Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Dit artikel bevat oplossingen voor problemen met betrekking tot het verzenden van logboeken.
Wat is wachtrij voor het verzenden van logboeken?
Wijzigingen die worden aangebracht in een database van een beschikbaarheidsgroep op de primaire replica (zoals INSERT, UPDATEen DELETE) worden naar het transactielogboek geschreven en naar de secundaire replica's van de beschikbaarheidsgroep verzonden. De wachtrij voor het verzenden van logboeken definieert het aantal logboekrecords in de logboekbestanden van de primaire database die niet naar de secundaire replica's zijn verzonden.
Symptomen en effect van het verzenden van logboeken
Wachtrij voor het verzenden van logboeken slaat alle kwetsbare gegevens op
Als de primaire replica in een plotseling noodgeval verloren gaat en u een failover uitvoert naar de secundaire replica waar deze wijzigingen nog niet zijn aangekomen, worden deze wijzigingen niet weergegeven in de nieuwe kopie van de primaire replica van de database. Dit sluit eventuele wijzigingen uit die worden opgeslagen wanneer volledige database- en logboekback-ups worden uitgevoerd.
Groeiende logboeken verzenden wachtrij veroorzaakt groeiende groei van transactielogboekbestand
Voor een database die is gedefinieerd in een beschikbaarheidsgroep, moet Microsoft SQL Server op de primaire replica alle transacties in het transactielogboek bewaren die nog niet aan de secundaire replica's zijn geleverd. De wachtrij voor het verzenden van logboeken vertegenwoordigt de hoeveelheid vastgelegde wijzigingen op de primaire replica die niet kan worden afgekapt tijdens normale logboekafkappingsgebeurtenissen (bijvoorbeeld tijdens een back-up van een databaselogboek). Een grote en groeiende wachtrij voor het verzenden van logboeken kan vrije ruimte vrijmaken op het station dat als host fungeert voor het databaselogboekbestand of kan de geconfigureerde maximale grootte van het transactielogboekbestand overschrijden. Zie Fout 9002 wanneer het transactielogboek groot is voor meer informatie.
Verschillende diagnostische functies rapporteren het verzenden van wachtrijen voor beschikbaarheidsgroepen
Het AlwaysOn-dashboard in de SQL Server Management Studio-rapporten over het verzenden van logboeken. Het kan melden dat de beschikbaarheidsgroep niet in orde is.
Controleren op wachtrijen voor het verzenden van logboeken
De wachtrij voor het verzenden van logboeken is een meting per database. U kunt deze waarde controleren met behulp van het AlwaysOn-dashboard op de primaire replica of met behulp van de sys.dm_hadr_database_replica_states Dynamische beheerweergaven (DMV) op de primaire of secundaire replica. Prestatiemeteritems worden gebruikt om te controleren op wachtrijen voor het verzenden van logboeken op de secundaire replica.
De volgende secties bieden methoden voor het actief bewaken van de wachtrij voor het verzenden van het databaselogboek van de beschikbaarheidsgroep.
Query's uitvoeren op sys.dm_hadr_database_replica_state
De sys.dm_hadr_database_replica_states DMV rapporteert een rij voor elke database met beschikbaarheidsgroepen. Eén kolom in dat rapport is log_send_queue_size. Deze waarde is de grootte van de wachtrij voor het verzenden van logboeken in kilobytes (KB). U kunt een query zoals de volgende query instellen om elke trend in de wachtrijgrootte voor het verzenden van logboeken te bewaken. De query wordt uitgevoerd op de primaire replica. Hierbij wordt het is_local=0 predicaat gebruikt om de gegevens voor de secundaire replica te rapporteren, indien log_send_queue_size en log_send_rate relevant zijn.
WHILE 1=1
BEGIN
SELECT drcs.database_name, ars.role_desc, drs.log_send_queue_size, drs.log_send_rate,
ars.recovery_health_desc, ars.connected_state_desc, ars.operational_state_desc, ars.synchronization_health_desc, *
FROM sys.dm_hadr_availability_replica_states ars JOIN sys.dm_hadr_database_replica_cluster_states drcs ON ars.replica_id=drcs.replica_id
JOIN sys.dm_hadr_database_replica_states drs ON drcs.group_database_id=drs.group_database_id
WHERE ars.role_desc='SECONDARY' AND drs.is_local=0
waitfor delay '00:00:30'
END
Hier ziet u hoe de uitvoer eruitziet.

De wachtrij voor het verzenden van logboeken controleren in alwayson-dashboard
Voer de volgende stappen uit om de wachtrij voor het verzenden van logboeken te controleren:
Open het AlwaysOn-dashboard in SQL Server Management Studio (SSMS) door met de rechtermuisknop te klikken op een beschikbaarheidsgroep in SSMS Objectverkenner.
Selecteer Dashboard weergeven.
De databases van de beschikbaarheidsgroep worden als laatste weergegeven en er zijn enkele gegevens die zijn gerapporteerd in de databases. Hoewel de grootte van de logboekwachtrij (KB) en de frequentie voor het verzenden van logboeken (KB/sec) niet standaard worden vermeld, kunt u deze toevoegen aan deze weergave, zoals wordt weergegeven in de schermafbeelding in de volgende stap.
Als u deze kolommen wilt toevoegen, klikt u met de rechtermuisknop op de kolomkop van de beschikbaarheidsgroep en selecteert u deze in de lijst met beschikbare kolommen.
Als u de wachtrijgrootte voor logboekverzending wilt toevoegen, klikt u met de rechtermuisknop op de koptekst die rood wordt weergegeven in de volgende schermopname.
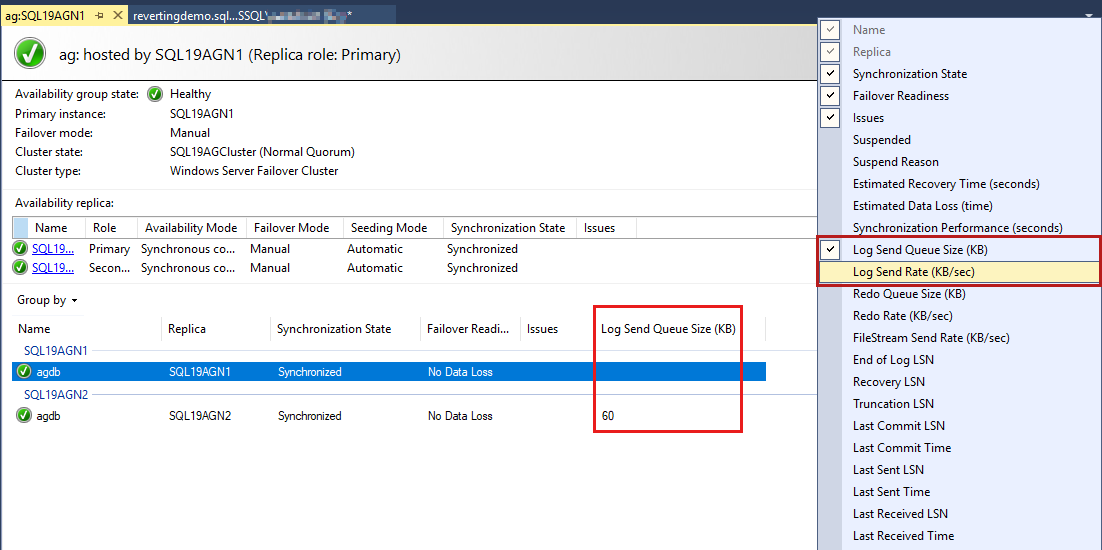
Standaard worden deze gegevens in het AlwaysOn-dashboard elke 60 seconden automatisch vernieuwd.



Controleer de logboekwachtrij in de prestatiemeter
De wachtrij voor het verzenden van logboeken is specifiek voor elke secundaire replicadatabase. Voer daarom de volgende stappen uit om de wachtrij voor het verzenden van logboeken van een beschikbaarheidsgroepdatabase te controleren:
Open Prestatiemeter op de secundaire replica.
Selecteer de knop Toevoegen (teller).
Selecteer onder Beschikbare tellers de tellers SQLServer:Database Replica en Logboek verzenden wachtrijen.
Selecteer in de keuzelijst Exemplaar de database van de beschikbaarheidsgroep die u wilt controleren op wachtrijen voor het verzenden van logboeken.
Selecteer Toevoegen en OK.
Hier ziet u hoe toenemende wachtrijen voor het verzenden van logboeken eruit kunnen zien.


Wachtrijwaarden voor het verzenden van logboeken interpreteren
In deze sectie wordt uitgelegd hoe u de waarden van de grootte van de wachtrij voor het verzenden van logboeken interpreteert.
Wanneer is het verzenden van logboeken in de wachtrij slecht? Hoeveel wachtrijen voor logboekverzending moeten worden getolereerd?
U kunt ervan uitgaan dat als de wachtrij voor het verzenden van logboeken een waarde van 0 rapporteert, dit betekent dat er geen wachtrij voor logboekverzending plaatsvindt op het moment van dat rapport. Wanneer uw productieomgeving echter bezet is, moet u verwachten dat de wachtrij voor het verzenden van logboeken vaak een andere waarde dan nul rapporteert, zelfs in een gezonde AlwaysOn-omgeving. Tijdens een typische productie moet u verwachten dat deze waarde fluctueert tussen 0 en een niet-nulwaarde.
Als u ziet dat de wachtrij voor het verzenden van logboeken na verloop van tijd toeneemt, is verder onderzoek gerechtvaardigd. Deze extra activiteit geeft aan dat er iets is veranderd. Als u een plotselinge groei in de wachtrij voor het verzenden van logboeken ziet, zijn de volgende metingen handig voor het oplossen van problemen:
- Verzendsnelheid voor logboeken (KB/sec) (AlwaysOn-dashboard)
- sys.dm_hadr_database_replica_states (DMV)
- Databasereplica::Gespiegelde transacties per seconde (prestatiemeter)
Basislijntarieven ophalen voor verzendsnelheid voor logboeken en gespiegelde transacties per seconde
Controleer tijdens de goede AlwaysOn-prestaties de frequentie van het verzenden van logboeken en gespiegelde transacties per seconde voor uw beschikbaarheidsgroepdatabases. Hoe zien ze eruit tijdens meestal drukke kantooruren? Hoe zien ze eruit tijdens perioden van onderhoud, wanneer grote transacties hogere transactiedoorvoer op het systeem stimuleren? U kunt deze waarden vergelijken wanneer u de groei van logboekwachtrijen bekijkt om te bepalen wat er is gewijzigd. De workload is mogelijk groter dan normaal. Als de frequentie voor het verzenden van logboeken lager is dan normaal, is mogelijk nader onderzoek vereist om te bepalen waarom.
Workloadvolumes zijn belangrijk
Wanneer u grote werkbelastingen (zoals een UPDATE instructie ten opzichte van 1 miljoen rijen, een index opnieuw opbouwt op een tabel van 1 terabyte of zelfs een ETL-batch die miljoenen rijen invoegt), moet u verwachten dat er direct of na verloop van tijd een toename van de wachtrij voor logboeken wordt verzonden. Dit wordt verwacht wanneer er plotseling een groot aantal wijzigingen wordt aangebracht in de database van de beschikbaarheidsgroep.
Logboekverzending diagnosticeren
Nadat u logboekverzending voor een specifieke beschikbaarheidsgroepdatabase hebt geïdentificeerd, moet u controleren op verschillende mogelijke hoofdoorzaken van het probleem, zoals beschreven in de volgende secties.
Belangrijk
Voor zinvolle uitvoer van wachttypen controleert u op een toename in de wachtrij voor het verzenden van logboeken met behulp van een van de methoden die in de vorige secties worden beschreven wanneer u de volgende voorwaarden bewaakt.
Het systeem is te druk
Controleer of de werkbelasting op de primaire replica de CPU's van het systeem overbelast. Als u een toename ziet in de wachtrij voor het verzenden van logboeken, voert u een query uit op de sys.dm_os_schedulers DMV en controleert u op high runnable_tasks_count. Dit aantal geeft openstaande taken aan die op dat moment zijn uitgevoerd.
SELECT scheduler_address, scheduler_id, cpu_id, status, current_tasks_count, runnable_tasks_count, current_workers_count, active_workers_count
FROM sys.dm_os_schedulers
De volgende tabel is een voorbeeld van de resultaten. Een toename van de runnable_tasks_count waarde geeft aan dat een groot aantal taken wacht op CPU-tijd.
| scheduler_address | scheduler_id | cpu_id | status | current_tasks_count | runnable_tasks_count | current_workers_count | active_workers_count |
|---|---|---|---|---|---|---|---|
| 0x000002778D 200040 | 0 | 0 | ZICHTBAAR OFFLINE | 1 | 0 | 2 | 1 |
| 0x000002778D 220040 | 1 | 1 | ZICHTBAAR ONLINE | 108 | 12 | 115 | 107 |
| 0x000002778D 240040 | 2 | 2 | ZICHTBAAR ONLINE | 113 | 2 | 123 | 113 |
| 0x000002778D 260040 | 3 | 3 | ZICHTBAAR ONLINE | 105 | 11 | 116 | 105 |
| 0x000002778D 480040 | 4 | 4 | ZICHTBAAR ONLINE | 108 | 15 | 117 | 108 |
| 0x000002778D 4A0040 | 5 | 5 | ZICHTBAAR ONLINE | 100 | 25 | 110 | 99 |
| 0x000002778D 4C0040 | 6 | 6 | ZICHTBAAR ONLINE | 105 | 23 | 113 | 105 |
| 0x000002778D 4E0040 | 7 | 7 | ZICHTBAAR | 109 | 25 | 116 | 109 |
| 0x000002778D 700040 | 8 | 8 | ZICHTBAAR ONLINE | 98 | 10 | 112 | 98 |
| 0x000002778D 720040 | 9 | 9 | ZICHTBAAR ONLINE | 114 | 1 | 130 | 114 |
| 0x000002778D 740040 | 10 | 10 | ZICHTBAAR ONLINE | 110 | 25 | 120 | 110 |
| 0x000002778D 760040 | 11 | 11 | ZICHTBAAR ONLINE | 83 | 8 | 93 | 83 |
| 0x000002778D A00040 | 12 | 12 | ZICHTBAAR ONLINE | 104 | 4 | 117 | 104 |
| 0x000002778D A20040 | 13 | 13 | ZICHTBAAR ONLINE | 108 | 32 | 118 | 108 |
| 0x000002778D A40040 | 14 | 14 | ZICHTBAAR ONLINE | 102 | 12 | 113 | 102 |
| 0x000002778D A60040 | 15 | 15 | ZICHTBAAR ONLINE | 104 | 16 | 116 | 103 |
Oplossing: Als u hoog runnable_task_countdetecteert, vermindert u de werkbelasting op het systeem of verhoogt u het aantal CPU's dat beschikbaar is voor het systeem.
Netwerklatentie
Deze voorwaarde is vooral gebruikelijk als de secundaire replica fysiek extern is van de primaire replica. Met beschikbaarheidsgroepen voor meerdere sites kunnen klanten kopieën van bedrijfsgegevens implementeren op meerdere sites voor herstel na noodgevallen en rapportage. Hierdoor zijn vrijwel realtime wijzigingen beschikbaar voor de kopieën van de productiegegevens op externe locaties.
Als een secundaire replica ver van de primaire replica wordt gehost, kan het verzenden van logboekwachtrijen worden veroorzaakt door netwerklatentie en een onvermogen om wijzigingen naar de externe secundaire zo snel mogelijk te verzenden als ze worden geproduceerd in de primaire replicadatabase.
Belangrijk
SQL Server maakt gebruik van één verbinding om wijzigingen van de primaire naar de secundaire replica's te synchroniseren. Als een secundaire replica extern is, heeft de breedte van de pijp dus geen invloed op de hoeveelheid gegevens die SQL Server kan verzenden. In plaats daarvan is deze hoeveelheid afhankelijker van de netwerklatentie in de pijp (verbindingssnelheid).
Testen op netwerklatentie
Controleren of instellingen voor stroombeheer bijdragen aan netwerklatentie
Microsoft SQL Server-beschikbaarheidsgroepen gebruiken stroombeheerpoorten om overmatig verbruik van netwerkresources, geheugen en andere resources op alle beschikbaarheidsreplica's te voorkomen. Deze poorten voor stroombeheer hebben geen invloed op de synchronisatiestatus van de beschikbaarheidsreplica's. Ze kunnen echter van invloed zijn op de algehele prestaties van uw beschikbaarheidsdatabases, waaronder RPO.
In latere versies van SQL Server worden de drempelwaarden gewijzigd waarop stroombeheer wordt ingevoerd. Dit kan helpen het effect te verlichten dat stroombeheer heeft op symptomen zoals het verzenden van logboeken. Zie Stroombesturingspoorten voor meer informatie over stroombeheer en de geschiedenis van wijzigingen in drempels voor stroombeheer.
U kunt controleren op stroombeheer met performance monitor om gegevens op de primaire replica vast te leggen. Als u het beheer van de databasestroom wilt bewaken, voegt u SQLServer:DatabaseReplicameteritems toe en selecteert u de databasestroomvertraging en databasestroombesturingselementen per seconde. Selecteer in het dialoogvenster Exemplaar de beschikbaarheidsgroepdatabase die u wilt controleren op databasestroombeheer. Als u controle over de beschikbaarheidsreplicastroom wilt detecteren en bewaken, voegt u SQLServer:Availability Replica-tellers toe en selecteert u de stroombesturingstijd (ms/sec) en stroombeheer per seconde.
Controleren of congestie windows opnieuw opstarten bijdraagt aan netwerklatentie
Netwerkprestatieproblemen die ertoe leiden dat wachtrijen voor logboekverzending worden veroorzaakt, kunnen worden geactiveerd door de TCP-instelling Voor het opnieuw opstarten van Windows opnieuw opstarten op Waar in te stellen. Dit was de standaardinstelling in Windows Server 2016. Zorg ervoor dat congestievenster opnieuw opstarten is ingesteld op Onwaar op Windows-servers waarop replica's van beschikbaarheidsgroepen worden gehost waarop wachtrijen voor het verzenden van logboeken worden waargenomen.
PS C:\WINDOWS\system32> Get-NetTCPSetting | Select SettingName, CwndRestart
Zie Set-NetTCPSetting (NetTCPIP) voor meer informatie over het instellen van de eigenschap TCP Congestion Windows Restart op False.
Zie Ook De prestaties bewaken voor AlwaysOn-beschikbaarheidsgroepen voor informatie over het synchronisatieproces. In dit artikel wordt ook beschreven hoe u enkele van de belangrijkste metrische gegevens kunt berekenen en koppelingen vindt naar enkele veelvoorkomende scenario's voor het oplossen van prestatieproblemen.
Ping gebruiken om een latentievoorbeeld op te halen
Ping node2 (secundaire replica) op een opdrachtregel op knooppunt1 (primaire replica):
C:\Users\customer>ping node2 Pinging node2.customer.corp.company.com [<ip address>] with 32 bytes of data: Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=97ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=94ms Reply from 2001:4898:4018:3005:25f3:d931:2507:e353: time=119ms Ping statistics for 2<ip address>: Packets: Sent = 4, Received = 4, Lost = 0 (0% loss), Approximate round trip times in milli-seconds: Minimum = 94ms, Maximum = 119ms, Average = 101msNetwerkdoorvoer testen van primair naar secundair met behulp van onafhankelijk hulpprogramma
Gebruik een hulpprogramma zoals NTttcp om de netwerkdoorvoer tussen de primaire en secundaire replica's onafhankelijk te detecteren met behulp van één verbinding. Netwerklatentie is een veelvoorkomende oorzaak voor het verzenden van logboeken. De volgende stappen laten zien hoe u een onafhankelijk hulpprogramma zoals NTttcp gebruikt om de netwerkdoorvoer te meten.
Belangrijk
SQL Server verzendt wijzigingen van de primaire replica naar de secundaire replica met behulp van één verbinding. In de volgende sectie configureren en voeren we NTttcp uit om één verbinding (op dezelfde manier als SQL Server) te gebruiken om de doorvoer nauwkeurig te vergelijken.
U kunt NTttcp downloaden van Github - microsoft/ntttcp.
Voer de volgende stappen uit om NTttcp uit te voeren:
Download en kopieer het hulpprogramma naar de primaire en secundaire SQL Server-servers.
Open op de secundaire replicaserver een opdrachtpromptvenster met verhoogde bevoegdheid, wijzig de map in de map van het hulpprogramma NTttcp en voer vervolgens de volgende opdracht uit:
ntttcp.exe -r -m 1,0,<secondaryipaddress>-a 16 -t 60Notitie
In deze opdracht
<secondaryipaddress>is een tijdelijke aanduiding voor het werkelijke IP-adres van de secundaire replicaserver.Open op de primaire replicaserver een opdrachtpromptvenster met verhoogde bevoegdheid, wijzig de map in de map van het hulpprogramma NTttcp en voer vervolgens de volgende opdracht uit door opnieuw het werkelijke IP-adres van de secundaire replicaserver op te geven:
ntttcp.exe -s -m 1,0,<secondaryipaddress>-a 16 -t 60In de volgende schermafbeeldingen ziet u dat NTttcp wordt uitgevoerd op de secundaire en primaire replica's. Vanwege netwerklatentie kan het hulpprogramma slechts 739 kB per seconde aan gegevens verzenden. Dat is wat u kunt verwachten dat SQL Server kan verzenden.
NTttcp op secundaire replica

NTttcp op primaire replica

Prestatiemeteritems controleren
Controleer welke NTttcp rapporteert. Een grote transactie wordt uitgevoerd in SQL Server op de primaire replica. Nadat u Prestatiemeter op de primaire replica hebt gestart, voegt u het prestatiemeteritem Network Interface::Bytes Sent/sec toe. Met deze teller wordt bevestigd dat de primaire replica ongeveer 777 KB/sec aan gegevens kan verzenden. Dit is vergelijkbaar met de waarde van 739 kB per seconde die wordt gerapporteerd door de NTttcp-test.

Het is ook handig om de waarde SQL Server::D atabases::Log Bytes Flushed/sec op de primaire replica te vergelijken met SQL Server::D atabase Replica::Log Bytes Received/sec voor dezelfde database op de secundaire replica. Gemiddeld zien we ongeveer 20 MB per seconde aan wijzigingen die zijn gemaakt in de 'agdb'-database. De secundaire replica ontvangt echter gemiddeld slechts 5,4 MB aan wijzigingen. Dit zorgt ervoor dat logboeken wachtrijen verzenden op de primaire replica van openstaande wijzigingen in het databasetransactielogboek die nog niet naar de secundaire replica zijn verzonden.
Primaire replicalogboek bytes leeggemaakt per seconde voor de 'agdb'-database

Secundaire replicalogboekbytes ontvangen per seconde voor de database agdb
