Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL-database in Microsoft Fabric Preview
SQL-database in Microsoft Fabric Preview
Elke SQL Server-database heeft een transactielogboek dat alle transacties en de databasewijzigingen registreert die door elke transactie worden aangebracht. Het transactielogboek is een essentieel onderdeel van de database en als er een systeemfout optreedt, is het transactielogboek mogelijk vereist om uw database weer in een consistente status te brengen. Deze handleiding bevat informatie over de fysieke en logische architectuur van het transactielogboek. Inzicht in de architectuur kan uw effectiviteit verbeteren bij het beheren van transactielogboeken.
Logische architectuur voor transactielogboeken
Het SQL Server-transactielogboek werkt logisch alsof het transactielogboek een reeks logboekrecords is. Elke logboekrecord wordt geïdentificeerd met een logboekreeksnummer (LSN). Elke nieuwe logboekrecord wordt naar het logische einde van het logboek geschreven met een LSN die hoger is dan de LSN van de record ervoor. Logboekrecords worden opgeslagen in een seriële reeks wanneer ze worden gemaakt, zodat als LSN2 groter is dan LSN1, de wijziging die wordt beschreven door de logboekrecord waarnaar wordt verwezen door LSN2, is opgetreden na de wijziging die wordt beschreven door de logboekrecord LSN1. Elke logboekrecord bevat de id van de transactie waartoe deze behoort. Voor elke transactie worden alle logboekrecords die aan de transactie zijn gekoppeld afzonderlijk gekoppeld in een keten met behulp van achterwaartse aanwijzers die het terugdraaien van de transactie versnellen.
De basisstructuur van een LSN is [VLF ID:Log Block ID:Log Record ID]. Zie de secties VLF en logboekblokken voor meer informatie.
Hier volgt een voorbeeld van een LSN: 00000031:00000da0:0001waar 0x31 is de id van de VLF, 0xda0 de logboekblok-id en 0x1 de eerste logboekrecord in dat logboekblok. Bekijk de uitvoer van sys.dm_db_log_info DMV en bekijk de vlf_create_lsn kolom voor voorbeelden van LSN's.
Logboekrecords voor gegevenswijzigingen registreren de logische bewerking die is uitgevoerd, of ze registreren de voor- en na afbeeldingen van de gewijzigde gegevens. De voorafbeelding is een kopie van de gegevens voordat de bewerking wordt uitgevoerd; de volgende afbeelding is een kopie van de gegevens nadat de bewerking is uitgevoerd.
De stappen voor het herstellen van een bewerking zijn afhankelijk van het type logboekrecord:
Logische bewerking geregistreerd
- Als u de logische bewerking wilt doorsturen, wordt de bewerking opnieuw uitgevoerd.
- Als u de logische bewerking wilt terugdraaien, wordt de omgekeerde logische bewerking uitgevoerd.
Vóór en na afbeelding vastgelegd
- Als u de bewerking wilt doorsturen, wordt de afbeelding nadat deze is toegepast.
- Om de bewerking terug te draaien, wordt de voor-afbeelding toegepast.
Veel soorten bewerkingen worden vastgelegd in het transactielogboek. Deze bewerkingen omvatten:
Het begin en einde van elke transactie.
Elke wijziging van gegevens (invoegen, bijwerken of verwijderen). Wijzigingen omvatten wijzigingen door DDL-instructies (System Stored Procedures of Data Definition Language) voor elke tabel, inclusief systeemtabellen.
Elk bereik en elke paginatoewijzing of deallocatie.
Een tabel of index maken of verwijderen.
Terugdraaibewerkingen worden ook vastgelegd. Elke transactie reserveert ruimte in het transactielogboek om ervoor te zorgen dat er voldoende logboekruimte bestaat ter ondersteuning van een terugdraaiactie die wordt veroorzaakt door een expliciete terugdraaiinstructie of als er een fout optreedt. De hoeveelheid gereserveerde ruimte is afhankelijk van de bewerkingen die in de transactie worden uitgevoerd, maar over het algemeen is deze gelijk aan de hoeveelheid ruimte die wordt gebruikt om elke bewerking te registreren. Deze gereserveerde ruimte wordt vrijgemaakt wanneer de transactie is voltooid.
De sectie van het logboekbestand uit de eerste logboekrecord die aanwezig moet zijn voor een geslaagde terugdraaiactie van de database naar de laatst geschreven logboekrecord, wordt het actieve deel van het logboek, het actieve logboek of de staart van het logboek genoemd. Dit is de sectie van het logboek dat is vereist voor een volledig herstel van de database. Er kan nooit een deel van het actieve logboek worden afgekapt. Het logboekreeksnummer (LSN) van deze eerste logboekrecord wordt de minimale herstel-LSN (MinLSN ) genoemd. Zie het transactielogboek voor meer informatie over bewerkingen die worden ondersteund door het transactielogboek.
Differentiële en logback-ups brengen de herstelde database naar een later tijdstip, wat overeenkomt met een hogere LSN.
Fysieke architectuur van transactielogboek
Het transactielogboek van de database wordt in kaart gebracht over een of meer fysieke bestanden. Conceptueel is het logbestand een reeks logboekrecords. Fysiek wordt de reeks logboekrecords efficiënt opgeslagen in de set fysieke bestanden die het transactielogboek implementeren. Er moet ten minste één logboekbestand voor elke database zijn.
Virtuele logboekbestanden (VLF's)
De SQL Server Database Engine verdeelt elk fysiek logboekbestand intern in verschillende virtuele logboekbestanden (VLF's). Virtuele logboekbestanden hebben geen vaste grootte en er is geen vast aantal virtuele logboekbestanden voor een fysiek logboekbestand. De database-engine kiest de grootte van de virtuele logboekbestanden dynamisch tijdens het maken of uitbreiden van logboekbestanden. De database-engine probeert een aantal virtuele bestanden te onderhouden. De grootte van de virtuele bestanden nadat een logboekbestand is uitgebreid, is de som van de grootte van het bestaande logboek en de grootte van de nieuwe bestandsverhoging. De grootte of het aantal virtuele logboekbestanden kan niet worden geconfigureerd of ingesteld door beheerders.
Virtueel logboekbestand maken
Het maken van een virtueel logboekbestand (VLF) volgt deze methode:
- Als in SQL Server 2014 (12.x) en latere versies de volgende groei kleiner is dan 1/8 van de huidige fysieke logboekgrootte, maakt u vervolgens 1 VLF die de groeigrootte omvat.
- Als de volgende groei groter is dan 1/8 van de huidige logboekgrootte, gebruikt u de methode vóór 2014, namelijk:
- Als de groei kleiner is dan 64 MB, maakt u 4 VLF's die de groeigrootte dekken (bijvoorbeeld voor groei van 1 MB, maakt u 4 VLF's van grootte 256 kB).
- In Azure SQL Database en te beginnen met SQL Server 2022 (16.x) (alle edities), is de logica iets anders. Als de groei kleiner is dan of gelijk is aan 64 MB, maakt de database-engine slechts één VLF om de groeigrootte te dekken.
- Als de groei van 64 MB tot 1 GB is, maakt u 8 VLF's die de groeigrootte dekken (bijvoorbeeld voor groei van 512 MB, maakt u 8 VLF's van grootte 64 MB).
- Als de groei groter is dan 1 GB, maakt u 16 VLF's die de groeigrootte dekken, bijvoorbeeld voor groei van 8 GB, 16 VLF's van grootte 512 MB maken).
- Als de groei kleiner is dan 64 MB, maakt u 4 VLF's die de groeigrootte dekken (bijvoorbeeld voor groei van 1 MB, maakt u 4 VLF's van grootte 256 kB).
Als de logboekbestanden in veel kleine stappen groter worden, eindigen ze met veel virtuele logboekbestanden. Dit kan het opstarten van de database vertragen, het maken en terugzetten van logback-ups bemoeilijken, en leiden tot latentieproblemen bij transactionele replicatie, CDC en Always On heruitvoering. Als de logboekbestanden daarentegen op grote grootte zijn ingesteld met slechts een paar of één enkele toename, bevatten ze weinig maar zeer grote virtuele logboekbestanden. Zie de sectie Aanbevelingen van Het beheren van de grootte van het transactielogboek voor meer informatie over het correct schatten van de vereiste grootte en de instelling voor automatische groei van een transactielogboek.
U wordt aangeraden uw logboekbestanden dicht bij de uiteindelijke vereiste grootte te maken, met behulp van de stappen die nodig zijn om een optimale VLF-verdeling te bereiken en een relatief grote growth_increment waarde te hebben.
Zie de volgende tips om de optimale VLF-distributie te bepalen voor de huidige grootte van het transactielogboek:
- De groottewaarde, ingesteld door het
SIZE-argument vanALTER DATABASE, is de oorspronkelijke grootte voor het logbestand. - De growth_increment waarde (ook wel de waarde voor automatisch groeien genoemd), wat het
FILEGROWTHargument vanALTER DATABASEsets is, is de hoeveelheid ruimte die aan het bestand wordt toegevoegd telkens wanneer er nieuwe ruimte nodig is.
Zie FILEGROWTH voor meer informatie over SIZE en ALTER DATABASE argumenten van.
Tip
Als u de optimale VLF-distributie wilt bepalen voor de huidige transactielogboekgrootte van alle databases in een bepaald exemplaar en de vereiste groeiverhogingen om de vereiste grootte te bereiken, raadpleegt u dit Fixing-VLFs script op GitHub.
Wat gebeurt er wanneer u te veel VLF's hebt?
Tijdens de eerste fasen van een databaseherstelproces detecteert SQL Server alle VLF's in alle transactielogboekbestanden en bouwt een lijst met deze VLF's. Dit proces kan lang duren, afhankelijk van het aantal VLF's dat aanwezig is in de specifieke database. Hoe meer VLF's, hoe langer het proces. Een database kan eindigen met een groot aantal VLF's als frequente automatische groei van transactielogboeken of handmatige groei wordt aangetroffen in kleine stappen. Wanneer het aantal VLF's het bereik van enkele honderdduizenden bereikt, kunt u enkele of de meeste van de volgende symptomen tegenkomen:
- Een of meer databases duren erg lang om het herstel te voltooien tijdens het opstarten van SQL Server.
- Het herstellen van een database duurt erg lang.
- Het koppelen van een database duurt erg lang.
- Wanneer u databasespiegeling probeert in te stellen, worden foutberichten 1413, 1443 en 1479 weergegeven, die een time-out aangeven.
- Er treden geheugengerelateerde fouten op, zoals 701 wanneer u probeert een database te herstellen.
- Transactionele replicatie of gegevensopname wijzigen kan aanzienlijke latentie ervaren.
Wanneer u het sql Server-foutenlogboek bekijkt, ziet u mogelijk dat er een aanzienlijke hoeveelheid tijd wordt besteed voordat de analysefase van het databaseherstelproces wordt uitgevoerd. Voorbeeld:
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
Daarnaast kan SQL Server een MSSQLSERVER_9017-fout registreren wanneer u een database met een groot aantal VLF's herstelt:
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
Zie MSSQLSERVER_9017 voor meer informatie.
Databases optimaliseren met een groot aantal VLF's
Als u het totale aantal VLF's op een redelijk bedrag wilt houden, zoals een maximum van enkele duizenden, kunt u het transactielogboekbestand opnieuw instellen op een kleiner aantal VLF's door de volgende stappen uit te voeren:
Verklein de transactielogboekbestanden handmatig.
Breid de bestanden in één stap handmatig uit tot de vereiste grootte met behulp van het volgende T-SQL-script:
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Note
Deze stap is ook mogelijk in SQL Server Management Studio, met behulp van de pagina database-eigenschappen.
Nadat u de nieuwe indeling van het transactielogboekbestand met minder VLF's hebt ingesteld, controleert en wijzigt u de instellingen voor automatisch vergroten van het transactielogboek. Deze instellingsvalidatie zorgt ervoor dat het logboekbestand in de toekomst hetzelfde probleem vermijdt.
Voordat u een van deze bewerkingen uitvoert, moet u ervoor zorgen dat u een geldige herstelbare back-up hebt voor het geval u later problemen ondervindt.
Als u de optimale VLF-distributie wilt bepalen voor de huidige grootte van het transactielogboek van alle databases in een bepaald exemplaar en de vereiste groeiverhogingen om de vereiste grootte te bereiken, kunt u het volgende GitHub-script gebruiken om VLF's te herstellen.
Logboekblokken
Elke VLF bevat een of meer logboekblokken. Elk logboekblok bestaat uit de logboekrecords (uitgelijnd op een grens van 4 bytes). Een logboekblok heeft een variabele grootte en is altijd een geheel getal van 512 bytes (de minimale sectorgrootte die SQL Server ondersteunt), met een maximale grootte van 60 kB. Een logboekblok is de basiseenheid van I/O voor transactielogboekregistratie.
Kortom, een logboekblok is een container met logboekrecords die worden gebruikt als de basiseenheid voor transactielogboekregistratie bij het schrijven van logboekrecords naar schijf.
Elk logboekblok in een VLF wordt uniek geadresseerd door de blokverrekening. Het eerste blok heeft altijd een blokverschil dat voorbij de eerste 8 kB in de VLF wijst.
Over het algemeen is een VLF altijd gevuld met logblokken. Het is mogelijk dat het laatste logboekblok in een VLF leeg is (bijvoorbeeld geen logboekrecords bevat). Dit gebeurt wanneer een logboekrecord die moet worden geschreven niet in het huidige logboekblok past en ook wanneer de ruimte die op de VLF overblijft onvoldoende is om deze logboekrecord op te slaan. In dit geval wordt een leeg logblok gemaakt dat de VLF vult. De logboekinvoer wordt ingevoegd in het eerste blok in de volgende VLF.
Cirkelvormige aard van het transactielogboek
Het transactielogboek is een wrap-around-bestand. Denk bijvoorbeeld aan een database met één fysiek logboekbestand dat is onderverdeeld in vier VLF's. Wanneer de database wordt gemaakt, begint het logische logboekbestand aan het begin van het fysieke logboekbestand. Nieuwe logboekrecords worden toegevoegd aan het einde van het logische logboek en worden uitgebreid naar het einde van het fysieke logboek. Bij logboektruncatie worden alle virtuele logboeken vrijgemaakt waarvan alle records zich vóór het minimale herstel-logvolgnummer (MinLSN) bevinden. De MinLSN is het logboekvolgordenummer van de oudste logboekrecord die is vereist voor een geslaagde terugdraaiactie voor de hele database. Het transactielogboek in de voorbeelddatabase ziet er ongeveer als volgt uit in het volgende diagram.
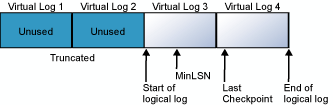
Wanneer het einde van het logische logboek het einde van het fysieke logboekbestand bereikt, draaien de nieuwe logboekrecords terug naar het begin van het fysieke logboekbestand.

Deze cyclus herhaalt eindeloos, zolang het einde van het logische logboek nooit het begin van het logische logboek bereikt. Als de oude logboekrecords vaak genoeg worden afgekapt om altijd voldoende ruimte te laten voor alle nieuwe logboekrecords die zijn gemaakt via het volgende controlepunt, wordt het logboek nooit ingevuld. Als het einde van het logische logboek echter het begin van het logische logboek bereikt, gebeurt er een van de volgende twee dingen:
Als de
FILEGROWTHinstelling is ingeschakeld voor het logboek en de ruimte beschikbaar is op de schijf, wordt het bestand uitgebreid met de hoeveelheid die is opgegeven in de parameter growth_increment en worden de nieuwe logboekrecords toegevoegd aan de extensie. ZieFILEGROWTHvoor meer informatie over de instelling.Als de
FILEGROWTHinstelling niet is ingeschakeld of de schijf met het logboekbestand minder vrije ruimte heeft dan de hoeveelheid die is opgegeven in growth_increment, wordt er een 9002-fout gegenereerd. Zie Problemen met een volledig transactielogboek oplossen (SQL Server-fout 9002) voor meer informatie.
Als het logboek meerdere fysieke logboekbestanden bevat, wordt het logische logboek door alle fysieke logboekbestanden verplaatst voordat het weer terugloopt naar het begin van het eerste fysieke logboekbestand.
Important
Afkapping van logboeken
Het inkorten of trunceren van logbestanden is essentieel om te voorkomen dat het logbestand vol raakt. Logboekafkapping verwijdert inactieve virtuele logboekbestanden uit het logische transactielogboek van een SQL Server-database, waardoor ruimte vrijkomt in het logische logboek voor hergebruik door het fysieke transactielogboek. Als een transactielogboek nooit wordt afgekapt, vult het uiteindelijk alle schijfruimte die is toegewezen aan de fysieke logboekbestanden. Voordat het log echter kan worden afgekapt, moet er een controlepuntoperatie worden uitgevoerd. Een controlepunt schrijft de huidige gewijzigde pagina's in het geheugen (ook wel vervuilde pagina's genoemd) en transactielogboekgegevens van het geheugen naar de schijf. Wanneer het controlepunt wordt uitgevoerd, wordt het inactieve gedeelte van het transactielogboek gemarkeerd als herbruikbaar. Daarna kan een afkapping van het logboek het inactieve gedeelte vrij maken. Zie Database-controlepunten (SQL Server) voor meer informatie over controlepunten.
In de volgende diagrammen ziet u een transactielogboek voor en na truncatie. In het eerste diagram ziet u een transactielogboek dat nog nooit is afgekapt. Op dit moment worden vier virtuele logboekbestanden gebruikt door het logische logboek. Het logische logboek begint aan de voorzijde van het eerste virtuele logboekbestand en eindigt op virtueel logboek 4. De MinLSN-record bevindt zich in virtueel logboek 3. Virtueel logboek 1 en virtueel logboek 2 bevatten alleen inactieve logboekrecords. Deze records kunnen worden ingekort. Virtueel logboek 5 is nog steeds ongebruikt en maakt geen deel uit van het huidige logische logboek.

In het tweede diagram ziet u hoe het logboek wordt weergegeven nadat het is afgekapt. Virtueel logboek 1 en virtueel logboek 2 zijn gratis voor hergebruik. Het logische logboek begint nu aan het begin van het virtuele logboek 3. Virtueel logboek 5 is nog steeds ongebruikt en maakt geen deel uit van het huidige logische logboek.
Logboektruncatie vindt automatisch plaats na de volgende gebeurtenissen, behalve wanneer het om welke reden dan ook wordt vertraagd.
- In het eenvoudige herstelmodel, na een controlepunt.
- Onder het volledige herstelmodel of het bulksgewijs vastgelegde herstelmodel, na een logboekback-up, als er een controlepunt is opgetreden sinds de vorige back-up.
Afkapping van logbestanden kan worden vertraagd door verschillende factoren. In het geval van een lange vertraging bij het afkappen van logboeken kan het transactielogboek vol raken. Zie voor meer informatie Factoren die het afkappen van logboeken kunnen vertragen en Een vol transactielog oplossen (SQL Server-fout 9002).
Write-ahead transactielogboek
In deze sectie wordt de rol beschreven van het transactielogboek voor write-ahead bij het vastleggen van gegevenswijzigingen op schijf. SQL Server maakt gebruik van een WAL-algoritme (Write-Ahead Logging) dat garandeert dat er geen gegevenswijzigingen naar de schijf worden geschreven voordat de bijbehorende logboekrecord naar de schijf wordt geschreven. Dit behoudt de ACID-eigenschappen van een transactie.
Zie DE basisprincipes van SQL Server I/O voor meer informatie over WAL.
Als u wilt weten hoe write-ahead-logboekregistratie werkt ten opzichte van het transactielogboek, is het belangrijk dat u weet hoe gewijzigde gegevens naar de schijf worden geschreven. SQL Server onderhoudt een buffercache (ook wel een buffergroep genoemd) waarin gegevenspagina's worden gelezen wanneer gegevens moeten worden opgehaald. Wanneer een pagina wordt gewijzigd in de buffercache, wordt deze niet onmiddellijk teruggeschreven naar de schijf; In plaats daarvan wordt de pagina gemarkeerd als vuil. Een gegevenspagina kan meer dan één logische schrijfbewerking hebben gemaakt voordat deze fysiek naar de schijf wordt geschreven. Voor elke logische schrijfbewerking wordt een transactielogboekrecord ingevoegd in de logboekcache waarin de wijziging wordt vastgelegd. De logboekrecords moeten naar schijf worden geschreven voordat de bijbehorende vuile pagina wordt verwijderd uit de buffercache en naar schijf wordt geschreven. Het controlepuntproces scant periodiek de buffercache op buffers met pagina's uit een opgegeven database en schrijft alle vuile pagina's naar schijf. Controlepunten besparen tijd tijdens een later herstel door een punt te maken waarop alle vuile pagina's gegarandeerd naar de schijf zijn geschreven.
Het schrijven van een gewijzigde gegevenspagina van de buffercache naar schijf wordt het leegmaken van de pagina genoemd. SQL Server heeft logica waarmee wordt voorkomen dat een vuile pagina wordt leeggemaakt voordat de bijbehorende logboekrecord wordt geschreven. Logboekrecords worden naar schijf geschreven wanneer de logboekbuffers worden leeggemaakt. Dit gebeurt wanneer een transactie wordt doorgevoerd of wanneer de logboekbuffers vol raken.
Back-ups van transactielogboeken
In deze sectie vindt u concepten over het maken van back-ups en het herstellen (toepassen) van transactielogboeken. Onder de volledige en bulksgewijs vastgelegde herstelmodellen is het maken van routineback-ups van transactielogboeken (logboekback-ups) nodig voor het herstellen van gegevens. U kunt een back-up van het logboek maken terwijl er een volledige back-up wordt uitgevoerd. Zie Back-up en herstel van SQL Server-databases voor meer informatie over herstelmodellen.
Voordat u de eerste logboekback-up kunt maken, moet u een volledige back-up maken, zoals een databaseback-up of de eerste in een set bestandsback-ups. Het herstellen van een database met behulp van alleen bestandsback-ups kan complex worden. Daarom raden we u aan om te beginnen met een volledige databaseback-up wanneer u dat kunt. Daarna is regelmatig een back-up van het transactielogboek nodig. Dit minimaliseert niet alleen de blootstelling aan werkverlies, maar maakt ook het afkappen van het transactielogboek mogelijk. Normaal gesproken wordt het transactielogboek ingekort na elke reguliere logboekback-up.
Als u het aantal logboekback-ups wilt beperken dat u moet herstellen, is het essentieel om regelmatig een back-up van uw gegevens te maken. U kunt bijvoorbeeld een wekelijkse volledige databaseback-up en dagelijkse differentiële databaseback-ups plannen.
Denk na over de vereiste RTO en RPO bij het implementeren van uw herstelstrategie, met name het volledige en differentiële back-upritme van de database.
Zie Back-ups van transactielogboeken (SQL Server) voor meer informatie over back-ups van transactielogboeken.
Back-upfrequentie en bedrijfsvereisten
U moet regelmatig genoeg logboekback-ups maken ter ondersteuning van uw bedrijfsvereisten, met name uw tolerantie voor werkverlies, zoals mogelijk veroorzaakt door een beschadigde logboekopslag.
De juiste frequentie voor het maken van logboekback-ups is afhankelijk van uw tolerantie voor blootstelling aan werkverlies in balans met het aantal logboekback-ups dat u kunt opslaan, beheren en, mogelijk, herstellen. Denk na over de vereiste beoogde hersteltijd (RTO) en RPO (Recovery Point Objective) bij het implementeren van uw herstelstrategie, en met name de frequentie van de logboekback-up.
Het maken van een logboekback-up kan elke 15 tot 30 minuten voldoende zijn. Als uw bedrijf vereist dat u blootstelling aan werkverlies minimaliseert, kunt u overwegen om vaker logboekback-ups te maken. Frequentere logboekback-ups hebben het extra voordeel van het verhogen van de frequentie van afkapping van logboeken, wat resulteert in kleinere logboekbestanden.
De logboekketen
Een doorlopende reeks logboekback-ups wordt een logboekketen genoemd. Een logboekketen begint met een volledige back-up van de database. Normaal gesproken wordt er alleen een nieuwe logboekketen gestart wanneer er voor het eerst een back-up van de database wordt gemaakt of nadat het herstelmodel is overgeschakeld van eenvoudig herstel naar volledig of bulksgewijs vastgelegd herstel. Tenzij u ervoor kiest om bestaande back-upsets te overschrijven bij het maken van een volledige databaseback-up, blijft de bestaande logboekketen intact. Als de logboekketen intact is, kunt u uw database herstellen vanuit elke volledige databaseback-up in de mediaset, gevolgd door alle volgende logboekback-ups via uw herstelpunt. Het herstelpunt kan het einde zijn van de laatste logboekback-up of een specifiek herstelpunt in een van de logboekback-ups. Zie Back-ups van transactielogboeken (SQL Server) voor meer informatie.
Als u een database tot het storingspunt wilt herstellen, moet de logboekketen intact zijn. Dat wil gezegd dat een niet-verbroken reeks back-ups van transactielogboeken moet worden uitgebreid tot het foutpunt. Waar deze reeks logboeken moet worden gestart, is afhankelijk van het type gegevensback-ups dat u herstelt: database, gedeeltelijk of bestand. Voor een database of gedeeltelijke back-up moet de reeks logboekback-ups worden uitgebreid vanaf het einde van een database of gedeeltelijke back-up. Voor een set bestandsback-ups moet de volgorde van logboekback-ups doorgaan vanaf het begin van een volledige set bestandsback-ups. Zie Back-ups van transactielogboeken (SQL Server) toepassenvoor meer informatie.
Logboekback-ups herstellen
Als u een logboekback-up herstelt, worden de wijzigingen die zijn vastgelegd in het transactielogboek doorgestuurd om de exacte status van de database opnieuw te maken op het moment dat de back-upbewerking van het logboek is gestart. Wanneer u een database herstelt, moet u de logboekback-ups herstellen die zijn gemaakt na de volledige databaseback-up die u herstelt, of vanaf het begin van de eerste bestandsback-up die u herstelt. Nadat u de meest recente gegevens of differentiële back-up hebt hersteld, moet u meestal een reeks logboekback-ups herstellen totdat u het herstelpunt bereikt. Vervolgens herstelt u de database. Hiermee worden alle transacties teruggedraaid die onvolledig waren toen het herstel werd gestart en de database online worden gebracht. Nadat de database is hersteld, kunt u geen back-ups meer herstellen. Zie Back-ups van transactielogboeken (SQL Server) toepassenvoor meer informatie.
Controlepunten en het actieve gedeelte van het logboek
Controlepunten leegmaken vuile gegevenspagina's uit de buffercache van de huidige database naar schijf. Dit minimaliseert het actieve gedeelte van het logboek dat moet worden verwerkt tijdens een volledig herstel van een database. Tijdens een volledig herstel worden de volgende typen acties uitgevoerd:
- De logboekrecords van wijzigingen die niet naar schijf zijn leeggemaakt voordat het systeem is gestopt, worden doorgestuurd.
- Alle wijzigingen die zijn gekoppeld aan onvolledige transacties, zoals transacties waarvoor geen
COMMITofROLLBACKlogboekrecord is, worden teruggedraaid.
Controlepuntbewerking
Een controlepunt voert de volgende processen uit in de database:
Hiermee schrijft u een record naar het logboekbestand, waarmee het begin van het controlepunt wordt gemarkeerd.
Slaat informatie op die is vastgelegd voor het controlepunt in een keten van controlepuntlogboekrecords.
Eén informatie die is vastgelegd in het controlepunt, is het logboekreeksnummer (LSN) van de eerste logboekrecord die aanwezig moet zijn voor een geslaagde terugdraaiactie voor de hele database. Deze LSN wordt de Minimum Recovery LSN (MinLSN) genoemd. De MinLSN is het minimum van de volgende:
- LSN van het begin van het controlepunt.
- Het begin-LSN van de oudste actieve transactie.
- LSN van het begin van de oudste replicatietransactie die nog niet is geleverd aan de distributiedatabase.
De controlepuntrecords bevatten ook een lijst met alle actieve transacties die de database hebben gewijzigd.
Als de database gebruikmaakt van het eenvoudige herstelmodel, markeert u de ruimte die aan de MinLSN voorafgaat voor hergebruik.
Schrijft alle vuile logboek- en gegevenspagina's naar schijf.
Hiermee schrijft u een record die het einde van het controlepunt aan het logboekbestand markeert.
Hiermee schrijft u de LSN van het begin van deze keten naar de opstartpagina van de database.
Activiteiten die een controlepunt veroorzaken
Controlepunten vinden plaats in de volgende situaties:
Er wordt expliciet een
CHECKPOINTinstructie uitgevoerd. Er vindt een controlepunt plaats in de huidige database voor de verbinding.Er wordt een minimaal vastgelegde bewerking uitgevoerd in de database; Er wordt bijvoorbeeld een bulksgewijze kopieerbewerking uitgevoerd op een database die gebruikmaakt van het Bulk-Logged herstelmodel.
Databasebestanden zijn toegevoegd of verwijderd met behulp van
ALTER DATABASE.Een exemplaar van SQL Server wordt gestopt door een
SHUTDOWNinstructie of door de SQL Server-service (MSSQLSERVER) te stoppen. Een van beide acties veroorzaakt een controlepunt in elke database in het exemplaar van SQL Server.Een exemplaar van SQL Server genereert periodiek automatische controlepunten in elke database om de tijd te verkorten die nodig is om de database te herstellen.
Er wordt een databaseback-up gemaakt.
Er wordt een activiteit uitgevoerd waarvoor een database moet worden afgesloten. Dit kan gebeuren wanneer de
AUTO_CLOSEoptie isONen de laatste gebruikersverbinding met de database is gesloten. Een ander voorbeeld is wanneer een wijziging van de databaseoptie wordt aangebracht waarvoor een herstart van de database is vereist.
Automatische controlepunten
De SQL Server Database Engine genereert automatische controlepunten. Het interval tussen automatische controlepunten is gebaseerd op de hoeveelheid gebruikte logboekruimte en de tijd die is verstreken sinds het laatste controlepunt. Het tijdsinterval tussen automatische controlepunten kan zeer variabel en lang zijn, als er weinig wijzigingen worden aangebracht in de database. Automatische controlepunten kunnen ook vaak optreden als er veel gegevens worden gewijzigd.
Gebruik de configuratieoptie herstelinterval om het interval tussen automatische controlepunten voor alle databases op een serverinstantie te berekenen. Met deze optie geeft u de maximale tijd op die de database-engine moet gebruiken om een database te herstellen tijdens het opnieuw opstarten van het systeem. De database-engine maakt een schatting van het aantal logboekrecords dat tijdens een herstelbewerking kan worden verwerkt in het herstelinterval .
Het interval tussen automatische controlepunten is ook afhankelijk van het herstelmodel:
Als de database gebruikmaakt van het volledige of bulksgewijs vastgelegde herstelmodel, wordt er een automatisch controlepunt gegenereerd wanneer het aantal logboekrecords het nummer bereikt dat de Database Engine schat dat het kan verwerken tijdens de tijd die is opgegeven in de optie herstelinterval.
Als de database gebruikmaakt van het eenvoudige herstelmodel, wordt er een automatisch controlepunt gegenereerd wanneer het aantal logboekrecords de mindere van deze twee waarden bereikt:
- Het logboek wordt 70 procent vol.
- Het aantal logboekrecords bereikt het getal dat de database-engine schat dat het kan verwerken tijdens de tijd die is opgegeven in de optie herstelinterval.
Zie Serverconfiguratie: herstelinterval (min.) voor informatie over het instellen van het herstelinterval.
Tip
Met de -k geavanceerde installatieoptie van SQL Server kan een databasebeheerder het I/O-gedrag van controlepunten beperken op basis van de doorvoer van het I/O-subsysteem voor bepaalde typen controlepunten. De -k instellingsoptie is van toepassing op automatische controlepunten en alle andere niet-beperkte controlepunten.
Met automatische controlepunten wordt de ongebruikte sectie van het transactielogboek afgekapt als de database gebruikmaakt van het eenvoudige herstelmodel. Als de database echter gebruikmaakt van de volledige of bulksgewijs vastgelegde herstelmodellen, wordt het logboek niet afgekapt door automatische controlepunten. Zie Het transactielogboek voor meer informatie.
De CHECKPOINT instructie biedt nu een optioneel checkpoint_duration argument waarmee de aangevraagde periode, in seconden, wordt opgegeven om controlepunten te voltooien. Zie CHECKPOINT voor meer informatie.
Actief logboek
De sectie van het logboekbestand van de MinLSN naar de laatst geschreven logboekrecord wordt het actieve gedeelte van het logboek of het actieve logboek genoemd. Dit is de sectie van het logboek dat nodig is om een volledig herstel van de database uit te voeren. Er kan nooit een deel van het actieve logboek worden afgekapt. Alle logboekrecords moeten worden afgekapt uit de onderdelen van het logboek vóór de MinLSN.
In het volgende diagram ziet u een vereenvoudigde versie van het end-of-a-transaction-logboek met twee actieve transacties. Controlepuntrecords zijn gecomprimeerd tot één record.

LSN 148 is de laatste record in het transactielogboek. Op het moment dat het vastgelegde controlepunt op LSN 147 werd verwerkt, was Tran 1 afgehandeld en was Tran 2 de enige actieve transactie. Dit maakt de eerste logboekrecord voor Tran 2 de oudste logboekrecord voor een transactie actief op het moment van het laatste controlepunt. Dit maakt LSN 142, de begintransactierecord voor Tran 2, tot de MinLSN.
Langlopende transacties
Het actieve logboek moet elk deel van alle niet-doorgevoerde transacties bevatten. Een toepassing die een transactie start en deze niet doorvoert of terugdraait, voorkomt dat de Database Engine naar de MinLSN gaat. Deze situatie kan twee soorten problemen veroorzaken:
- Als het systeem wordt afgesloten nadat de transactie veel niet-doorgevoerde wijzigingen heeft uitgevoerd, kan de herstelfase van de volgende herstart veel langer duren dan de tijd die is opgegeven in de optie herstelinterval .
- Het logboek kan erg groot worden, omdat het logboek niet kan worden afgekapt voorbij de MinLSN. Dit gebeurt zelfs als de database gebruikmaakt van het eenvoudige herstelmodel, waarin het transactielogboek wordt afgekapt op elk automatisch controlepunt.
Herstel van langlopende transacties en de problemen die in dit artikel worden beschreven, kunnen worden vermeden door versneld databaseherstel te gebruiken, een functie die beschikbaar is vanaf SQL Server 2019 (15.x) en in Azure SQL Database.
Replicatietransacties
De logboeklezeragent bewaakt het transactielogboek van elke database die is geconfigureerd voor transactionele replicatie en kopieert de transacties die zijn gemarkeerd voor replicatie vanuit het transactielogboek naar de distributiedatabase. Het actieve logboek moet alle transacties bevatten die zijn gemarkeerd voor replicatie, maar die nog niet aan de distributiedatabase zijn geleverd. Als deze transacties niet tijdig worden gerepliceerd, kunnen ze voorkomen dat het logboek wordt afgekapt. Zie Transactionele replicatie voor meer informatie.
Verwante inhoud
- het transactielogboek
- De grootte van het transactielogboekbestand beheren
- back-ups van transactielogboeken (SQL Server)
- Databasecontrolepunten (SQL Server)
- Serverconfiguratie: herstelinterval (min. )
- Versneld herstel van databases
- sys.dm_db_log_info (Transact-SQL)
- sys.dm_db_log_space_usage (Transact-SQL)
- Informatie over logboekregistratie en herstel in SQL Server