Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of de directory te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen de mappen te wijzigen.
In dit artikel leert u hoe u een query uitvoert op één CSV-bestand met behulp van een serverloze SQL-pool in Azure Synapse Analytics. CSV-bestanden hebben mogelijk verschillende indelingen:
- Met en zonder koprij
- Door komma's en tabs gescheiden waarden
- Einden van lijnen in Windows- en Unix-stijl
- Niet-geciteerde en geciteerde waarden, en ontsnappingskarakters
Alle bovenstaande variaties worden hieronder behandeld.
Quickstart-voorbeeld
OPENROWSET met de functie kunt u de inhoud van het CSV-bestand lezen door de URL naar uw bestand op te geven.
Een CSV-bestand lezen
De eenvoudigste manier om de inhoud van uw CSV bestand te bekijken, is door de bestands-URL aan de OPENROWSET functie te geven, en vervolgens csv FORMAT en versie 2.0 PARSER_VERSION op te geven. Als het bestand openbaar beschikbaar is of als uw Microsoft Entra-identiteit toegang heeft tot dit bestand, moet u de inhoud van het bestand kunnen zien met behulp van de query, zoals in het volgende voorbeeld:
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2 ) as rows
De optie firstrow wordt gebruikt om de eerste rij in het CSV-bestand over te slaan die in dit geval de koptekst vertegenwoordigt. Zorg ervoor dat u toegang hebt tot dit bestand. Als uw bestand is beveiligd met een SAS-sleutel of aangepaste identiteit, moet u referenties op serverniveau instellen voor sql-aanmelding.
Belangrijk
Als uw CSV-bestand UTF-8 tekens bevat, moet u ervoor zorgen dat u een UTF-8-databasesortering gebruikt (bijvoorbeeld Latin1_General_100_CI_AS_SC_UTF8).
Een onjuiste overeenkomst tussen tekstcodering in het bestand en de sortering kunnen onverwachte conversiefouten veroorzaken.
U kunt eenvoudig de standaardsortering van de huidige database wijzigen met behulp van de volgende T-SQL-instructie: alter database current collate Latin1_General_100_CI_AI_SC_UTF8
Gebruik van gegevensbronnen
In het vorige voorbeeld wordt het volledige pad naar het bestand gebruikt. Als alternatief kunt u een externe gegevensbron maken met de locatie die verwijst naar de hoofdmap van de opslag:
create external data source covid
with ( location = 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases' );
Zodra u een gegevensbron hebt gemaakt, kunt u die gegevensbron en het relatieve pad naar het bestand in OPENROWSET functie gebruiken:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) as rows
Als een gegevensbron is beveiligd met een SAS-sleutel of een aangepaste identiteit, kunt u de gegevensbron configureren met een databasespecifieke referentie.
Schema expliciet opgeven
OPENROWSET hiermee kunt u expliciet opgeven welke kolommen u uit het bestand wilt lezen met behulp van WITH de component:
select top 10 *
from openrowset(
bulk 'latest/ecdc_cases.csv',
data_source = 'covid',
format = 'csv',
parser_version ='2.0',
firstrow = 2
) with (
date_rep date 1,
cases int 5,
geo_id varchar(6) 8
) as rows
De getallen na een gegevenstype in de WITH component vertegenwoordigen de kolomindex in het CSV-bestand.
Belangrijk
Als uw CSV-bestand UTF-8 tekens bevat, moet u ervoor zorgen dat u expliciet een UTF-8-sortering opgeeft (bijvoorbeeld Latin1_General_100_CI_AS_SC_UTF8) voor alle kolommen in de WITH component of een UTF-8-sortering instelt op databaseniveau.
Niet-overeenkomende tekstcodering in het bestand en sortering kunnen onverwachte conversiefouten veroorzaken.
U kunt eenvoudig de standaardsortering van de huidige database wijzigen met behulp van de volgende T-SQL-instructie:
alter database current collate Latin1_General_100_CI_AI_SC_UTF8 U kunt eenvoudig sortering instellen voor de kolomtypen met behulp van de volgende definitie: geo_id varchar(6) collate Latin1_General_100_CI_AI_SC_UTF8 8
In de volgende secties ziet u hoe u een query kunt uitvoeren op verschillende typen CSV-bestanden.
Vereisten
De eerste stap is het maken van een database waarin de tabellen worden gemaakt. Initialiseer vervolgens de objecten door een installatiescript uit te voeren op die database. Met dit script voor installatie worden de gegevensbronnen, database-specifieke referenties en externe bestandsindelingen gemaakt die in deze voorbeelden worden gebruikt.
Nieuwe regel in Windows-stijl
De volgende query laat zien hoe u een CSV-bestand kunt lezen zonder een veldnamenrij, met een nieuwe regel in Windows-stijl en door komma's gescheiden kolommen.
Bestandsvoorbeeld:

SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Nieuwe lijn in Unix-stijl
De volgende query laat zien hoe u een bestand zonder veldnamenrij kunt lezen, met een nieuwe regel in Unix-stijl en door komma's gescheiden kolommen. Noteer de verschillende locatie van het bestand in vergelijking met de andere voorbeelden.
Bestandsvoorbeeld:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Kopregel
De volgende query laat zien hoe u een bestand met een koprij, een nieuwe regel in Unix-stijl en door komma’s gescheiden kolommen kunt lezen. Noteer de verschillende locatie van het bestand in vergelijking met de andere voorbeelden.
Bestandsvoorbeeld:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
HEADER_ROW = TRUE
) AS [r]
De optie HEADER_ROW = TRUE resulteert in het lezen van kolomnamen uit de veldnamenrij in het bestand. Het is handig voor verkenningsdoeleinden wanneer u niet bekend bent met bestandsinhoud. Zie de sectie Geschikte gegevenstypen gebruiken in Aanbevolen procedures voor de beste prestaties. U kunt hier ook meer lezen over de syntaxis van OPENROWSET.
Aangepast aanhalingsteken
De volgende query laat zien hoe u een bestand leest met een veldnamenrij, met een nieuwe regel in Unix-stijl, door komma's gescheiden kolommen en waarden tussen aanhalingstekens. Noteer de verschillende locatie van het bestand in vergelijking met de andere voorbeelden.
Bestandsvoorbeeld:

SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
FIELDQUOTE = '"'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017;
Notitie
Deze query geeft dezelfde resultaten als u de parameter FIELDQUOTE weglaat, omdat de standaardwaarde voor FIELDQUOTE een dubbele aanhalingsteken is.
Escapetekens
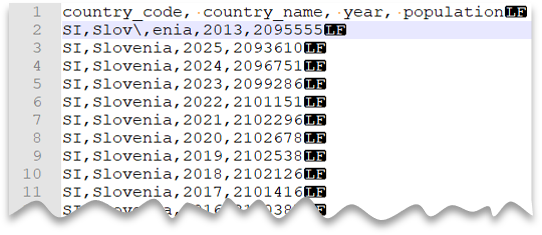
De volgende query laat zien hoe u een bestand met een veldnamenrij kunt lezen, met een nieuwe regel in Unix-stijl, door komma's gescheiden kolommen en een escapeteken dat wordt gebruikt voor het veldscheidingsteken (komma) binnen waarden. Noteer de verschillende locatie van het bestand in vergelijking met de andere voorbeelden.
Bestandsvoorbeeld:
SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2,
ESCAPECHAR = '\\'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Notitie
Deze query mislukt als ESCAPECHAR niet is opgegeven omdat de komma in "Slov,enia" wordt behandeld als veldscheidingsteken in plaats van als onderdeel van de land-/regionaam. "Slov,enia" wordt beschouwd als twee kolommen. Daarom heeft de specifieke rij één kolom meer dan de andere rijen en één kolom meer dan u hebt gedefinieerd in de WITH-component.
Escape-aanhalingstekens
De volgende query laat zien hoe u een bestand leest met een veldnamenrij, met een nieuwe regel in Unix-stijl, door komma's gescheiden kolommen en een escaped teken voor dubbele aanhalingstekens binnen waarden. Noteer de verschillende locatie van het bestand in vergelijking met de andere voorbeelden.
Bestandsvoorbeeld:

SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-escape-quoted/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Slovenia';
Notitie
Het aanhalingsteken moet met een ander aanhalingsteken worden geescaped. Een aanhalingsteken kan alleen binnen een kolomwaarde voorkomen als de waarde is ingesloten door aanhalingstekens.
Tab-gescheiden bestanden
De volgende query laat zien hoe u een bestand leest met een kopregel, een nieuwe regel in Unix-stijl en kolommen die door tabs gescheiden zijn. Noteer de verschillende locatie van het bestand in vergelijking met de andere voorbeelden.
Bestandsvoorbeeld:

SELECT *
FROM OPENROWSET(
BULK 'csv/population-unix-hdr-tsv/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR ='\t',
ROWTERMINATOR = '0x0a',
FIRSTROW = 2
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r]
WHERE
country_name = 'Luxembourg'
AND year = 2017
Een subset van kolommen retourneren
Tot nu toe hebt u het CSV-bestandsschema opgegeven met behulp van de WITH-instructie en door alle kolommen op te sommen. U kunt alleen kolommen opgeven die u in uw query nodig hebt met behulp van een rangnummer voor elke kolom die nodig is. U laat ook kolommen zonder interesse weg.
De volgende query retourneert het aantal afzonderlijke land-/regionamen in een bestand, waarbij alleen de kolommen worden opgegeven die nodig zijn:
Notitie
Bekijk de WITH-component in de onderstaande query en houd er rekening mee dat er '2' (zonder aanhalingstekens) aan het einde van de rij staat waarin u de kolom [country_name] definieert. Dit betekent dat de kolom [country_name] de tweede kolom in het bestand is. De query negeert alle kolommen in het bestand, behalve de tweede.
SELECT
COUNT(DISTINCT country_name) AS countries
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV', PARSER_VERSION = '2.0',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
--[country_code] VARCHAR (5),
[country_name] VARCHAR (100) 2
--[year] smallint,
--[population] bigint
) AS [r]
Query's uitvoeren op toevoegbare bestanden
De CSV-bestanden die in de query worden gebruikt, moeten niet worden gewijzigd terwijl de query wordt uitgevoerd. In de langlopende query kan de SQL-pool leesbewerkingen opnieuw proberen, delen van de bestanden lezen of zelfs meerdere keren het bestand lezen. Wijzigingen van de bestandsinhoud veroorzaken verkeerde resultaten. Daarom mislukt de SQL-pool de query als wordt gedetecteerd dat de wijzigingstijd van een bestand wordt gewijzigd tijdens de uitvoering van de query.
In sommige scenario's wilt u mogelijk de bestanden lezen die voortdurend worden toegevoegd. Als u de queryfouten wilt voorkomen vanwege voortdurend toegevoegde bestanden, kunt u toestaan dat de OPENROWSET functie mogelijk inconsistente leesbewerkingen negeert met behulp van de ROWSET_OPTIONS instelling.
select top 10 *
from openrowset(
bulk 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
format = 'csv',
parser_version = '2.0',
firstrow = 2,
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}') as rows
Met ALLOW_INCONSISTENT_READS de leesoptie wordt de tijdscontrole voor het wijzigen van bestanden uitgeschakeld tijdens de levenscyclus van de query en wordt gelezen wat er beschikbaar is in het bestand. In de toevoegbare bestanden wordt de bestaande inhoud niet bijgewerkt en worden alleen nieuwe rijen toegevoegd. Daarom wordt de kans op verkeerde resultaten geminimaliseerd in vergelijking met de bijwerkbare bestanden. Met deze optie kunt u mogelijk de vaak toegevoegde bestanden lezen zonder de fouten te verwerken. In de meeste scenario's negeert de SQL-pool slechts enkele rijen die tijdens de uitvoering van de query worden toegevoegd aan de bestanden.
Verwante inhoud
In de volgende artikelen wordt uitgelegd hoe u het volgende kunt doen: