intressant nog såg Mellanöstern en dipp i början av 2010-talet men studsade tillbaka 2020.
Punktdiagram: Visa effekten av förnybar energi för de främsta utsläpparna
Filtrera data för de 10 största utsläpparna och använd sedan ett punktdiagram för att titta på andelen förnybar energi jämfört med utsläppen av växthusgaser över tid.
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
utdata:

Insikt:
Eftersom ett land använder mer förnybar energi har det också fler utsläpp av växthusgaser, vilket innebär att dess totala energiförbrukning ökar snabbare än den förnybara förbrukningen. Nordamerika är ett undantag eftersom utsläppen av växthusgaser förblev relativt konstanta under årens lopp när dess förnybara andel fortsatte att öka.
Modell för beräknad global energiförbrukning
Aggregera den globala primära energiförbrukningen per år och skapa sedan en modell för autoregressivt integrerat glidande medelvärde (ARIMA) för att beräkna den totala globala energiförbrukningen under de närmaste åren. Rita upp den historiska och prognostiserade energiförbrukningen med hjälp av Matplotlib.
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
utdata:

Insikt:
Den här modellen räknar med att den globala energiförbrukningen kommer att fortsätta att öka.
Exempel på notebook
Använd följande notebook-fil för att utföra stegen i den här artikeln. Anvisningar om hur du importerar en anteckningsbok till en Azure Databricks-arbetsyta finns i Importera en anteckningsbok.
Självstudie: EDA med globala energidata
Nästa steg
Nu när du har utfört en inledande undersökande dataanalys på din datauppsättning kan du prova följande steg:
- Se bilagan i notebook-exempel för ytterligare EDA-visualiseringsexempel.
- Om du stöter på fel när du går igenom den här självstudien kan du prova att använda det inbyggda felsökningsprogrammet för att gå igenom koden. Se Felsökningsanteckningsböcker.
- Dela din anteckningsbok med ditt team så att de kan förstå din analys. Beroende på vilka behörigheter du ger dem kan de hjälpa till att utveckla kod för att främja analysen eller lägga till kommentarer och förslag för ytterligare undersökning.
- När du har slutfört analysen skapar du en notebook-instrumentpanel eller en AI/BI-instrumentpanel med viktiga visualiseringar att dela med intressenter.