Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
gäller för:![]() Azure SQL Database
Azure SQL Database
I den här artikeln får du lära dig hur du konfigurerar en redundansgrupp för enkla databaser och pooldatabaser i Azure SQL Database med hjälp av Azure-portalen, Azure PowerShell och Azure CLI.
För skript från slutpunkt till slutpunkt läser du hur du lägger till en enskild databas i en redundansgrupp med Azure PowerShell eller Azure CLI.
Förutsättningar
Tänk på följande förutsättningar för att skapa redundansgruppen för en enskild databas:
- Din primära databas bör redan ha skapats. Skapa en enkel databas för att komma igång.
- Om den sekundära servern redan finns i en annan region än den primära servern måste inställningarna för serverinloggning och brandvägg matcha den för den primära servern.
Skapa redundansgrupp
Du kan skapa redundansgruppen och lägga till en enskild databas i den med hjälp av Azure-portalen, PowerShell och Azure CLI.
Viktigt!
Om du behöver ta bort en sekundär databas när den har lagts till i en redundansgrupp tar du bort den från redundansgruppen innan du tar bort databasen. Om du tar bort en sekundär databas innan den tas bort från redundansgruppen kan det orsaka oförutsägbart beteende.
Följ dessa steg för att skapa redundansgruppen och lägga till en enskild databas i den med hjälp av Azure-portalen:
Om du känner till den logiska server som är värd för din databas går du direkt till den i Azure-portalen. Följ dessa steg om du behöver hitta servern:
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
Azure SQLsedan i sökrutan. (Valfritt) Välj stjärnan bredvid Azure SQL för att favoritmarka den och lägg till den som ett objekt på tjänstmenyn. - På sidan Azure SQL letar du reda på den databas som du vill lägga till i en redundansgrupp och väljer den för att öppna fönstret SQL-databas .
- I fönstret Översikt iSQL-databasen väljer du namnet på servern under Servernamn för att öppna FÖNSTRET SQL-server .
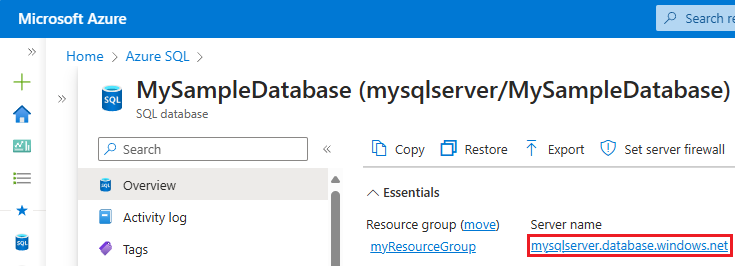
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
På resursmenyn för SQL Server väljer du Redundansgrupper under Datahantering. Välj + Lägg till grupp för att öppna sidan Redundansgrupp där du kan skapa en ny redundansgrupp.

På sidan Redundansgrupp :
- Ange ett namn på redundansklustergruppen.
- Välj en befintlig sekundär server eller skapa en ny server genom att välja Skapa ny under Server. Den sekundära servern i redundansgruppen måste finnas i en annan region än den primära servern.
- Välj Konfigurera databas för att öppna sidan Databaser för redundansgrupper .

På sidan Databaser för redundansgrupper :
- Välj de databaser som du vill lägga till i redundansgruppen (#1 i skärmbild).
- (Valfritt) Välj Ja om du tänker ange dessa databaser som väntelägesrepliker som endast ska användas för haveriberedskap (#2 i skärmbild). Markera kryssrutan för att bekräfta att du använder repliken i vänteläge.
- Använd Välj för att spara databasvalet och gå tillbaka till sidan Redundansgrupp (visas inte på skärmbilden).

Använd Skapa på sidan Redundansgrupp för att skapa redundansgruppen.
Testa planerad omkoppling
Testa redundans för redundansgruppen utan dataförlust med hjälp av Azure-portalen eller PowerShell.
Följ dessa steg för att testa redundans för redundansgruppen med hjälp av Azure-portalen:
Om du känner till den logiska server som är värd för din databas går du direkt till den i Azure-portalen. Följ dessa steg om du behöver hitta servern:
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
Azure SQLsedan i sökrutan. (Valfritt) Välj stjärnan bredvid Azure SQL för att favoritmarka den och lägg till den som ett objekt på tjänstmenyn. - På sidan Azure SQL letar du reda på databasen som du vill testa redundans för och väljer den för att öppna fönstret SQL-databas .
- I fönstret Översikt iSQL-databasen väljer du namnet på servern under Servernamn för att öppna FÖNSTRET SQL-server .
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
På resursmenyn för SQL Server väljer du Redundansgrupper under Datahantering och väljer sedan en befintlig redundansgrupp för att öppna sidan Redundansgrupp .

På sidan Redundansgrupp :
- Granska vilken server som är primär och vilken server som är sekundär.
- Välj Redundans i kommandofältet för att redundansväxla redundansgruppen som innehåller databasen.
- Välj Ja på varningen som meddelar dig att TDS-sessioner kommer att kopplas från.

Granska vilken server som nu är primär och vilken server som är sekundär. När redundansväxlingen lyckas byter de två servrarna roller så att den tidigare primära blir den sekundära.
(Valfritt) Välj Redundans igen för att återställa servrarna till sina ursprungliga roller.
För skript från slutpunkt till slutpunkt läser du hur du lägger till en elastisk pool i en redundansgrupp med Azure PowerShell eller Azure CLI.
Förutsättningar
Överväg följande förutsättningar för att skapa redundansgruppen för en pooldatabas:
- Din primära elastiska pool bör redan finnas. Skapa elastisk pool för att komma igång.
- Om den sekundära servern redan finns måste inställningarna för serverinloggning och brandvägg matcha den primära serverns.
Skapa redundansgrupp
Skapa redundansgruppen för din elastiska pool med hjälp av Azure-portalen, PowerShell eller Azure CLI.
Viktigt!
Om du behöver ta bort en sekundär databas efter att den har lagts till i en redundansgrupp tar du bort den från redundansgruppen innan du tar bort databasen. Om du tar bort en sekundär databas innan den tas bort från redundansgruppen kan det orsaka oförutsägbart beteende.
Följ dessa steg för att skapa redundansgruppen och lägga till den elastiska poolen i den med hjälp av Azure-portalen:
Gå till sidan Skapa elastisk SQL-pool i Azure-portalen. Skapa en elastisk pool som:
- Har samma namn som den elastiska poolen på den primära servern.
- Använder en sekundär server som du tänker använda för redundansgruppen. Den sekundära servern måste finnas i en annan region än den primära servern, och inställningarna för serverinloggning och brandvägg måste matcha den primära serverns inställningar. Skapa en ny server om den sekundära servern inte redan finns.
Om du känner till den logiska server som är värd för din primära elastiska pool går du direkt till den i Azure-portalen. Följ dessa steg om du behöver hitta servern:
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
Azure SQLsedan i sökrutan. (Valfritt) Välj stjärnan bredvid Azure SQL för att favoritmarka den och lägg till den som ett objekt på tjänstmenyn. - På sidan Azure SQL letar du reda på den elastiska pool som du vill lägga till i redundansgruppen och väljer den för att öppna fönstret för elastisk SQL-pool .
- I fönstret Översikt överden elastiska SQL-poolen väljer du namnet på servern under Servernamn för att öppna FÖNSTRET SQL-server .

- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
På resursmenyn för SQL Server väljer du Redundansgrupper under Datahantering. Välj + Lägg till grupp för att öppna sidan Redundansgrupp där du kan skapa en ny redundansgrupp.

På sidan Redundansgrupp :
- Ange ett namn på redundansklustergruppen.
- Välj en befintlig sekundär server. Den sekundära servern i redundansgruppen måste finnas i en annan region än den primära servern och innehålla en elastisk pool med samma namn som den primära servern.
- Välj Konfigurera databas för att öppna sidan Databaser för redundansgrupper .

På sidan Databaser för redundansgrupp väljer du de pooldatabaser som du vill lägga till i redundansgruppen. Använd Välj för att spara databasvalet och gå tillbaka till sidan Redundansgrupp .

Välj Skapa på sidan Redundansgrupp för att skapa redundansgruppen. När du lägger till den elastiska poolen i redundansgruppen startas automatiskt geo-replikeringsprocessen.
Testa planerad omkoppling
Testa redundansväxling av din elastiska pool utan dataförlust med hjälp av Azure-portalen, PowerShell eller Azure CLI.
Redundansväxla redundansgruppen till den sekundära servern och redundansväxla sedan med Hjälp av Azure-portalen.
Om du känner till den logiska server som är värd för din primära elastiska pool går du direkt till den i Azure-portalen. Följ dessa steg om du behöver hitta servern:
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
Azure SQLsedan i sökrutan. (Valfritt) Välj stjärnan bredvid Azure SQL för att favoritmarka den och lägg till den som ett objekt på tjänstmenyn. - På sidan Azure SQL letar du reda på den elastiska pool som du vill lägga till i redundansgruppen och väljer den för att öppna fönstret för elastisk SQL-pool .
- I fönstret Översikt överden elastiska SQL-poolen väljer du namnet på servern under Servernamn för att öppna FÖNSTRET SQL-server .
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
På resursmenyn för SQL Server väljer du Redundansgrupper under Datahantering och väljer sedan en befintlig redundansgrupp för att öppna sidan Redundansgrupp .
På sidan Redundansgrupp :
- Granska vilken server som är primär och vilken server som är sekundär.
- Välj Redundans i kommandofältet för att redundansväxla redundansgruppen som innehåller databasen.
- Välj Ja på varningen som meddelar dig att TDS-sessioner kommer att kopplas från.
Granska vilken server som nu är primär och vilken server som är sekundär. När redundansväxlingen lyckas byter de två servrarna roller så att den tidigare primära blir den sekundära.
(Valfritt) Välj Redundans igen för att återställa servrarna till sina ursprungliga roller.
Ändra befintlig redundansgrupp
Du kan lägga till eller ta bort databaser från en befintlig redundansgrupp eller redigera konfigurationsinställningar för redundansgrupper med hjälp av Azure-portalen, PowerShell och Azure CLI.
Följ dessa steg för att göra ändringar i en befintlig redundansgrupp med hjälp av Azure-portalen:
Om du känner till den logiska server som är värd för din databas eller elastiska pool går du direkt till den i Azure-portalen. Följ dessa steg om du behöver hitta servern:
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
Azure SQLsedan i sökrutan. (Valfritt) Välj stjärnan bredvid Azure SQL för att favoritmarka den och lägg till den som ett objekt på tjänstmenyn. - På sidan Azure SQL letar du reda på den databas eller elastiska pool som du vill ändra och väljer den för att öppna fönstret SQL-databas eller elastisk SQL-pool .
- I fönstret Översikt för SQL-databas eller elastisk SQL-pool väljer du namnet på servern under Servernamn för att öppna FÖNSTRET SQL-server .
- Välj Azure SQL på tjänstmenyn. Om Azure SQL inte finns i listan väljer du Alla tjänster och skriver
På resursmenyn för SQL Server väljer du Redundansgrupper under Datahantering och väljer sedan en befintlig redundansgrupp för att öppna sidan Redundansgrupp .
På sidan Redundansgrupp använder du kommandofältet:
- Om du vill lägga till en databas väljer du Lägg till databaser för att öppna fönstret Lägg till databaser i redundansgrupp och expanderar sedan #Databases för att visa listan över databaser på den primära servern. Markera kryssrutan bredvid de databaser som du vill lägga till i redundansgruppen och använd sedan Välj för att spara dina ändringar och lägga till dina databaser.
- Om du vill ta bort en databas väljer du Ta bort databaser för att öppna fönstret Ta bort databaser från redundansgrupper och expanderar sedan #Databases för att visa databaserna i redundansgruppen. Markera kryssrutan bredvid de databaser som du vill ta bort från redundansgruppen och använd sedan Välj för att spara ändringarna och ta bort dina databaser.
- Om du vill redigera redundanspolicyn eller konfigurera en respitperiod väljer du Redigera konfiguration för att öppna fönstret Redigera konfigurationer redundansgrupper och ändra inställningarna. Använd Välj för att spara ändringarna.

Använda Private Link
Med en privat länk kan du associera en logisk server med en specifik privat IP-adress i det virtuella nätverket och undernätet.
Om du vill använda en privat länk med redundansgruppen gör du följande:
- Kontrollera att dina primära och sekundära servrar finns i en parkopplad region.
- Skapa det virtuella nätverket och undernätet i varje region som värd för privata slutpunkter för primära och sekundära servrar så att de inte har ip-adressutrymmen som inte överlappar varandra. Till exempel överlappar adressintervallet 10.0.0.0/16 för det primära virtuella nätverket och adressintervallet 10.0.0.1/16 för det sekundära virtuella nätverket . Mer information om adressintervall för virtuella nätverk finns i bloggen om att designa virtuella Azure-nätverk.
- Skapa en privat slutpunkt och en Azure Privat DNS-zon för den primära servern.
- Skapa även en privat slutpunkt för den sekundära servern, men den här gången väljer du att återanvända samma privata DNS-zon som för den primära servern.
- När den privata länken har upprättats kan du skapa redundansgruppen genom att följa stegen som beskrevs tidigare i den här artikeln.
Leta upp lyssnarens slutpunkt
När redundansgruppen har konfigurerats uppdaterar du anslutningssträngen för ditt program så att den pekar på läs-/skrivlyssningsslutpunkten så att programmet fortsätter att ansluta till den databas som är primär efter redundansväxlingen. Genom att använda lyssnarens slutpunkt behöver du inte uppdatera anslutningssträngen manuellt varje gång din failover-grupp växlar över eftersom trafiken alltid dirigeras till den aktuella primära servern. Du kan också rikta skrivskyddade arbetsbelastningar till slutpunkten för skrivskyddade lyssnaren.
Om du vill hitta lyssnarslutpunkten i Azure-portalen går du till den logiska servern i Azure-portalen och väljer Redundansgrupper under Datahantering. Välj den redundansgrupp som du är intresserad av.
Bläddra nedåt för att hitta lyssnarens endpunkter.
- Läs -/ skrivlyssningsslutpunkten dirigerar trafik till den primära databasen i form av
fog-name.database.windows.net. - Slutpunkten skrivskyddad lyssnare dirigerar trafik till den sekundära databasen i form av
fog-name.secondary.database.windows.net.

Skala databaser i en redundansgrupp
Du kan skala upp eller ned den primära databasen till en annan beräkningsstorlek (inom samma tjänstnivå) utan att koppla från några geo-sekundärfiler. När du skalar upp rekommenderar vi att du skalar upp den geo-sekundära först och sedan skalar upp den primära. När du skalar ned ändrar du ordningen: skala ned den primära först och skala sedan ned den sekundära. När du skalar en databas till en annan tjänstnivå tillämpas den här rekommendationen.
Den här sekvensen rekommenderas specifikt för att undvika problemet där den geo-sekundära vid en lägre SKU överbelastas och måste återställas under en uppgraderings- eller nedgraderingsprocess. Du kan också undvika problemet genom att göra den primära skrivskyddad på bekostnad av att påverka alla skrivskyddade arbetsbelastningar mot den primära.
Anmärkning
Om du har skapat en geo-sekundär som en del av konfigurationen av en redundansgrupp, rekommenderar vi inte att du skalar ned den geo-sekundära. Detta säkerställer att datanivån har tillräckligt med kapacitet för att bearbeta din normala arbetsbelastning efter en geo-redundansväxling. Du kanske inte kan skala en geo-sekundär efter en oplanerad redundansväxling när den tidigare geo-primära inte är tillgänglig på grund av avbrott. Det här är en känd begränsning.
Den primära databasen i en redundansgrupp kan inte skalas till en högre tjänstnivå (utgåva) om inte den sekundära databasen först skalas till den högre nivån. Om du till exempel vill skala upp den primära från Generell användning till Affärskritisk måste du först skala den geo-sekundära till Affärskritisk. Om du försöker skala den primära eller geo-sekundära på ett sätt som bryter mot den här regeln får du följande fel:
The source database 'Primaryserver.DBName' cannot have higher edition than the target database 'Secondaryserver.DBName'. Upgrade the edition on the target before upgrading the source.
Förhindra förlust av kritiska data
På grund av den långa svarstiden för nätverk i stora områden använder geo-replikering en asynkron replikeringsmekanism. Asynkron replikering gör risken för dataförlust oundviklig om den primära replikeringen misslyckas. För att skydda kritiska transaktioner mot dataförlust kan en programutvecklare anropa den sp_wait_for_database_copy_sync lagrade proceduren omedelbart efter att transaktionen har genomförts. Ett anrop till sp_wait_for_database_copy_sync blockerar den anropande tråden tills den senaste committerade transaktionen har överförts och härdats i den sekundära databasens transaktionslogg. Det väntar dock inte på att de överförda transaktionerna ska spelas upp igen (upprepas) på den sekundära servern.
sp_wait_for_database_copy_sync är begränsad till en specifik geo-replikeringslänk. Alla användare med anslutningsrättigheter till den primära databasen kan anropa den här proceduren.
Anmärkning
sp_wait_for_database_copy_sync förhindrar dataförlust efter geo-omstart för specifika transaktioner, men garanterar inte full synkronisering för läsaccess. Fördröjningen som orsakas av ett sp_wait_for_database_copy_sync proceduranrop kan vara betydande och beror på storleken på den ännu inte överförda transaktionsloggen på den primära vid tidpunkten för anropet.
Ändra den sekundära regionen
För att illustrera ändringssekvensen förutsätter vi att server A är den primära servern, att server B är den befintliga sekundära servern och att server C är den nya sekundära i den tredje regionen. Gör övergången genom att följa dessa steg:
- Skapa ytterligare sekundärfiler för varje databas på server A till server C med aktiv geo-replikering. Varje databas på server A har två sekundärfiler, en på server B och en på server C. Detta garanterar att de primära databaserna förblir skyddade under övergången.
- Ta bort redundansgruppen. Nu börjar inloggningsförsök med slutpunkter för redundansgrupper att misslyckas.
- Återskapa redundansgruppen med samma namn mellan servrarna A och C.
- Lägg till alla primära databaser på server A i den nya redundansgruppen. Nu slutar inloggningsförsöken att misslyckas.
- Ta bort server B. Alla databaser på B tas bort automatiskt.
Ändra den primära regionen
För att illustrera ändringssekvensen antar vi att server A är den primära servern, server B är den befintliga sekundära servern och att server C är den nya primära i den tredje regionen. Gör övergången genom att följa dessa steg:
- Utför en planerad geo-redundansväxling för att växla den primära servern till B. Server A blir den nya sekundära servern. Redundansväxlingen kan resultera i flera minuters stilleståndstid. Den faktiska tiden beror på storleken på redundansgruppen.
- Skapa ytterligare sekundärfiler för varje databas på server B till server C med aktiv geo-replikering. Varje databas på server B har två sekundärfiler, en på server A och en på server C. Detta garanterar att de primära databaserna förblir skyddade under övergången.
- Ta bort redundansgruppen. Nu börjar inloggningsförsök med slutpunkter för redundansgrupper att misslyckas.
- Återskapa redundansgruppen med samma namn mellan servrarna B och C.
- Lägg till alla primära databaser på B i den nya redundansgruppen. Nu slutar inloggningsförsöken att misslyckas.
- Utför en planerad geo-redundansväxling för redundansgruppen för att växla B och C. Nu blir server C den primära och B den sekundära. Alla sekundära databaser på server A länkas automatiskt till primärvalen på C. Precis som i steg 1 kan redundansväxlingen resultera i flera minuters stilleståndstid.
- Ta bort server A. Alla databaser på A tas bort automatiskt.
Viktigt!
När redundansgruppen tas bort tas även DNS-posterna för lyssnarens slutpunkter bort. Då är sannolikheten inte noll att någon annan skapar en redundansgrupp eller ett DNS-alias för servern med samma namn. Eftersom namn på redundanskluster och DNS-alias måste vara globalt unika hindrar detta dig från att använda samma namn igen. För att minimera den här risken, använd inte generiska namn för failover-grupper.
Redundansgrupper och nätverkssäkerhet
För vissa program kräver säkerhetsreglerna att nätverksåtkomsten till datanivån är begränsad till en specifik komponent eller komponenter som en virtuell dator, webbtjänst osv. Det här kravet innebär vissa utmaningar för affärskontinuitetsdesign och användning av redundansgrupper. Överväg följande alternativ när du implementerar sådan begränsad åtkomst.
Använda redundansgrupper och tjänstslutpunkter för virtuella nätverk
Om du använder tjänstslutpunkter och regler för virtuellt nätverk för att begränsa åtkomsten till databasen bör du vara medveten om att varje tjänstslutpunkt för virtuellt nätverk endast gäller för en Azure-region. Slutpunkten gör det inte möjligt för andra regioner att acceptera kommunikation från undernätet. Därför kan endast klientprogram som distribueras i samma region ansluta till den primära databasen. Eftersom en geo-redundans resulterar i att SQL Database-klientsessionerna omdirigeras till en server i en annan (sekundär) region, kan dessa sessioner misslyckas om de kommer från en klient utanför den regionen. Därför kan inte Microsofts hanterade redundansprincip aktiveras om de deltagande servrarna ingår i reglerna för virtuellt nätverk. Följ dessa steg för att stödja manuell redundansprincip:
- Etablera redundanta kopior av klientdelskomponenterna i ditt program (webbtjänst, virtuella datorer osv.) i den sekundära regionen.
- Konfigurera regler för virtuella nätverk individuellt för den primära och sekundära servern.
- Aktivera redundansväxling i klientdelen med hjälp av en Traffic Manager-konfiguration.
- Initiera en manuell geo-redundans när avbrottet identifieras. Det här alternativet är optimerat för program som kräver konsekvent svarstid mellan klientdelen och datanivån och stöder återställning när antingen klientdelen, datanivån eller båda påverkas av driftstoppet.
Anmärkning
Om du använder den skrivskyddade lyssnaren för att belastningsutjämning en skrivskyddad arbetsbelastning ska du kontrollera att den här arbetsbelastningen körs på en virtuell dator eller någon annan resurs i den sekundära regionen så att den kan ansluta till den sekundära databasen.
Använda redundansgrupper och brandväggsregler
Om din affärskontinuitetsplan kräver redundans med hjälp av redundansgrupper kan du begränsa åtkomsten till din SQL Database med hjälp av offentliga IP-brandväggsregler. Den här konfigurationen säkerställer att en geo-redundans inte blockerar anslutningar från klientdelskomponenter och förutsätter att programmet kan tolerera längre svarstider mellan klientdelen och datanivån.
Följ dessa steg för att stödja redundansväxling av redundansgrupper:
- Skapa en offentlig IP-adress.
- Skapa en offentlig lastbalanserare och tilldela den offentliga IP-adressen till den.
- Skapa ett virtuellt nätverk och de virtuella datorerna för dina klientdelskomponenter .
- Skapa en nätverkssäkerhetsgrupp och konfigurera inkommande anslutningar.
- Kontrollera att de utgående anslutningarna är öppna för Azure SQL Database i en region med hjälp av en
Sql.<Region>tjänsttagg. - Skapa en SQL Database-brandväggsregel för att tillåta inkommande trafik från den offentliga IP-adress som du skapar i steg 1.
Mer information om hur du konfigurerar utgående åtkomst och vilken IP-adress som ska användas i brandväggsreglerna finns i Utgående anslutningar för lastbalanserare.
Viktigt!
För att garantera affärskontinuitet vid regionala avbrott måste du säkerställa geografisk redundans för både klientdelskomponenter och databaser.
Behörigheter
Behörigheter för en redundansgrupp hanteras via rollbaserad åtkomstkontroll i Azure (Azure RBAC).
Skrivåtkomst för Azure RBAC krävs för att skapa och hantera redundansgrupper. ROLLEN SQL Server-deltagare har alla behörigheter som krävs för att hantera redundansgrupper.
I följande tabell visas specifika behörighetsomfång för Azure SQL Database:
| Åtgärd | Tillåtelse | Omfattning |
|---|---|---|
| Skapa redundansgrupp | Skrivåtkomst för Azure RBAC | Primär server Sekundär server Alla databaser i redundansgruppen |
| Uppdatera redundansgrupp | Skrivåtkomst för Azure RBAC | Failover-kluster Alla databaser på den aktuella primära servern |
| Redundansväxlingsgrupp | Skrivåtkomst för Azure RBAC | Redundansgrupp på ny server |
Begränsningar
Tänk på följande begränsningar:
- Failover-grupper kan bara skapas mellan logiska servrar i samma Microsoft Entra-klientorganisation.
- Redundansgrupper kan inte skapas mellan två servrar i samma Azure-region.
- Redundansgrupper stöder geo-replikering av alla databaser i gruppen till endast en sekundär logisk server i en annan region.
- Det går inte att byta namn på redundansgrupper. Du måste ta bort gruppen och återskapa den med ett annat namn.
- Databasbyte stöds inte för databaser i en redundansgrupp. Du måste tillfälligt ta bort redundansgruppen för att kunna byta namn på en databas eller ta bort databasen från redundansgruppen.
- Replikeringen stoppas inte om du tar bort en redundansgrupp för en enskild eller en grupperad databas, och inte heller tas den replikerade databasen bort. Du måste stoppa geo-replikering manuellt och ta bort databasen från den sekundära servern om du vill lägga till en enkel databas eller en pooldatabas tillbaka till en redundansgrupp när den har tagits bort. Om du inte gör något av detta kan det leda till
The operation cannot be performed due to multiple errorsett fel som liknar när du försöker lägga till databasen i redundansgruppen. - Namn på redundansgrupper omfattas av namngivningsbegränsningar.
- När du skapar en ny redundansgrupp, eller när du lägger till databaser i en befintlig redundansgrupp, kan du bara ange databaserna som väntelägesreplikernär du använder Azure-portalen – Azure PowerShell och Azure CLI är inte tillgängliga för närvarande.
- Azure-portalen har inte stöd för att skapa redundansgrupper i olika prenumerationer. Använd i stället PowerShell-cmdletar för att programmatiskt hantera redundansgrupper.
Hantera redundansgrupper programmatiskt
Redundansgrupper kan också hanteras programmatiskt med hjälp av Azure PowerShell, Azure CLI och REST API. I följande tabeller beskrivs vilken uppsättning kommandon som är tillgängliga. Redundansgrupper innehåller en uppsättning Azure Resource Manager-API:er för hantering, inklusive Azure SQL Database REST API och Azure PowerShell-cmdletar. Dessa API:er kräver användning av resursgrupper och stöder rollbaserad åtkomstkontroll i Azure (Azure RBAC). Mer information om hur du implementerar åtkomstroller finns i Rollbaserad åtkomstkontroll i Azure (Azure RBAC).
| Cmdlet (ett PowerShell-kommando) | Beskrivning |
|---|---|
| New-AzSqlDatabaseFailoverGroup | Det här kommandot skapar en redundansgrupp och registrerar den på både primära och sekundära servrar |
| Add-AzSqlDatabaseToFailoverGroup | Lägger till en eller flera databaser i en redundansgrupp |
| Remove-AzSqlDatabaseFromFailoverGroup | Tar bort en eller flera databaser från en redundansgrupp |
| Remove-AzSqlDatabaseFailoverGroup | Tar bort en redundansgrupp från servern |
| Get-AzSqlDatabaseFailoverGroup | Hämtar konfigurationen för en redundansgrupp |
| Set-AzSqlDatabaseFailoverGroup | Ändrar konfigurationen av en redundansgrupp |
| Switch-AzSqlDatabaseFailoverGroup | "Utlöser en failover av en Failover-grupp till den sekundära servern" |
Anmärkning
Det går att distribuera redundansgruppen mellan prenumerationer med hjälp av parametern -PartnerSubscriptionId i Azure Powershell som börjar med Az.SQL 3.11.0. Mer information finns i följande exempel.