Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
In deze quickstart gebruikt u Azure Portal om een Apache Spark-cluster te maken in Azure HDInsight. Vervolgens maakt u een Jupyter-notebook en gebruikt u dit om Spark SQL-query's uit te voeren op Apache Hive-tabellen. Azure HDInsight is een beheerde, zeer uitgebreide open-source analyseservice voor bedrijven. Het Apache Spark-raamwerk voor HDInsight maakt het mogelijk om snelle gegevensanalyses en clusterberekeningen uit te voeren met behulp van verwerking in het geheugen. Met Jupyter Notebook kunt u communiceren met uw gegevens, code combineren met markdown-tekst en eenvoudige visualisaties uitvoeren.
Zie Clusters instellen in HDInsight voor uitgebreide uitleg over de beschikbare configuraties. Zie Clusters maken in de portal voor meer informatie over het gebruik van de portal om clusters te maken.
Als u meerdere clusters samen gebruikt, kunt u een virtueel netwerk maken; Als u een Spark-cluster gebruikt, wilt u mogelijk ook de Hive Warehouse-connector gebruiken. Zie voor meer informatie Een virtueel netwerk plannen voor Azure HDInsight en Apache Spark en Apache Hive integreren met de Hive Warehouse Connector.
Belangrijk
Facturering voor HDInsight-clusters wordt naar rato per minuut berekend, ongeacht of u deze gebruikt of niet. Verwijder uw cluster daarom als u er klaar mee bent. Zie voor meer informatie de sectie Resources opschonen van dit artikel.
Vereiste voorwaarden
Een Azure-account met een actief abonnement. Gratis een account maken
Een Apache Spark-cluster maken in Azure HDInsight
U gebruikt Azure Portal om een HDInsight-cluster te maken dat gebruikmaakt van Azure Storage-blobs als clusteropslag. Zie Snelstart: Clusters instellen in HDInsight voor meer informatie over het gebruik van Data Lake Storage Gen2.
Meld u aan bij het Azure-portaal.
Selecteer + Een resource maken in het menu aan de bovenkant.

Selecteer Analytics>Azure HDInsight om naar de pagina HDInsight-cluster maken te gaan.
Geef op het tabblad Basis de volgende gegevens op:
Vastgoed Beschrijving Abonnement Selecteer in de vervolgkeuzelijst het Azure-abonnement dat wordt gebruikt voor het cluster. Resourcegroep Selecteer in de vervolgkeuzelijst de bestaande resourcegroep of selecteer Nieuwe maken. Clusternaam Voer een wereldwijd unieke naam in. Regio Selecteer in de vervolgkeuzelijst een regio waar het cluster wordt aangemaakt. Beschikbaarheidszone Optioneel: geef een beschikbaarheidszone op waarin uw cluster moet worden geïmplementeerd Clustertype Selecteer het clustertype om een lijst te openen. Selecteer Spark-in de lijst. Clusterversie Dit veld wordt automatisch ingevuld met de standaardversie zodra het clustertype is geselecteerd. Gebruikersnaam voor clusterlogin Voer de gebruikersnaam van de clusteraanmelding in. De standaardnaam is beheerder. U gebruikt dit account om u verderop in de quickstart aan te melden bij Jupyter Notebook. Wachtwoord voor clusterinlog Voer het aanmeldingswachtwoord voor het cluster in. SSH-gebruikersnaam (Secure Shell) Voer de SSH-gebruikersnaam in. De SSH-gebruikersnaam die voor deze quickstart wordt gebruikt, is sshuser. Standaard deelt dit account hetzelfde wachtwoord als het Cluster Login gebruikersnaam account. 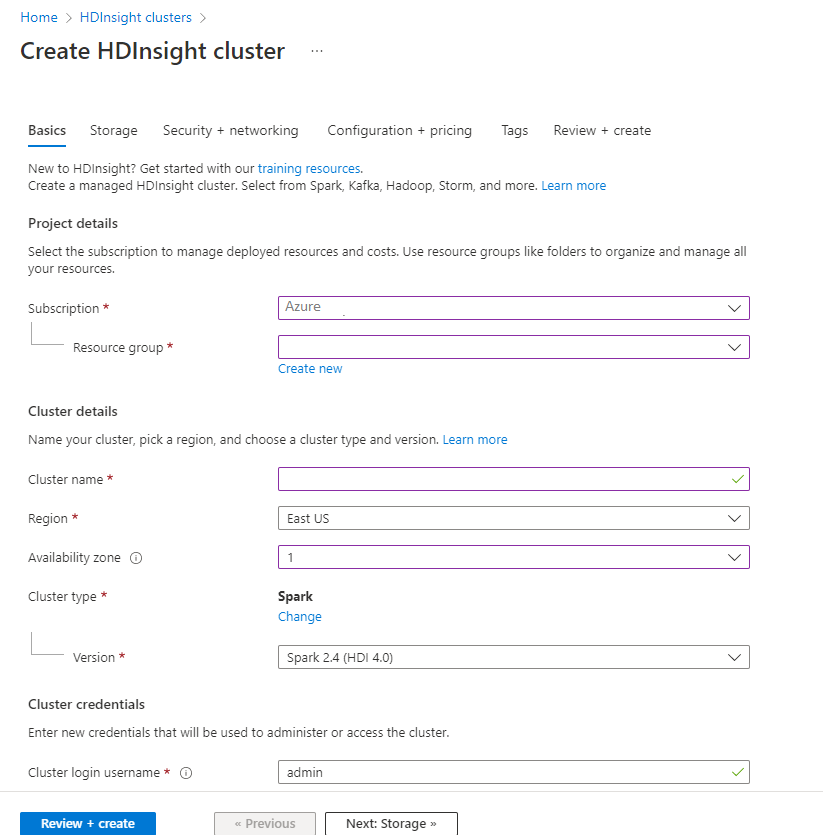
Selecteer Volgende: Opslag >> om door te gaan naar de pagina Storage.
Geef onder Opslag de volgende waarden op:
Vastgoed Beschrijving Type van primaire opslag Gebruik de standaardwaarde Azure Storage. Selectiemethode Gebruik de standaardwaarde Selecteer in lijst. Primair opslagaccount Gebruik de waarde die automatisch is ingevuld. Opslagtank Gebruik de waarde die automatisch is ingevuld. 
Selecteer Beoordelen en maken om verder te gaan.
Selecteer binnen Beoordelen en maken de optie Maken. Het duurt ongeveer 20 minuten om het cluster te maken. Het cluster moet zijn gemaakt voordat u verder kunt gaan met de volgende sessie.
Als u een probleem ondervindt met het maken van HDInsight-clusters, beschikt u mogelijk niet over de juiste machtigingen om dit te doen. Zie Vereisten voor toegangsbeheer voor meer informatie.
Een Jupyter Notebook maken
Jupyter Notebook is een interactieve notebookomgeving die ondersteuning biedt voor verschillende programmeertalen. Via het notitieblok kunt u interactie hebben met uw gegevens, code combineren met markdown-tekst en eenvoudige visualisaties uitvoeren.
Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net/jupyter, waarbijCLUSTERNAMEde naam van uw cluster is. Voer de aanmeldingsreferenties voor het cluster in als u daarom wordt gevraagd.Selecteer Nieuw>PySpark om een notebook te maken.
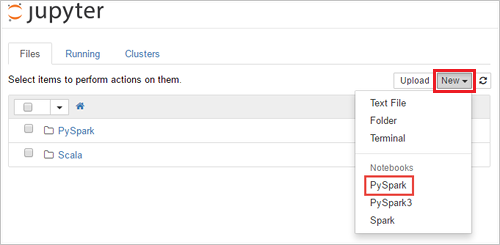
Er wordt een nieuwe notebook gemaakt en geopend met de naam Untitled (Untitled.pynb).
Apache Spark SQL-instructies uitvoeren
SQL (Structured Query Language) is de meest voorkomende en gebruikte taal voor het uitvoeren van query's en het definiëren van gegevens. Spark SQL fungeert als een uitbreiding van Apache Spark voor het verwerken van gestructureerde gegevens, met behulp van de bekende SQL-syntaxis.
Controleer of de kernel gereed is. Wanneer u een lege cirkel naast de naam van de kernel in de notebook ziet, is de kernel gereed. Een gevulde cirkel geeft aan dat de kernel bezig is.

Wanneer u de notebook voor het eerst start, voert de kernel enkele taken in de achtergrond uit. Wacht tot de kernel gereed is.
Plak de volgende code in een lege cel en druk op Shift+Enter om de code uit te voeren. Met de opdracht worden de Hive-tabellen in het cluster weergegeven:
%%sql SHOW TABLESWanneer u een Jupyter Notebook gebruikt met uw HDInsight-cluster, krijgt u een vooraf ingestelde
sqlContextdie u kunt gebruiken om Hive-query's uit te voeren met behulp van Spark SQL.%%sqlinstrueert Jupyter Notebook gebruik te maken van de vooraf ingesteldesqlContextom de Hive-query uit te voeren. De query haalt de bovenste tien rijen op uit een Hive-tabel (hivesampletable) die standaard worden meegeleverd met alle HDInsight-clusters. Het duurt ongeveer 30 seconden om de resultaten op te halen. De uitvoer ziet er als volgt uit: is quickstart."border="true":::
is quickstart."border="true":::Telkens wanneer u in Jupyter een query uitvoert, toont de venstertitel van uw webbrowser de status (Bezet) en de notebooktitel. Ook ziet u een gevulde cirkel naast de PySpark-tekst in de rechterbovenhoek.
Voer een andere query uit om de gegevens in
hivesampletablete zien.%%sql SELECT * FROM hivesampletable LIMIT 10Het scherm wordt vernieuwd om de query-uitvoer weer te geven.
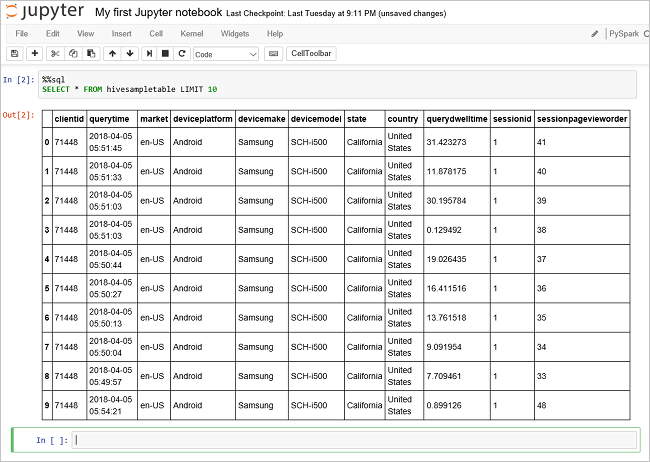 Inzicht" border="true":::
Inzicht" border="true":::Klik in het menu File van het notebook op Close and Halt. Als de notebook wordt afgesloten, komen de clusterbronnen vrij.
Hulpmiddelen opruimen
Met HDInsight worden uw gegevens opgeslagen in Azure Storage of Azure Data Lake Storage, zodat u een cluster veilig kunt verwijderen wanneer dit niet wordt gebruikt. Voor een HDInsight-cluster worden ook kosten in rekening gebracht, zelfs wanneer het niet wordt gebruikt. Aangezien de kosten voor het cluster vaak zoveel hoger zijn dan de kosten voor opslag, is het financieel gezien logischer clusters te verwijderen wanneer ze niet worden gebruikt. Als u direct verder wilt met de zelfstudie die wordt vermeld bij Volgende stappen, is het beter om het cluster te behouden.
Ga terug naar Azure Portal en selecteer Verwijderen.
 sight cluster" border="true":::
sight cluster" border="true":::
U kunt ook de naam van de resourcegroep selecteren om de pagina van de resourcegroep te openen en vervolgens Resourcegroep verwijderen selecteren. Als u de resourcegroep verwijdert, verwijdert u zowel het HDInsight-cluster als het standaardopslagaccount.
Volgende stappen
In deze snelstart hebt u geleerd hoe u een Apache Spark-cluster in HDInsight maakt en een eenvoudige Spark SQL-query uitvoert. Ga naar de volgende zelfstudie voor informatie over het gebruik van een HDInsight-cluster om interactieve query's uit te voeren op voorbeeldgegevens.