Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
van toepassing op:![]() SQL Server-
SQL Server-
In dit artikel wordt beschreven hoe u een geforceerde failover (met mogelijk gegevensverlies) uitvoert in een AlwaysOn-beschikbaarheidsgroep met behulp van SQL Server Management Studio, Transact-SQL of PowerShell in SQL Server. Een geforceerde failover is een vorm van handmatige failover die strikt bedoeld is voor herstel na noodgevallen, wanneer een geplande handmatige failover niet mogelijk is. Als u een failover afdwingt naar een niet-gesynchroniseerde secundaire replica, kan enig gegevensverlies optreden. Daarom raden we u ten zeerste aan om failover alleen af te dwingen als u de service onmiddellijk naar de beschikbaarheidsgroep moet herstellen en u bereid bent om gegevens te verliezen.
Na een geforceerde failover wordt het failoverdoel waarnaar de beschikbaarheidsgroep is overgeschakeld, de nieuwe primaire replica. De secundaire databases in de resterende secundaire replica's zijn gepauzeerd en moeten handmatig hervat worden. Wanneer de voormalige primaire replica beschikbaar komt, wordt deze overgezet naar de secundaire rol, waardoor de voormalige primaire databases secundaire databases worden en overstappen naar de SUSPENDED status. Voordat u een bepaalde secundaire database hervat, kunt u mogelijk verloren gegevens herstellen. U ziet echter dat het trunceren van transactielogboeken wordt vertraagd op een bepaalde primaire database terwijl een van de secundaire databases is geschorst.
Belangrijk
Gegevenssynchronisatie met de primaire database vindt pas plaats als de secundaire database wordt hervat. Zie Opvolgen: Essentiële taken na een geforceerde failover verderop in dit artikel voor meer informatie over het hervatten van een secundaire database.
Het uitvoeren van een geforceerde failover is nodig in de volgende noodsituaties:
Nadat u quorum hebt afgedwongen op het WSFC-cluster (geforceerde quorum), moet u failover per beschikbaarheidsgroep afdwingen (met mogelijk gegevensverlies). Het afdwingen van failover is vereist omdat de werkelijke status van de WSFC-clusterwaarden mogelijk verloren is gegaan. U kunt echter gegevensverlies voorkomen als u failover kunt afdwingen op het serverexemplaren dat als host fungeert voor de replica die de primaire replica was voordat u quorum dwong of naar een secundaire replica die is gesynchroniseerd voordat u quorum hebt geforceerd. Zie Mogelijke manieren om gegevensverlies te voorkomen nadat quorum is geforceerd, verderop in dit artikel voor meer informatie.
Belangrijk
Als quorum op natuurlijke wijze wordt hersteld in plaats van geforceerd te worden, worden de beschikbaarheidsreplica's normaal hersteld. Als de primaire replica nog steeds niet beschikbaar is nadat het quorum is hersteld, kunt u een geplande handmatige failover uitvoeren naar een gesynchroniseerde secundaire replica.
Voor meer informatie over het afdwingen van quorum, zie WSFC Disaster Recovery met een geforceerd quorum (SQL Server). Voor informatie over waarom het forceren van failover is vereist na het forceren van quorum, zie failover en failovermodi (Always On-beschikbaarheidsgroepen).
Als de primaire replica niet meer beschikbaar is wanneer het WSFC-cluster een goed functionerend quorum heeft, kunt u failover (met mogelijk gegevensverlies) afdwingen naar elke replica waarvan de rol in de
SECONDARYofRESOLVINGstatus is. Indien mogelijk, dwing failover af naar een synchrone commit secundaire replica die gesynchroniseerd was op het moment dat de primaire replica verloren ging.Aanbeveling
Wanneer het WSFC-cluster een goed functionerend quorum heeft, voert de replica een geplande handmatige failover uit als u een opdracht voor een geforceerde failover uitvoert op een gesynchroniseerde secundaire replica.
Zie voor meer informatie over de vereisten en aanbevelingen voor het afdwingen van failover en voor een voorbeeldscenario waarin een geforceerde failover wordt gebruikt om te herstellen van een catastrofale fout , voorbeeldscenario: Een geforceerde failover gebruiken om te herstellen van een catastrofale fout, verderop in dit artikel.
Beperkingen
De enige keer dat u geen geforceerde failover kunt uitvoeren, is wanneer het WSFC-cluster (Windows Server Failover Clustering) geen quorum heeft.
Gegevensverlies is mogelijk tijdens de geforceerde failover van een beschikbaarheidsgroep. Als de primaire replica wordt uitgevoerd wanneer u een geforceerde failover start, zijn clients mogelijk nog steeds verbonden met voormalige primaire databases. Daarom raden we u ten zeerste aan om failover alleen af te dwingen als de primaire replica niet meer wordt uitgevoerd en als u bereid bent gegevens te verliezen om de toegang tot databases in de beschikbaarheidsgroep te herstellen.
Wanneer een secundaire database zich in de
REVERTINGstatus ofINITIALIZINGstatus bevindt, kan het afdwingen van failover ertoe leiden dat de database niet kan worden gestart als een primaire database. Als de database deINITIALIZINGstatus heeft, moet u de ontbrekende logboekrecords uit een databaseback-up toepassen of de database helemaal opnieuw herstellen. Als de database deREVERTINGstatus heeft, moet u de database volledig herstellen vanuit back-ups.Een failoveropdracht wordt geretourneerd zodra het failoverdoel de opdracht heeft geaccepteerd. Databaseherstel vindt echter asynchroon plaats nadat de beschikbaarheidsgroep de failover heeft voltooid.
Consistentie tussen databases binnen de beschikbaarheidsgroep kan mogelijk niet worden gehandhaafd bij failover.
Notitie
Ondersteuning voor meerdere databases en gedistribueerde transacties variëren per SQL Server- en besturingssysteemversie. Zie Transacties - beschikbaarheidsgroepen en databasespiegeling voor meer informatie.
Voorwaarden
Het WSFC-cluster heeft quorum. Raadpleeg WSFC Disaster Recovery via het geforceerde quorum (SQL Server)als het cluster geen quorum heeft.
U moet verbinding kunnen maken met een serverexemplaar dat fungeert als host voor een replica waarvan de rol zich in de
SECONDARYofRESOLVINGstatus bevindt.
Aanbevelingen
Dwing geen failover af terwijl de primaire replica nog actief is.
Dwing, indien mogelijk, een failover alleen af naar een failoverdoel waarvan de secundaire databases zich in de status
NOT SYNCHRONIZED,SYNCHRONIZEDofSYNCHRONIZINGbevinden. ZieINITIALIZINGeerder in dit artikel voor meer informatie over de gevolgen van het afdwingen van failover wanneer een secundaire database zich in deREVERTINGof status bevindt.Normaal gesproken moet de latentie van een bepaalde secundaire database ten opzichte van de primaire database vergelijkbaar zijn op verschillende asynchrone secundaire replica's. Bij het afdwingen van failover kan gegevensverlies echter een grote zorg zijn. Overweeg daarom de tijd te nemen om de relatieve latentie van de databasekopieën op verschillende secundaire replica's vast te stellen. Als u wilt bepalen welke kopie van een bepaalde secundaire database de minste latentie heeft, vergelijkt u de LSN's voor het einde van het logboek. Een hogere end-of-log LSN geeft minder latentie aan.
Aanbeveling
Als u LSN's voor het einde van het logboek wilt vergelijken, maakt u verbinding met elke online secundaire replica en voert u een query uit op sys.dm_hadr_database_replica_states voor de
end_of_log_lsnwaarde van elke lokale secundaire database. Vergelijk vervolgens de LSN's voor het einde van het logboek van de verschillende kopieën van elke database. Verschillende databases kunnen hun hoogste LSN's hebben op verschillende secundaire replica's. In dit geval is het meest geschikte failoverdoel afhankelijk van het relatieve belang dat u op de gegevens in de verschillende databases plaatst. Dat wil zeggen, voor welke van deze databases wilt u mogelijk gegevensverlies minimaliseren?Als clients verbinding kunnen maken met de oorspronkelijke primaire, leidt een geforceerde failover tot een risico van gesplitst hersengedrag. Voordat u failover forceert, raden we u ten zeerste aan om te voorkomen dat clients toegang hebben tot de oorspronkelijke primaire replica. Anders kunnen na een failover de oorspronkelijke primaire databases en de huidige primaire databases onafhankelijk van de andere worden bijgewerkt.
Mogelijke manieren om gegevensverlies te voorkomen nadat quorum is geforceerd
Onder bepaalde foutvoorwaarden nadat het quorum is verbroken, kunt u gegevensverlies als volgt voorkomen:
Als de oorspronkelijke primaire replica online komt
Als quorum verloren gaat en het afdwingen van het WSFC-quorum het clusterknooppunt herstelt dat fungeert als host voor de primaire replica van een beschikbaarheidsgroep, kunt u gegevensverlies voor deze groep beschikbaarheid voorkomen. Maak verbinding met de primaire replica en voer een geforceerde failover uit (FAILOVER_ALLOW_DATA_LOSS). Hierdoor is de primaire replica weer online. Omdat u de geforceerde failover naar de oorspronkelijke primaire replica uitvoert, is er geen gegevensverlies.
Als een gesynchroniseerde secundaire replica voor synchrone doorvoer online komt
Als quorum verloren gaat en WSFC-quorum wordt afgedwongen om een clusterknooppunt te herstellen dat een gesynchroniseerde secundaire replica voor een beschikbaarheidsgroep host, moet u in staat zijn gegevensverlies voor deze beschikbaarheidsgroep te voorkomen. Als het herstelde knooppunt operationeel was op het moment dat het quorum werd verbroken, kunt u bepalen of er gegevensverlies op een bepaalde database kan optreden door een query uit te voeren op de
is_failover_readykolom van de sys.dm_hadr_database_replica_cluster_states dynamische beheerweergave. Voer bijvoorbeeld de volgende query uit voor een serverexemplaar met de naamsql108w2k8r22.SELECT * FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id = ( SELECT replica_id FROM sys.availability_replicas WHERE replica_server_name = 'sql108w2k8r22' );Voorzichtigheid
Als het herstelde knooppunt niet operationeel was op het moment dat het quorum verloren ging, geeft
is_failover_readymogelijk niet de feitelijke toestand van het cluster weer op het moment dat de primaire replica offline ging. Daarom is deis_failover_readywaarde alleen geldig als het hostknooppunt op het moment van de fout aanwezig is. Zie 'Waarom geforceerde failover is vereist na het afdwingen van quorum' in failover- en failovermodi (AlwaysOn-beschikbaarheidsgroepen)voor meer informatie.Als
is_failover_ready = 1wordt voldaan, wordt de database als gesynchroniseerd gemarkeerd in het cluster en is deze gereed voor een failover. Alsis_failover_ready = 1op elke database op een bepaalde secundaire replica beschikbaar is, kunt u een geforceerde failover (FORCE_FAILOVER_ALLOW_DATA_LOSS) uitvoeren zonder gegevensverlies op deze secundaire replica. De gesynchroniseerde secundaire replica is online in de primaire rol, namelijk als de nieuwe primaire replica, met alle gegevens intact.Als
is_failover_ready = 0de database niet is gemarkeerd als gesynchroniseerd in het cluster en niet gereed is voor een geplande handmatige failover. Als u failover naar de secundaire hostreplica afdwingen, gaan er gegevens verloren in deze database.Notitie
Wanneer u een failover naar een secundaire replica afdwingt, is de hoeveelheid gegevensverlies afhankelijk van hoe ver het failoverdoelwit achter de primaire replica blijft. Helaas kunt u, wanneer het WSFC-cluster geen quorum heeft of als quorum is afgedwongen, de hoeveelheid mogelijk gegevensverlies niet beoordelen. Houd er echter rekening mee dat wanneer het WSFC-cluster weer een goed quorum krijgt, u potentiële gegevensverlies kunt bijhouden. Zie 'Mogelijk gegevensverlies bijhouden' in failover- en failovermodi (AlwaysOn-beschikbaarheidsgroepen)voor meer informatie.
Machtigingen
Vereist ALTER AVAILABILITY GROUP machtigingen voor de beschikbaarheidsgroep, CONTROL AVAILABILITY GROUP machtiging, ALTER ANY AVAILABILITY GROUP machtiging of CONTROL SERVER machtiging.
SQL Server Management Studio gebruiken
Maak in Objectverkenner verbinding met een serverexemplaar dat als host fungeert voor een replica waarvan de rol zich bevindt in de
SECONDARYofRESOLVINGstatus in de beschikbaarheidsgroep waarvoor een failover moet worden uitgevoerd, en vouw de serverstructuur uit.Vouw het knooppunt Always On Hoge Beschikbaarheid en het Beschikbaarheidsgroepen knooppunt uit.
Klik met de rechtermuisknop op de beschikbaarheidsgroep waarvoor een failover moet worden uitgevoerd en selecteer de opdracht Failover.
Hiermee wordt de wizard Failover-Beschikbaarheidsgroep gestart. Voor meer informatie, zie De wizard Failover-beschikbaarheidsgroep gebruiken (SQL Server Management Studio).
Nadat u een failover van een beschikbaarheidsgroep hebt afgedwongen, moet u de benodigde vervolgstappen uitvoeren. Zie Opvolgen: Essentiële taken na een geforceerde failover verderop in dit artikel voor meer informatie.
Gebruik Transact-SQL
Maak verbinding met een serverexemplaren die als host fungeert voor een replica waarvan de rol de
SECONDARYstatus ofRESOLVINGstatus heeft in de beschikbaarheidsgroep waarvoor een failover moet worden uitgevoerd.Gebruik de instructie ALTER AVAILABILITY GROUP als volgt, waarbij group_name de naam van de beschikbaarheidsgroep is:
ALTER AVAILABILITY GROUP <group_name> FORCE_FAILOVER_ALLOW_DATA_LOSS.In het volgende voorbeeld wordt de
AccountsAG-beschikbaarheidsroep gedwongen om over te schakelen naar de lokale secundaire replica.ALTER AVAILABILITY GROUP AccountsAG FORCE_FAILOVER_ALLOW_DATA_LOSS;Nadat u een failover van een beschikbaarheidsgroep hebt afgedwongen, moet u de benodigde vervolgstappen uitvoeren. Zie Essentiële taken na een geforceerde failover verderop in dit artikel voor meer informatie.
PowerShell gebruiken
Wijzig de map (
cd) naar een serverexemplaar dat een replica host waarvan de rol zich in deSECONDARY- ofRESOLVING-status bevindt in de beschikbaarheidsgroep die moet worden omgeschakeld.Gebruik de
Switch-SqlAvailabilityGroupcmdlet met deAllowDataLossparameter in een van de volgende formulieren:-AllowDataLoss-AllowDataLossStandaard zorgt de parameter ervoorSwitch-SqlAvailabilityGroupdat u wordt gevraagd u eraan te herinneren dat het afdwingen van failover kan leiden tot het verlies van niet-doorgevoerde transacties en om bevestiging aan te vragen. Als u wilt doorgaan, voert uYin; om de bewerking te annuleren, voert uNin.In het volgende voorbeeld wordt een geforceerde failover uitgevoerd (met mogelijk gegevensverlies) van de beschikbaarheidsgroep
MyAgnaar de secundaire replica op het serverexemplaren met de naamSecondaryServer\InstanceName. U wordt gevraagd deze bewerking te bevestigen.Switch-SqlAvailabilityGroup ` -Path SQLSERVER:\Sql\SecondaryServer\InstanceName\AvailabilityGroups\MyAg ` -AllowDataLoss-AllowDataLoss-ForceOm een geforceerde failover te initiëren zonder bevestiging, geeft u zowel de parameters
-AllowDataLossals-Forceop. Dit is handig als u de opdracht in een script wilt opnemen en wilt uitvoeren zonder tussenkomst van de gebruiker. Gebruik de-Forceoptie echter voorzichtig, omdat een geforceerde failover kan leiden tot het verlies van gegevens van databases die deelnemen aan de beschikbaarheidsgroep.In het volgende voorbeeld wordt een geforceerde failover uitgevoerd (met mogelijk gegevensverlies) van de beschikbaarheidsgroep
MyAgnaar het serverexemplaren met de naamSecondaryServer\InstanceName. De-Forceoptie onderdrukt de bevestiging van deze bewerking.Switch-SqlAvailabilityGroup ` -Path SQLSERVER:\Sql\SecondaryServer\InstanceName\AvailabilityGroups\MyAg ` -AllowDataLoss -Force
Notitie
Als u de syntaxis van een cmdlet wilt weergeven, gebruikt u de
Get-Helpcmdlet in de SQL Server PowerShell-omgeving. Voor meer informatie, zie Hulp krijgen SQL Server PowerShell.Nadat u een failover van een beschikbaarheidsgroep hebt afgedwongen, moet u de benodigde vervolgstappen uitvoeren. Zie Opvolgen: Essentiële taken na een geforceerde failover verderop in dit artikel voor meer informatie.
De SQL Server PowerShell-provider instellen en gebruiken
Opvolgen: Essentiële taken na een geforceerde failover
Na een geforceerde failover wordt de secundaire replica waarnaar u een failover hebt uitgevoerd, de nieuwe primaire replica. Als u deze beschikbaarheidsreplica echter toegankelijk wilt maken voor clients, moet u mogelijk het WSFC-quorum opnieuw configureren of de configuratie van de beschikbaarheidsmodus van de beschikbaarheidsgroep als volgt aanpassen:
Als u een failover hebt uitgevoerd buiten de automatische failoverset: de quorumstemmen van de WSFC-knooppunten aanpassen aan de configuratie van uw nieuwe beschikbaarheidsgroep. Als het WSFC-knooppunt dat als host fungeert voor de secundaire doelreplica geen WSFC-quorumstem heeft, moet u mogelijk het WSFC-quorum afdwingen.
Er bestaat alleen een automatische failoverset als twee beschikbaarheidsreplica's (inclusief de vorige primaire replica) zijn geconfigureerd voor de synchrone doorvoermodus met automatische failover.
Quorumstemmen aanpassen
Als u een failover hebt uitgevoerd buiten de failoverset voor synchrone bevestiging: We raden aan om de beschikbaarheidsmodus en failovermodus aan te passen voor de nieuwe primaire replica en de resterende secundaire replica's, om uw gewenste configuratie voor synchrone bevestiging en automatische failover weer te geven.
Notitie
Er bestaat alleen een failoverset voor synchrone doorvoer als de huidige primaire replica is geconfigureerd voor de synchrone doorvoermodus.
De beschikbaarheidsmodus en failovermodus wijzigen
Na een geforceerde failover worden alle secundaire databases onderbroken. Dit omvat de voormalige primaire databases, nadat de voormalige primaire replica weer online komt en vaststelt dat het nu een secundaire replica is. U moet elke onderbroken database handmatig afzonderlijk hervatten op elke secundaire replica.
Wanneer een secundaire database wordt hervat, wordt gegevenssynchronisatie gestart met de bijbehorende primaire database. De secundaire database rolt alle logboekrecords terug die nooit zijn doorgevoerd in de nieuwe primaire database. Als u zich zorgen maakt over mogelijk gegevensverlies bij de primaire databases na een failover, moet u proberen een momentopname van de database te maken op de geschorste databases van een van de secundaire databases die op synchronische committering werken.
Belangrijk
Het bijwerken van het transactielogboek op een primaire database wordt vertraagd zolang een van de secundaire databases is opgeschort. De synchronisatiestatus van een synchrone doorvoer secundaire replica kan ook niet worden overgezet naar
HEALTHYzolang een lokale database onderbroken blijft.Een momentopname van een database maken
Een beschikbaarheidsdatabase hervatten
Voorzichtigheid
Nadat alle secundaire databases zijn hervat, wacht u voordat u opnieuw probeert een failover van de groep uit te voeren, totdat elke secundaire database op het volgende failoverdoel de toestand
SYNCHRONIZINGheeft bereikt. Als een database nogSYNCHRONIZINGniet is, kan die database niet online komen als primaire database en kan het opnieuw tot stand brengen van gegevenssynchronisatie voor de database vereisen dat transactielogboeken worden hersteld, een volledige databaseback-up wordt hersteld of een failover naar de vorige primaire replica wordt uitgevoerd.Als een mislukt beschikbaarheidsreplica niet terugkeert naar de beschikbaarheidsgroep of te laat terugkeert om het uitstellen van de truncatie van het transactielogboek op de nieuwe primaire database mogelijk te maken, kunt u overwegen om de mislukte replica uit de beschikbaarheidsgroep te verwijderen om te voorkomen dat er onvoldoende schijfruimte beschikbaar is voor uw logboekbestanden.
Een secundaire replica verwijderen
Als u een gedwongen failover volgt met een of meer extra gedwongen failovers, voert u na elke extra gedwongen failover in de serie een logboekback-up uit. Zie 'Risico's bij het afdwingen van failover' in de sectie 'Geforceerde handmatige failover (met mogelijk gegevensverlies)' van failover- en failovermodi (AlwaysOn-beschikbaarheidsgroepen).
Een back-up van logboeken uitvoeren
Voorbeeldscenario: Een geforceerde failover gebruiken om te herstellen van een onherstelbare fout
Als de primaire replica mislukt en er geen gesynchroniseerde secundaire replica beschikbaar is, kan het zijn dat de beschikbaarheidsgroep een failover moet uitvoeren. De geschiktheid van het afdwingen van een failover is afhankelijk van: (1) of u verwacht dat de primaire replica langer offline is dan uw SLA (Service Level Agreement) tolereert, en (2) of u bereid bent potentiële gegevensverlies te riskeren om primaire databases snel beschikbaar te maken. Als u besluit dat een beschikbaarheidsgroep een geforceerde failover vereist, is de daadwerkelijke geforceerde failover slechts één stap van een proces met meerdere stappen.
Ter illustratie van de stappen die nodig zijn voor het gebruik van een geforceerde failover om te herstellen van een catastrofale fout, wordt in dit artikel een mogelijk scenario voor herstel na noodgevallen weergegeven. In het voorbeeldscenario wordt een beschikbaarheidsgroep beschouwd waarvan de oorspronkelijke topologie bestaat uit een hoofddatacentrum dat als host fungeert voor drie synchrone doorvoerbeschikbaarheidsreplica's, waaronder de primaire replica, en een extern datacenter dat als host fungeert voor twee asynchrone secundaire replica's. In de volgende afbeelding ziet u de oorspronkelijke topologie van deze voorbeeld beschikbaarheidsgroep. De beschikbaarheidsgroep wordt gehost door een WSFC-cluster met meerdere subnetten met drie knooppunten in het hoofddatacentrum (Node 01, Node 02en Node 03) en twee knooppunten in een extern datacenter (Node 04 en Node 05).

Het belangrijkste datacenter wordt onverwacht afgesloten. Wanneer de drie beschikbaarheidsreplica's offline gaan, worden hun databases onbeschikbaar. In de volgende afbeelding ziet u het effect van deze fout op de topologie van de beschikbaarheidsgroep.

De databasebeheerder (DBA) bepaalt dat de beste reactie is om een failover van de beschikbaarheidsgroep te forceren naar een van de externe, asynchrone secundaire replica's. In dit voorbeeld ziet u de gebruikelijke stappen bij het afdwingen van failover van de beschikbaarheidsgroep naar een externe replica en uiteindelijk wordt de beschikbaarheidsgroep naar de oorspronkelijke topologie geretourneerd.
De hier gepresenteerde storingsreactie bestaat uit de volgende twee stadia:
- Reageren op de catastrofale fout van het hoofddatacentrum
- De beschikbaarheidsgroep terugsturen naar de oorspronkelijke topologie
Reageren op de catastrofale fout van het hoofddatacentrum
In de volgende afbeelding ziet u de reeks acties die in het externe datacenter worden uitgevoerd als reactie op een onherstelbare fout in het hoofddatacentrum.
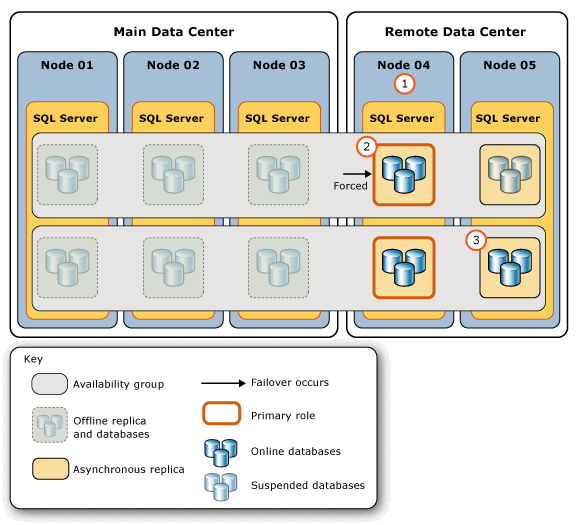
De stappen in deze afbeelding geven de volgende stappen aan:
| Stap | Actie | Koppelingen |
|---|---|---|
1. |
De DBA- of netwerkbeheerder zorgt ervoor dat het WSFC-cluster een goed quorum heeft. In dit voorbeeld moet quorum worden afgedwongen. |
WSFC-quorum-modi en stem-configuratie (SQL Server) WSFC Disaster Recovery door middel van een geforceerd quorum (SQL Server) |
2. |
De DBA maakt verbinding met de serverexemplaar met de minste latentie (op Node 04) en voert een geforceerde handmatige failover uit. De geforceerde failover verplaatst deze secundaire replica naar de primaire rol en onderbreekt de secundaire databases op de resterende secundaire replica (op Node 05). | sys.dm_hadr_database_replica_states (voer een query uit op de kolom end_of_log_lsn . Zie Aanbevelingen eerder in dit artikel voor meer informatie.) |
3. |
De DBA hervat handmatig iedere secundaire database op de resterende secundaire replica. | Een beschikbaarheidsdatabase hervatten (SQL Server) |
De beschikbaarheidsgroep terugsturen naar de oorspronkelijke topologie
In de volgende afbeelding ziet u de reeks acties die de beschikbaarheidsgroep naar de oorspronkelijke topologie retourneren nadat het belangrijkste datacenter weer online is en de WSFC-knooppunten de communicatie met het WSFC-cluster opnieuw tot stand brengen.
Belangrijk
Als het WSFC-clusterquorum is geforceerd, omdat de offlineknooppunten opnieuw worden opgestart, kunnen ze een nieuw quorum vormen als beide voorwaarden bestaan: (a) er is geen netwerkverbinding tussen een van de knooppunten in de geforceerde quorumset en (b) de herstartknooppunten zijn het merendeel van de clusterknooppunten. Dit zou resulteren in een 'split brain'-voorwaarde waarin de beschikbaarheidsgroep twee onafhankelijke primaire replica's zou bezitten, één in elk datacenter. Voordat u het quorum dwingt om een minderheidsquorumset te maken, raadpleegt u WSFC Disaster Recovery via Geforceerd Quorum (SQL Server).

De stappen in deze afbeelding geven de volgende stappen aan:
| Stap | Actie | Koppelingen |
|---|---|---|
1. |
De knooppunten in het hoofddatacentrum komen weer online en brengen de communicatie met het WSFC-cluster opnieuw tot stand. De beschikbaarheidsreplica's zijn online als secundaire replica's met onderbroken databases en de DBA moet elk van deze databases binnenkort handmatig hervatten. |
Een beschikbaarheidsdatabase hervatten (SQL Server) Tip: Als u zich zorgen maakt over mogelijk gegevensverlies op de primaire databases na de failover-procedure, moet u proberen een momentopname van de database te maken op de onderbroken databases van een van de secundaire databases met synchrone-commit. Houd er rekening mee dat het inkorten van het transactielogboek wordt vertraagd op een primaire database terwijl een van de secundaire databases wordt opgeschort. De synchronisatieconditie van de secundaire replica met synchrone commit kan niet overgaan naar HEALTHY zolang een lokale database onderbroken blijft. |
2. |
Zodra de databases zijn hervat, wijzigt de DBA de nieuwe primaire replica tijdelijk in de synchrone doorvoermodus. Dit omvat twee stappen: 1. Wijzig één replica van offline beschikbaarheid naar de asynchroon commit-modus. 2. Wijzig de nieuwe primaire replica naar de synchrone commitmodus. Notitie: Met deze stap kunnen secundaire databases SYNCHRONIZEDmet synchrone doorvoer worden hervat. |
De beschikbaarheidsmodus van een replica binnen een AlwaysOn-beschikbaarheidsgroep wijzigen |
3. |
Zodra de secundaire replica met synchrone commit op knooppunt 03 (de oorspronkelijke primaire replica) de synchronisatiestatus bereikt, voert de DBA een geplande handmatige failover naar die replica uit, waardoor deze opnieuw de primaire replica wordt. De replica op Node 04 keert terug naar een secundaire replica. |
sys.dm_hadr_database_replica_states Gebruik Always On-beleid om de status van een beschikbaarheidsgroep (SQL Server) weer te geven Een geplande handmatige failover uitvoeren van een AlwaysOn-beschikbaarheidsgroep (SQL Server) |
4. |
De DBA maakt verbinding met de nieuwe primaire replica en: 1. Wijzigt de voormalige primaire replica (in de externe locatie) weer in de asynchrone-commitmodus. 2. Hiermee wijzigt u de secundaire replica van asynchrone doorvoer in het hoofddatacentrum weer in de modus synchrone doorvoer. |
De beschikbaarheidsmodus van een replica binnen een AlwaysOn-beschikbaarheidsgroep wijzigen |
Gerelateerde taken
Quorumstemmen aanpassen
- clusterquorumknooppuntgewichtinstellingen weergeven
- Cluster Quorum knooppuntgewicht instellingen configureren
- een WSFC-cluster geforceerd starten zonder quorum
Geplande handmatige failover
- Een geplande handmatige failover uitvoeren van een AlwaysOn-beschikbaarheidsgroep (SQL Server)
- Gebruik de Wizard Failover-Beschikbaarheidsgroepen (SQL Server Management Studio)
Troubleshoot
- problemen met configuratie van AlwaysOn-beschikbaarheidsgroepen (SQL Server) oplossen
- problemen met een mislukte Add-File bewerking (AlwaysOn-beschikbaarheidsgroepen) oplossen
Verwante inhoud
- SQL Server AlwaysOn Team Blogs: de officiële SQL Server Always On Team Blog
- CSS SQL Server Ingenieurs Blogs
- Microsoft SQL Server AlwaysOn-oplossingengids voor hoge beschikbaarheid en herstel na noodgevallen
- Wat is een AlwaysOn-beschikbaarheidsgroep?
- Verschillen tussen beschikbaarheidsmodi voor een AlwaysOn-beschikbaarheidsgroep
- Failover en Failover-modi (Always On-beschikbaarheidsgroepen)
- Typen clientverbindingen met replica's binnen een AlwaysOn-beschikbaarheidsgroep
- Hulpprogramma's voor het bewaken van AlwaysOn-beschikbaarheidsgroepen
- Windows Server-failoverclustering met SQL Server