Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
Van toepassing op:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() SQL-database in Microsoft Fabric Preview
SQL-database in Microsoft Fabric Preview
Opties en aanbevelingen voor het laden van gegevens in een columnstore-index met behulp van de standaardmethoden voor bulksgewijs laden en invoegen van SQL. Het laden van gegevens in een columnstore-index is een essentieel onderdeel van een datawarehousingproces omdat deze gegevens naar de index verplaatst ter voorbereiding op analyse.
Nieuw bij columnstore-indexen? Zie Columnstore-indexen - overzicht en Columnstore-indexarchitectuur.
Wat is bulksgewijs laden?
Bulksgewijs laden verwijst naar de manier waarop grote aantallen rijen worden toegevoegd aan een gegevensarchief. Het is de meest krachtige manier om gegevens naar een columnstore-index te verplaatsen, omdat deze werkt op batches rijen. Bulksgewijs laden vult rijgroepen tot maximale capaciteit en comprimeert ze rechtstreeks in de columnstore. Alleen rijen aan het einde van een lading die niet voldoen aan het minimum van 102.400 rijen per rijgroep, gaan naar de deltastore.
Als u bulksgewijs wilt laden, kunt u bcp Utility, Integration Services gebruiken of rijen selecteren in een faseringstabel.
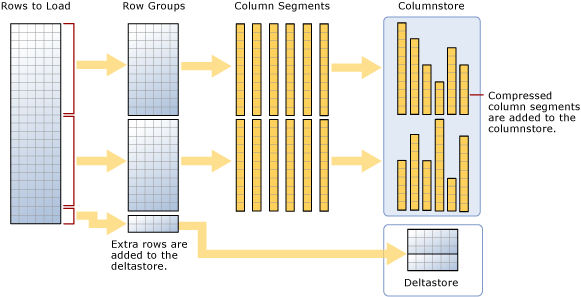
Zoals in het diagram wordt voorgesteld, wordt het volgende bulksgewijs geladen:
- Sorteert de gegevens niet vooraf. Gegevens worden ingevoegd in rijengroepen in de volgorde waarin ze worden ontvangen.
- Als de batchgrootte = 102400 is >, worden de rijen rechtstreeks in de gecomprimeerde rijgroepen geladen. U moet een batchgrootte >=102400 kiezen voor efficiënte bulkimport, omdat u kunt voorkomen dat gegevensrijen worden verplaatst naar deltarijgroepen voordat de rijen uiteindelijk worden verplaatst naar gecomprimeerde rijgroepen door een achtergrondthread, tuple mover (TM).
- Als de batchgrootte < 102.400 of als de resterende rijen < 102.400 zijn, worden de rijen geladen in deltarijgroepen.
Note
In een rijopslagtabel met een niet-geclusterde columnstore-indexgegevens voegt SQL Server altijd gegevens in de basistabel in. De gegevens worden nooit rechtstreeks in de columnstore-index ingevoegd.
Bulksgewijs laden heeft deze ingebouwde prestatieoptimalisaties:
Parallelle verwerkingen: U kunt meerdere parallelle bulkverwerkingen hebben (bcp of bulkinvoer) die elk een afzonderlijk gegevensbestand laden. In tegenstelling tot bulkloads in een rowstore in SQL Server, hoeft u niet op te geven
TABLOCKomdat elke thread voor bulkinvoer gegevens uitsluitend laadt in afzonderlijke rijen groepen (gecomprimeerde of deltarijgroepen) met een exclusieve vergrendeling daarop.Gereduceerde logboekregistratie: De gegevens die rechtstreeks in gecomprimeerde rijgroepen worden geladen, leiden tot een aanzienlijke vermindering van de grootte van het logboek. Als gegevens bijvoorbeeld 10x zijn gecomprimeerd, is het bijbehorende transactielogboek ongeveer 10x kleiner zonder
TABLOCKdat hiervoor een bulksgewijs vastgelegd/eenvoudig herstelmodel nodig is. Alle gegevens die naar een deltarijgroep gaan, worden volledig geregistreerd. Dit geldt ook voor batchgrootten die kleiner zijn dan 102.400 rijen. Best practice is om batchsize >= 102400 te gebruiken. Omdat er geenTABLOCKvereiste is, kunt u de gegevens parallel laden.Minimale logboekregistratie: U kunt de logboekregistratie verder verminderen als u voldoet aan de vereisten voor minimale logboekregistratie. In tegenstelling tot het laden van gegevens in een rijarchief,
TABLOCKleidt dit echter tot eenX(exclusieve) vergrendeling in de tabel in plaats van eenBU(bulkupdate)-vergrendeling en kan parallelle gegevensbelasting niet worden uitgevoerd. Voor meer informatie over vergrendelen, zie Vergrendelen en rijversies.Optimalisatie van vergrendeling: De
Xvergrendeling van een rijgroep wordt automatisch verkregen bij het laden van gegevens in een gecomprimeerde rijgroep. Wanneer u echter bulksgewijs laadt in een deltarijgroep, wordt er eenXvergrendeling verkregen voor de rijgroep, maar database-engine verkrijgt nog steeds pagina- en omvangvergrendelingen omdat de vergrendeling van deXrijgroep geen deel uitmaakt van de vergrendelingshiërarchie.
Als u een niet-geclusterde B-tree-index hebt voor een columnstore-index, is er geen vergrendelings- of logboekregistratieoptimalisatie voor de index zelf, maar zijn de optimalisaties voor de geclusterde columnstore-index zoals eerder beschreven van toepassing.
Grootten van bulksgewijs laden plannen om deltarijgroepen te minimaliseren
Columnstore-indexen presteren het beste wanneer de meeste rijen worden gecomprimeerd in de columnstore en niet in deltarijgroepen zitten. Het is raadzaam om de belasting zo groot mogelijk te maken, zodat rijen rechtstreeks naar de columnstore gaan en de deltastore zoveel mogelijk overslaan.
In deze scenario's wordt beschreven wanneer geladen rijen rechtstreeks naar de columnstore gaan of wanneer ze naar de deltastore gaan. In het voorbeeld kan elke rijgroep 102.400-1.048.576 rijen per rijgroep hebben. In de praktijk kan de maximale grootte van een rijgroep kleiner zijn dan 1.048.576 rijen wanneer er geheugendruk is.
| Rijen voor bulk laden | Rijen toegevoegd aan de gecomprimeerde rijengroep | Rijen die zijn toegevoegd aan de delta-rijgroep |
|---|---|---|
| 102,000 | 0 | 102,000 |
| 145,000 | 145,000 Grootte van rijgroep: 145.000 |
0 |
| 1,048,577 | 1,048,576 Grootte van rijgroep: 1.048.576. |
1 |
| 2,252,152 | 2,252,152 Rijengroepgrootten: 1.048.576, 1.048.576, 155.000. |
0 |
In het volgende voorbeeld ziet u de resultaten van het laden van 1.048.577 rijen in een tabel. De resultaten tonen aan dat er één gecomprimeerde rijgroep is in de columnstore (als gecomprimeerde kolomsegmenten) en één rij in de deltastore.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Een faseringstabel gebruiken om de prestaties te verbeteren
nl-NL: Als u gegevens alleen laadt om ze te verwerken voordat u meer transformaties uitvoert, is het laden van de tabel naar een heap-tabel veel sneller dan het laden van de gegevens naar een geclusterde kolomopslagtabel. Bovendien zal het laden van gegevens naar een [tijdelijke tabel][Tijdelijk] veel sneller gebeuren dan het laden van een tabel naar permanente opslag.
Een veelvoorkomend patroon voor het laden van gegevens is het laden van de gegevens in een faseringstabel, het uitvoeren van een transformatie en het vervolgens laden in de doeltabel met behulp van de volgende opdracht:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Met deze opdracht worden de gegevens in de columnstore-index geladen op vergelijkbare manieren als bcp of bulksgewijs invoegen, maar in één batch. Als het aantal rijen in de faseringstabel < 102400 wordt geladen, worden de rijen in een deltarijgroep geladen, anders worden de rijen rechtstreeks in gecomprimeerde rijgroep geladen. Een belangrijke beperking was dat deze INSERT bewerking één thread heeft. Als u gegevens parallel wilt laden, kunt u meerdere faseringstabellen maken of problemen INSERT/SELECT met niet-overlappende bereiken van rijen uit de faseringstabel. Deze beperking gaat weg met SQL Server 2016 (13.x). Met de volgende opdracht worden de gegevens uit de faseringstabel parallel geladen, maar u moet opgeven TABLOCK. Mogelijk vindt u dit tegenstrijdig met wat eerder is gezegd met bulksgewijs laden, maar het belangrijkste verschil is dat de parallelle gegevensbelasting van de faseringstabel wordt uitgevoerd onder dezelfde transactie.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Er zijn de volgende optimalisaties beschikbaar bij het laden in een geclusterde columnstore-index vanuit faseringstabel:
- Logboekoptimalisatie: Beperkte logboekregistratie wanneer de gegevens in een gecomprimeerde rijgroep worden geladen.
-
Optimalisatie van vergrendeling: Bij het laden van gegevens in een gecomprimeerde rijgroep wordt de
Xvergrendeling van de rijgroep verkregen. Wanneer u echter bulksgewijs laadt in een deltarijgroep, wordt er eenXvergrendeling verkregen voor de rijgroep, maar database-engine verkrijgt nog steeds pagina- en omvangvergrendelingen omdat de vergrendeling van deXrijgroep geen deel uitmaakt van de vergrendelingshiërarchie.
Als u een of meer niet-geclusterde indexen hebt, is er geen vergrendelings- of logboekregistratieoptimalisatie voor de index zelf, maar de optimalisaties voor de geclusterde columnstore-index zoals eerder beschreven, zijn er nog steeds.
Wat is trickle insert?
Invoeging van trickle verwijst naar de manier waarop afzonderlijke rijen naar de columnstore-index gaan. Trickle inserts gebruiken de INSERT INTO-instructie . Bij trickle insert gaan alle rijen naar de deltastore. Dit is handig voor kleine aantallen rijen, maar niet praktisch voor grote belastingen.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Note
Gelijktijdige threads die INSERT INTO gebruiken om waarden in te voegen in een geclusterde columnstore-index, kunnen rijen invoegen in dezelfde deltastore-rijgroep.
Zodra de rijgroep 1.048.576 rijen bevat, is de deltarijgroep die we hebben gemarkeerd als gesloten, maar deze is nog steeds beschikbaar voor query's en bijwerk-/verwijderbewerkingen, maar de nieuwe ingevoegde rijen gaan naar een bestaande of nieuw gemaakte deltastore-rijgroep. Er is een achtergrondthread met de naam tuple mover (TM) waarmee de gesloten deltarijgroepen periodiek om de 5 minuten worden gecomprimeerd. U kunt expliciet de volgende opdracht aanroepen om de gesloten deltarijgroep te comprimeren.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Als u een deltarijgroep gesloten en gecomprimeerd wilt afdwingen, kunt u de volgende opdracht uitvoeren. U kunt deze opdracht uitvoeren als u klaar bent met het laden van de rijen en geen nieuwe rijen verwacht. Door de deltarijgroep expliciet te sluiten en te comprimeren, kunt u de opslag verder opslaan en de prestaties van de analysequery verbeteren. U kunt deze opdracht het beste aanroepen als u niet verwacht dat nieuwe rijen worden ingevoegd.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
Hoe laden in een gepartitioneerde tabel werkt
Voor gepartitioneerde gegevens wijst de database-engine eerst elke rij toe aan een partitie en voert vervolgens columnstore-bewerkingen uit op de gegevens in de partitie. Elke partitie heeft zijn eigen rijgroepen en ten minste één deltarijgroep.