Notitie
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen u aan te melden of mappen te wijzigen.
Voor toegang tot deze pagina is autorisatie vereist. U kunt proberen om mappen te wijzigen.
In dit artikel leert u hoe u Apache Hadoop-clusters maakt in HDInsight met behulp van de Azure-portal en vervolgens Apache Hive-taken uitvoert in HDInsight. De meeste Hadoop-taken zijn batchtaken. U maakt een cluster, voert enkele taken uit en verwijdert het cluster vervolgens. In dit artikel gaat u al deze drie taken uitvoeren. Zie Clusters instellen in HDInsight voor uitgebreide uitleg over de beschikbare configuraties. Zie Clusters maken in de portal voor meer informatie over het gebruik van de portal om clusters te maken.
In deze snelstartgids gebruikt u Azure Portal voor het maken van een Hadoop-cluster in HDInsight. U kunt ook een cluster maken met behulp van een Azure Resource Manager-sjabloon.
Op dit moment wordt HDInsight geleverd met zeven verschillende clustertypen. Elk clustertype ondersteunt een andere set onderdelen. Alle clustertypen ondersteunen Hive. Zie Wat is er nieuw in de Apache Hadoop-clusterversies geleverd door HDInsight? voor een lijst met ondersteunde onderdelen in HDInsight.
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Een Apache Hadoop-cluster maken
In deze sectie maakt u een Hadoop-cluster in HDInsight met behulp van Azure Portal.
Meld u aan bij het Azure-portaal.
Selecteer + Een resource maken in het menu aan de bovenkant.
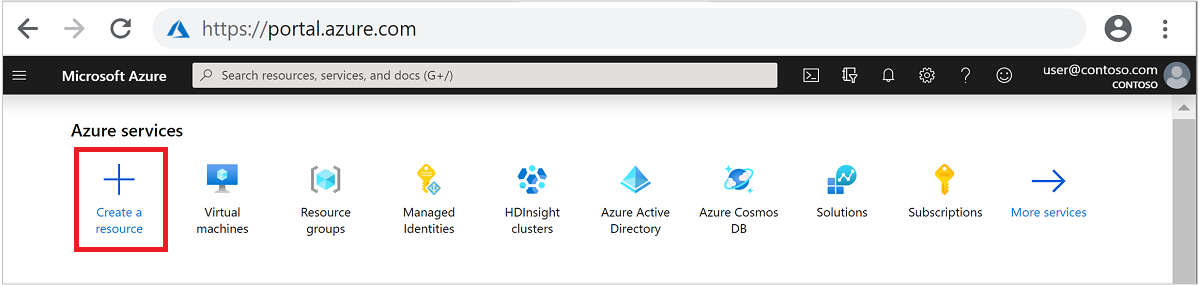
Selecteer Analytics>Azure HDInsight om naar de pagina HDInsight-cluster maken te gaan.
Geef op het tabblad Basis de volgende gegevens op:
Eigenschap Beschrijving Abonnement Selecteer in de vervolgkeuzelijst het Azure-abonnement dat wordt gebruikt voor het cluster. Resourcegroep Selecteer in de vervolgkeuzelijst de bestaande resourcegroep of selecteer Nieuwe maken. Clusternaam Voer een wereldwijd unieke naam in. De naam mag bestaan uit maximaal 59 tekens, inclusief letters, cijfers en afbreekstreepjes. De eerste en laatste tekens van de naam mogen geen streepjes zijn. Regio Selecteer in de vervolgkeuzelijst een regio waar het cluster wordt aangemaakt. Kies een locatie zo dicht mogelijk bij u in de buurt voor betere prestaties. Clustertype Selecteer Clustertype selecteren. Selecteer vervolgens Hadoop als het clustertype. Versie Selecteer een versie in de vervolgkeuzelijst. Gebruik de standaardversie als u niet weet wat u moet kiezen. Gebruikersnaam en wachtwoord voor cluster-aanmelding De standaardnaam voor aanmelden is beheerder. Het wachtwoord moet minstens 10 tekens lang zijn en moet ten minste één cijfer, één hoofdletter en één kleine letter, één niet-phanumerisch teken (behalve tekens ' ` ") bevatten. Zorg ervoor dat u geen algemene wachtwoorden opgeeft , zoals 'Pass@word1'.SSH-gebruikersnaam (Secure Shell) De standaardgebruikersnaam is sshuser. U kunt een andere naam opgeven voor de SSH-gebruikersnaam.Aanmeldingswachtwoord voor cluster gebruiken voor SSH Schakel dit selectievakje in als u hetzelfde wachtwoord voor de SSH-gebruiker wilt gebruiken als het wachtwoord dat u hebt opgegeven voor de aanmeldingsgebruiker voor het cluster. 
Selecteer Volgende: Opslag >> om naar de opslaginstellingen te gaan.
Geef op het tabblad Opslag de volgende waarden op:
Eigenschap Beschrijving Type van primaire opslag Gebruik de standaardwaarde Azure Storage. Selectiemethode Gebruik de standaardwaarde Selecteer in lijst. Primair opslagaccount Gebruik de vervolgkeuzelijst om een bestaand opslagaccount te selecteren of selecteer Nieuwe maken. Als u een nieuw account maakt, moet de naam 3 tot 24 tekens lang zijn en mag deze alleen cijfers en kleine letters bevatten Container Gebruik de waarde die automatisch is ingevuld. Aan de slag gaan met HDInsight Linux om opslagwaarden voor clusters te bieden.
Elk cluster heeft een Azure Storage-account of een
Azure Data Lake Storage Gen2afhankelijkheid. Dit wordt het standaardopslagaccount genoemd. Het HDInsight-cluster en het standaardopslagaccount moeten samen in dezelfde Azure-regio worden geplaatst. Het opslagaccount wordt niet verwijderd wanneer er clusters worden verwijderd.Selecteer het tabblad Beoordelen en maken.
Controleer op het tabblad Beoordelen en maken de waarden die u in de eerdere stappen hebt geselecteerd.
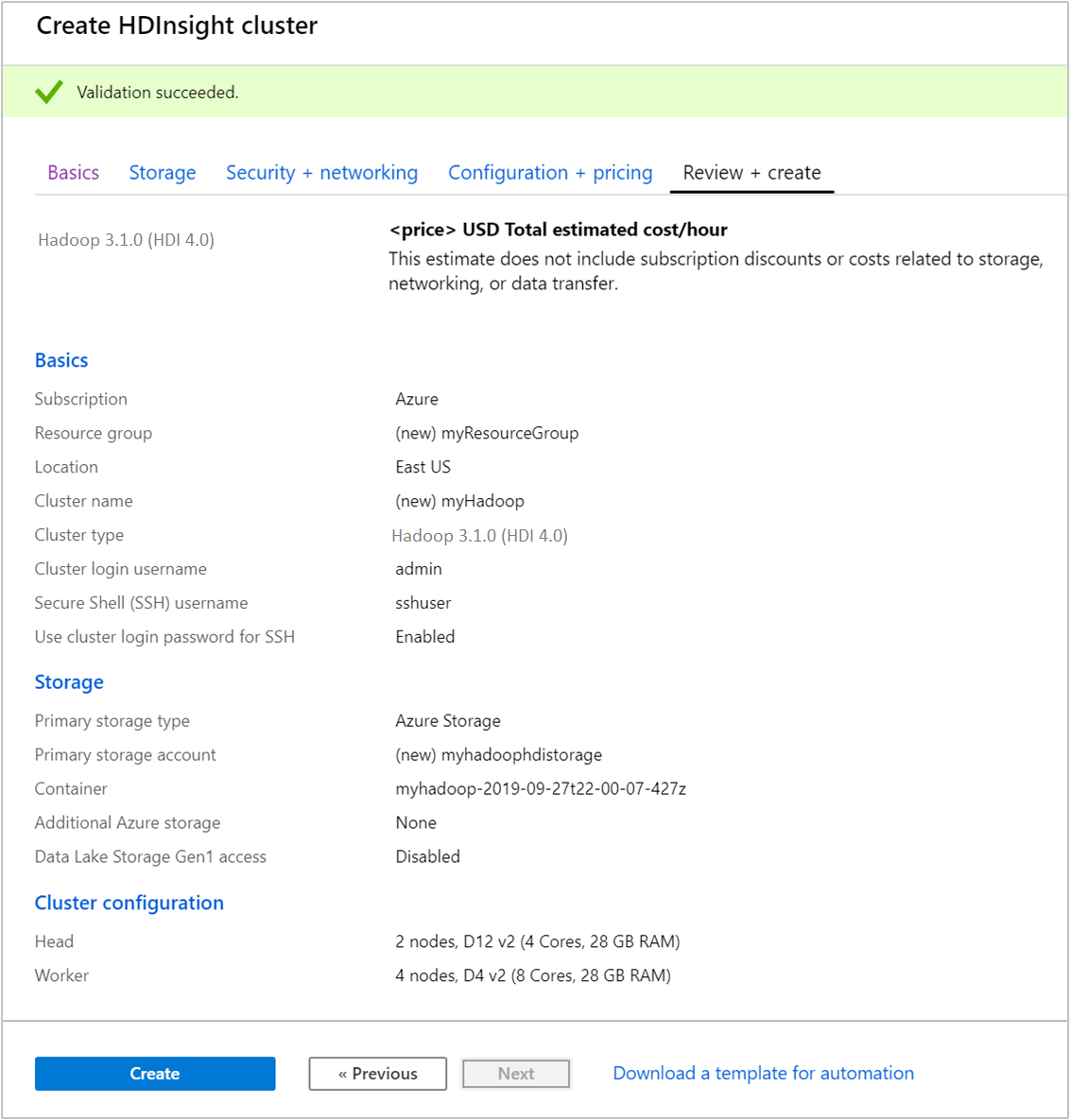
Kies Maken. Het duurt ongeveer 20 minuten om een cluster te maken.
Zodra het cluster is gemaakt, ziet u de overzichtspagina van het cluster in Azure Portal.
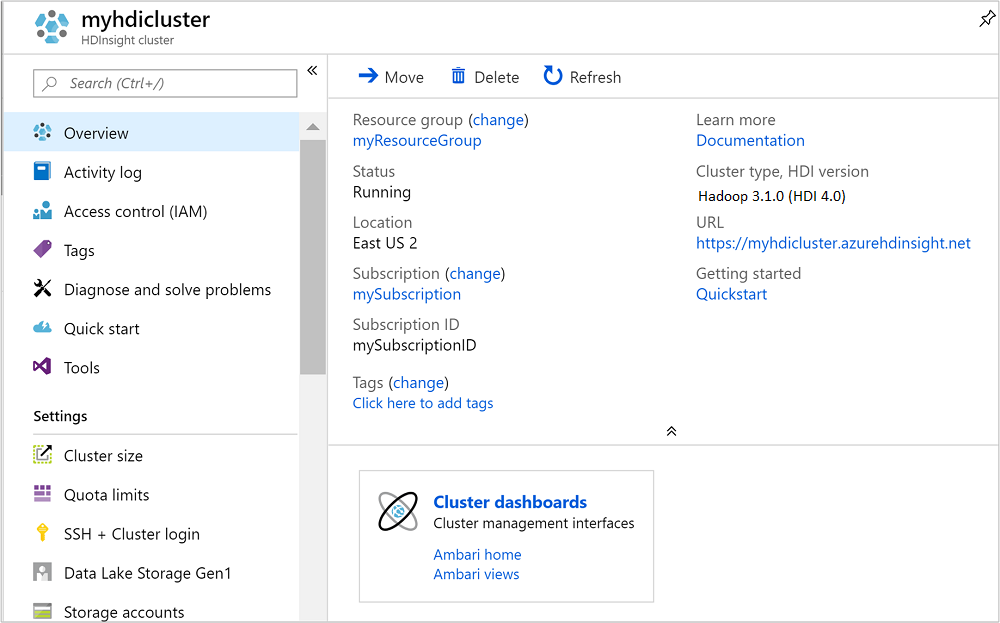
De Apache Hive-queries uitvoeren
Apache Hive is het meest populaire onderdeel dat in HDInsight wordt gebruikt. Er zijn veel manieren om Hive-taken uit te voeren in HDInsight. In deze snelstart gebruikt u de Ambari Hive-weergave via het portaal. Voor andere methoden voor het indienen van Hive-taken raadpleegt u Hive gebruiken in HDInsight.
Notitie
Apache Hive-weergave is niet beschikbaar in HDInsight 4.0.
Als u Ambari wilt openen, selecteert u Clusterdashboard in de vorige schermafbeelding. U kunt ook bladeren naar
https://ClusterName.azurehdinsight.net, waarClusterNamehet cluster is dat u in de vorige sectie hebt gemaakt.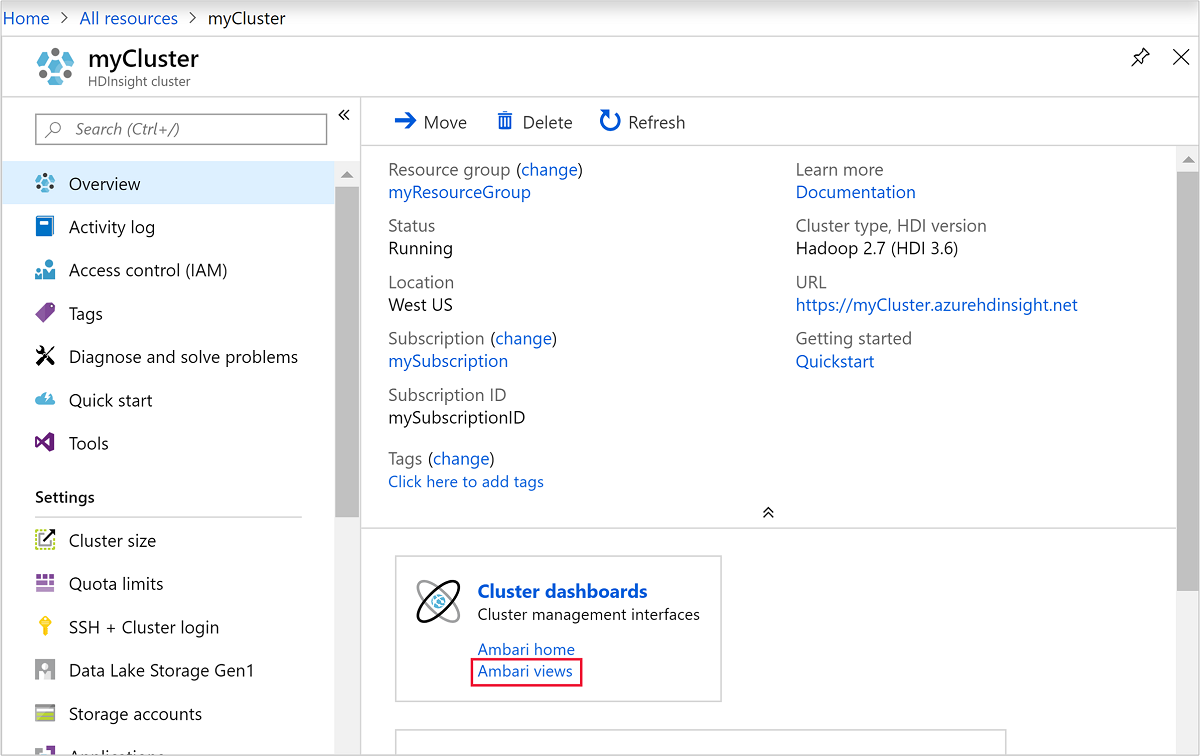
Voer de gebruikersnaam en het wachtwoord voor Hadoop in die u hebt opgegeven tijdens het maken van het cluster. De standaardgebruikersnaam is
admin.Open Hive-weergave zoals weergegeven in de volgende schermafbeelding:

Plak in het tabblad QUERY de volgende HiveQL-instructies in het werkblad:
SHOW TABLES;
Selecteer Uitvoeren. Er wordt een tabblad RESULTATEN weergegeven onder het tabblad QUERY met informatie over de taak.
Nadat de query is voltooid, worden de resultaten van de bewerking weergegeven op het tabblad QUERY. U ziet één tabel met de naam hivesampletable. Deze Hive-voorbeeldtabel is bij alle HDInsight-clusters inbegrepen.
HDInsight Apache Hive resultaten bekijken.
Herhaal stap 4 en 5 om de volgende query uit te voeren:
SELECT * FROM hivesampletable;U kunt de resultaten van de query ook opslaan. Selecteer de menuknop aan de rechterkant en geef aan of u de resultaten wilt downloaden als een CSV-bestand of deze wilt opslaan in het opslagaccount dat aan het cluster is gekoppeld.

Nadat u een Hive-taak hebt voltooid, kunt u de resultaten exporteren naar een Azure SQL Database- of SQL Server-database. U kunt ook de resultaten weergeven in Excel. Zie Apache Hive en HiveQL gebruiken met Apache Hadoop in HDInsight voor het analyseren van een Apache Log4j-voorbeeldbestand voor meer informatie over het gebruik van Hive in HDInsight.
Middelen opschonen
Nadat u de quickstart hebt voltooid, kunt u het cluster verwijderen. Met HDInsight worden uw gegevens opgeslagen in Azure Storage zodat u een cluster veilig kunt verwijderen wanneer deze niet wordt gebruikt. Voor een HDInsight-cluster worden ook kosten in rekening gebracht, zelfs wanneer het niet wordt gebruikt. Aangezien de kosten voor het cluster vaak zoveel hoger zijn dan de kosten voor opslag, is het financieel gezien logischer clusters te verwijderen wanneer ze niet worden gebruikt.
Notitie
Als u meteen verder wilt gaan met het volgende artikel om te leren hoe u ETL-bewerkingen uitvoert met behulp van Hadoop in HDInsight, kunt u het cluster beter behouden. In de zelfstudie moet u namelijk opnieuw een Hadoop-cluster aanmaken. Als u echter niet direct verdergaat met het volgende artikel, moet u het cluster nu verwijderen.
Het cluster en/of het standaardopslagaccount verwijderen
Ga terug naar het browsertabblad voor Azure Portal. U komt terecht op de overzichtspagina voor het cluster. Selecteer Verwijderen als u alleen het cluster wilt verwijderen maar het standaardopslagaccount wilt behouden.

Als u het cluster en het standaardopslagaccount wilt verwijderen, selecteert u de naam van de resourcegroep (gemarkeerd in de vorige schermopname) om de pagina resourcegroep te openen.
Selecteer Resourcegroep verwijderen om de resourcegroep te verwijderen. De groep bevat zowel het cluster als het standaardopslagaccount. Als u de resourcegroep verwijdert, wordt ook het opslagaccount verwijderd. Als u het opslagaccount wilt behouden, verwijdert u alleen het cluster.
Volgende stappen
In deze quickstart hebt u geleerd hoe u een HDInsight-cluster op basis van Linux maakt met behulp van een Resource Manager-sjabloon, en hoe u eenvoudige Hive-query's uitvoert. In het volgende artikel leert u hoe u een ETL-bewerking (Extraction, Transformation, Loading) uitvoert met behulp van Hadoop in HDInsight.