Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ![]() SQL Server
SQL Server
This article describes how to perform a forced failover (with possible data loss) on an Always On availability group by using SQL Server Management Studio, Transact-SQL, or PowerShell in SQL Server. A forced failover is a form of manual failover that is intended strictly for disaster recovery, when a planned manual failover isn't possible. If you force failover to an unsynchronized secondary replica, some data loss is possible. Therefore, we strongly recommend that you force failover only if you must restore service to the availability group immediately and you're willing to risk losing data.
After a forced failover, the failover target to which the availability group was failed over becomes the new primary replica. The secondary databases in the remaining secondary replicas are suspended and must be manually resumed. When the former primary replica becomes available, it transitions to the secondary role, causing the former primary databases to become secondary databases and transition into the SUSPENDED state. Before you resume a given secondary database, you might be able to recover lost data from it. However, notice that transaction log truncation is delayed on a given primary database while any of its secondary databases is suspended.
Important
Data synchronization with the primary database doesn't occur until the secondary database is resumed. For information about resuming a secondary database, see Follow Up: Essential Tasks After a Forced Failover later in this article.
Performing a forced failover is necessary in the following emergency situations:
After forcing quorum on the WSFC cluster (forced quorum), you need to force failover each availability group (with possible data loss). Forcing failover is required because the real state of the WSFC cluster values might have been lost. However, you can avoid data loss, if you are able to force failover on the server instance that was hosting the replica that was the primary replica before you forced quorum or to a secondary replica that was synchronized before you forced quorum. For more information, see Potential Ways to Avoid Data Loss After Quorum is Forced, later in this article.
Important
If quorum is regained by natural means instead of being forced, the availability replicas go through normal recovery. If the primary replica is still unavailable after quorum is regained, you can perform a planned manual failover to a synchronized secondary replica.
For information about forcing quorum, see WSFC Disaster Recovery through Forced Quorum (SQL Server). For information about why forcing failover is required after forcing quorum, see Failover and Failover Modes (Always On Availability Groups).
If the primary replica becomes unavailable when the WSFC cluster has a healthy quorum, you can force failover (with possible data loss), to any replica whose role is in the
SECONDARYorRESOLVINGstate. If possible, force failover to a synchronous-commit secondary replica that was synchronized when the primary replica was lost.Tip
When the WSFC cluster has a healthy quorum, if you issue a force failover command on a synchronized secondary replica, the replica actually performs a planned manual failover.
For more information about the prerequisites and recommendations for forcing failover and for an example scenario that uses a forced failover to recover from a catastrophic failure, see Example scenario: Use a forced failover to recover from a catastrophic failure, later in this article.
Limitations
The only time that you can't perform a forced failover is when Windows Server Failover Clustering (WSFC) cluster lacks quorum.
Data loss is possible during the forced failover of an availability group. In addition, if the primary replica is running when you initiate a forced failover, clients might still be connected to former primary databases. Therefore, we strongly recommend that you force failover only if the primary replica is no longer running and if you're willing to risk losing data in order to restore access to databases in the availability group.
When a secondary database is in the
REVERTINGorINITIALIZINGstate, forcing failover would cause the database to fail to start as a primary database. If the database was in theINITIALIZINGstate then you need to apply the missing log records from a database backup or fully restore the database from scratch. If the database was in theREVERTINGstate you need to fully restore the database from backups.A failover command returns as soon as the failover target has accepted the command. However, database recovery occurs asynchronously after the availability group has finished failing over.
Cross-database consistency across databases within the availability group might not be maintained on failover.
Note
Support for cross-database and distributed transactions vary by SQL Server and operating system versions. For more information, see Transactions - availability groups and database mirroring.
Prerequisites
The WSFC cluster has quorum. If the cluster lacks quorum, see WSFC Disaster Recovery through Forced Quorum (SQL Server).
You must be able to connect to a server instance that hosts a replica whose role is in the
SECONDARYorRESOLVINGstate.
Recommendations
Don't force failover while the primary replica is still running.
If possible, force failover only to a failover target whose secondary databases are either in the
NOT SYNCHRONIZED,SYNCHRONIZED, orSYNCHRONIZINGstate. For information about the implications of forcing failover when a secondary database is in theINITIALIZINGorREVERTINGstate, see Limitations earlier in this article.Typically, the latency of a given secondary database, relative to the primary database, should be similar on different asynchronous-commit secondary replicas. However, when forcing failover, data loss can be a significant concern. Therefore, consider taking time to determine the relative latency of the copies of the databases on different secondary replicas. To determine which copy of a given secondary database has the least latency, compare their end-of-log LSNs. A higher the end-of-log LSN indicates less latency.
Tip
To compare end-of-log LSNs, connect to each online secondary replica, in turn, and query sys.dm_hadr_database_replica_states for the
end_of_log_lsnvalue of each local secondary database. Then, compare the end-of-log LSNs of the different copies of each database. Different databases might have their highest LSNs on different secondary replicas. In this case, the most appropriate failover target depends on the relative importance that you place on the data in the different databases. That is, for which of these databases would you most want to minimize possible data loss?If clients are able to connect to the original primary, a forced failover incurs some risk of split brain behavior. Before you force failover, we strongly recommend that you prevent clients from accessing the original primary replica. Otherwise, after failover is forced, the original primary databases and the current primary databases could be updated independently of the other.
Potential ways to avoid data loss after quorum is forced
Under some failure conditions after quorum is lost, you can prevent data loss as follows:
If the original primary replica comes online
If quorum is lost and forcing WSFC quorum restores the cluster node that hosts the primary replica of an availability group, you can prevent data loss for this availability group. Connect to the primary replica and perform a forced failover (FAILOVER_ALLOW_DATA_LOSS). This brings the primary replica back online. Because you perform the forced failover to the original primary replica, there's no data loss.
If a synchronized synchronous-commit secondary replica comes online
If quorum is lost and forcing WSFC quorum restores a cluster node that hosts a synchronized secondary replica for an availability group, you should be able to prevent data loss for this availability group. If the restored node was up at the time that quorum was lost, you can determine whether data loss could occur on a given database by querying the
is_failover_readycolumn of the sys.dm_hadr_database_replica_cluster_states dynamic management view. For example, for a server instance namedsql108w2k8r22, issue the following query:SELECT * FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id = ( SELECT replica_id FROM sys.availability_replicas WHERE replica_server_name = 'sql108w2k8r22' );Caution
If the restored node wasn't up at the time quorum was lost,
is_failover_readymight not reflect the cluster's actual state at the time the primary replica went offline. Therefore, theis_failover_readyvalue is only good if the host node at the time of the failure. For more information, see "Why Forced Failover is Required After Forcing Quorum" in Failover and Failover Modes (Always On Availability Groups).If
is_failover_ready = 1, the database is marked as synchronized in the cluster and is ready for a failover. Ifis_failover_ready = 1on every database on a given secondary replica, you can perform a forced failover (FORCE_FAILOVER_ALLOW_DATA_LOSS) without data loss on this secondary replica. The synchronized secondary replica comes online in the primary role, that is, as the new primary replica, with all the data intact.If
is_failover_ready = 0, the database isn't marked as synchronized in the cluster and isn't ready for a planned manual failover. If you force failover to the host secondary replica, data is lost on this database.Note
When you force failover to a secondary replica, the amount of data loss depends on how far the failover target is lagging behind the primary replica. Unfortunately, when the WSFC cluster lacks quorum or quorum has been forced, you can't assess the amount of potential data loss. Note, however, that once the WSFC cluster regains a healthy quorum, you could begin to track potential data loss. For more information, see "Tracking Potential Data Loss" in Failover and Failover Modes (Always On Availability Groups).
Permissions
Requires ALTER AVAILABILITY GROUP permission on the availability group, CONTROL AVAILABILITY GROUP permission, ALTER ANY AVAILABILITY GROUP permission, or CONTROL SERVER permission.
Use SQL Server Management Studio
In Object Explorer, connect to a server instance that hosts a replica whose role is in the
SECONDARYorRESOLVINGstate in the availability group that needs to be failed over, and expand the server tree.Expand the Always On High Availability node and the Availability Groups node.
Right-click the availability group to be failed over, and select the Failover command.
This launches the Failover Availability Group Wizard. For more information, see Use the Fail Over Availability Group Wizard (SQL Server Management Studio).
After forcing an availability group to fail over, complete the necessary follow-up steps. For more information, see Follow Up: Essential Tasks After a Forced Failover, later in this article.
Use Transact-SQL
Connect to a server instance that hosts a replica whose role is in the
SECONDARYorRESOLVINGstate in the availability group that needs to be failed over.Use the ALTER AVAILABILITY GROUP statement, as follows, where group_name is the name of the availability group:
ALTER AVAILABILITY GROUP <group_name> FORCE_FAILOVER_ALLOW_DATA_LOSS.The following example forces the
AccountsAGavailability group to fail over to the local secondary replica.ALTER AVAILABILITY GROUP AccountsAG FORCE_FAILOVER_ALLOW_DATA_LOSS;After forcing an availability group to fail over, complete the necessary follow-up steps. For more information, see Essential tasks after a forced failover, later in this article.
Use PowerShell
Change directory (
cd) to a server instance that hosts a replica whose role is in theSECONDARYorRESOLVINGstate in the availability group that needs to be failed over.Use the
Switch-SqlAvailabilityGroupcmdlet with theAllowDataLossparameter in one of the following forms:-AllowDataLossBy default
-AllowDataLossparameter causesSwitch-SqlAvailabilityGroupto prompt you to remind you that forcing failover might result in the loss of uncommitted transactions and to request confirmation. To continue, enterY; to cancel the operation, enterN.The following example performs a forced failover (with possible data loss) of the availability group
MyAgto the secondary replica on the server instance namedSecondaryServer\InstanceName. You're prompted to confirm this operation.Switch-SqlAvailabilityGroup ` -Path SQLSERVER:\Sql\SecondaryServer\InstanceName\AvailabilityGroups\MyAg ` -AllowDataLoss-AllowDataLoss-ForceTo initiate a forced failover without confirmation, specify both the
-AllowDataLossand-Forceparameters. This is useful if you want to include the command in a script and run it without user interaction. However, use the-Forceoption with caution, because a forced failover might result in the loss of data from databases participating the availability group.The following example performs a forced failover (with possible data loss) of the availability group
MyAgto the server instance namedSecondaryServer\InstanceName. The-Forceoption suppresses confirmation of this operation.Switch-SqlAvailabilityGroup ` -Path SQLSERVER:\Sql\SecondaryServer\InstanceName\AvailabilityGroups\MyAg ` -AllowDataLoss -Force
Note
To view the syntax of a cmdlet, use the
Get-Helpcmdlet in the SQL Server PowerShell environment. For more information, see Get Help SQL Server PowerShell.After forcing an availability group to fail over, complete the necessary follow-up steps. For more information, see Follow Up: Essential Tasks After a Forced Failover, later in this article.
Set up and use the SQL Server PowerShell provider
Follow Up: Essential tasks after a forced failover
After a forced failover, the secondary replica to which you failed over becomes the new primary replica. However, to make that availability replica accessible to clients, you might need to reconfigure the WSFC quorum or adjust the availability-mode configuration of the availability group, as follows:
If you failed over outside of the automatic failover set: Adjust the quorum votes of the WSFC nodes to reflect your new availability group configuration. If the WSFC node that hosts the target secondary replica doesn't have a WSFC quorum vote, you might need to force WSFC quorum.
An automatic failover set exists only if two availability replicas (including the previous primary replica) are configured for synchronous-commit mode with automatic failover.
To adjust quorum votes
If you failed over outside of the synchronous-commit failover set: We recommend that you consider adjusting the availability mode and failover mode on the new primary replica and on remaining secondary replicas to reflect your desired synchronous-commit and automatic failover configuration.
Note
A synchronous-commit failover set exists only if the current primary replica is configured for synchronous-commit mode.
To change the availability mode and failover mode
After a forced failover, all secondary databases are suspended. This includes the former primary databases, after the former primary replica comes back online and discovers that it's now a secondary replica. You must manually resume each suspended database individually on each secondary replica.
When a secondary database is resumed, it initiates data synchronization with the corresponding primary database. The secondary database rolls back any log records that were never committed on the new primary database. Therefore, if you're concerned about possible data loss on the post-failover primary databases, you should attempt to create a database snapshot on the suspended databases on one of the synchronous-commit secondary databases.
Important
Transaction log truncation is delayed on a primary database while any of its secondary databases is suspended. Also the synchronization health of a synchronous-commit secondary replica can't transition to
HEALTHYas long as any local database remains suspended.To create a database snapshot
To resume an availability database
Caution
After resuming all the secondary databases, before attempting to fail over the group again, wait for every secondary database on the next failover target to enter the
SYNCHRONIZINGstate. If any database isn't yetSYNCHRONIZING, that database is prevented from coming online as a primary database, and re-establishing data synchronization for the database might require restoring transaction logs, restoring a full database backup, or failing over back to the previous primary replica.If an availability replica that failed isn't returning to the availability replica or might return too late for you to delay transaction log truncation on the new primary database, consider removing the failed replica from the availability group to avoid running out of disk space for your log files.
To remove a secondary replica
If you follow a forced failover with one or more additional forced failovers, perform a log backup after each additional forced failover in the series. For information about the reason for this, see "Risks of Forcing Failover" in the "Forced Manual Failover (with Possible Data Loss)" section of Failover and Failover Modes (Always On Availability Groups).
To perform a log backup
Example scenario: Use a forced failover to recover from a catastrophic failure
If the primary replica fails and no synchronized secondary replica is available, forcing the availability group to fail over might be an appropriate response. The appropriateness of forcing a failover depends on: (1) whether you expect the primary replica to be offline for longer than your service level agreement (SLA) tolerates, and (2) whether you're willing to risk potential data loss in order to make primary databases available quickly. If you decide that an availability group requires a forced failover, the actual forced failover is but one step of a multi-step process.
To illustrate the steps that are required to use a forced failover to recover from a catastrophic failure, this article presents one possible disaster recovery scenario. The example scenario considers an availability group whose original topology consists of a main data center that hosts three synchronous-commit availability replicas, including the primary replica, and a remote data center that hosts two asynchronous-commit secondary replicas. The following figure illustrates the original topology of this example availability group. The availability group is hosted by a multi-subnet WSFC cluster with three nodes in the main data center (Node 01, Node 02, and Node 03) and two nodes in a remote data center (Node 04 and Node 05).

The main data center shuts down unexpectedly. Its three availability replicas to go offline, and their databases become unavailable. The following figure illustrates the effect of this failure on the topology of the availability group.

The database administrator (DBA) determines that the best possible response is to force failover of the availability group to one of the remote, asynchronous-commit secondary replicas. This example illustrates the typical steps involved when you force failover of the availability group to a remote replica and, eventually, return the availability group to its original topology.
The failure-response presented here consists of the following two phases:
- Respond to the catastrophic failure of the main data center
- Return the availability group to its original topology
Respond to the catastrophic failure of the main data center
The following figure illustrates the series of actions performed at the remote data center in response a catastrophic failure at the main data center.
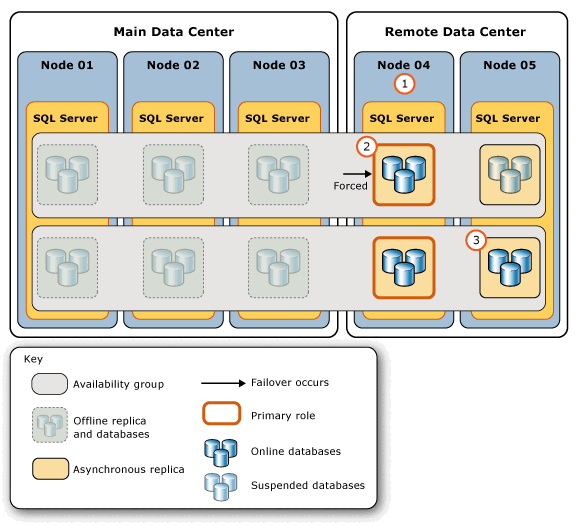
The steps in this figure indicate the following steps:
| Step | Action | Links |
|---|---|---|
1. |
The DBA or network administrator ensures that the WSFC cluster has a healthy quorum. In this example, quorum needs to be forced. | WSFC Quorum Modes and Voting Configuration (SQL Server) WSFC Disaster Recovery through Forced Quorum (SQL Server) |
2. |
The DBA connects to the server instance with the least latency (on Node 04) and performs a forced manual failover. The forced failover transitions this secondary replica to the primary role and suspends the secondary databases on the remaining secondary replica (on Node 05). | sys.dm_hadr_database_replica_states (Query the end_of_log_lsn column. For more information, see Recommendations, earlier in this article.) |
3. |
The DBA manually resumes each of the secondary databases on the remaining secondary replica. | Resume an Availability Database (SQL Server) |
Return the availability group to its original topology
The following figure illustrates the series of actions that return the availability group to its original topology after the main data center comes back online and the WSFC nodes re-establish communication with the WSFC cluster.
Important
If the WSFC cluster quorum has been forced, as the offline nodes restart they could form a new quorum if the following conditions both exist: (a) there's no network connectivity between any of the nodes in the forced-quorum set, and (b) the restarting nodes are the majority of the cluster nodes. This would result in a "split brain" condition in which the availability group would possess two independent primary replicas, one at each data center. Before forcing quorum to create a minority quorum set, see WSFC Disaster Recovery through Forced Quorum (SQL Server).

The steps in this figure indicate the following steps:
| Step | Action | Links |
|---|---|---|
1. |
The nodes in the main data center come back online and re-establish communication with the WSFC cluster. Their availability replicas come online as secondary replicas with suspended databases, and the DBA needs to manually resume each of these databases soon. | Resume an Availability Database (SQL Server) Tip: If you're concerned about possible data loss on the post-failover primary databases, you should attempt to create a database snapshot on the suspended databases on one the synchronous-commit secondary database. Keep in mind that the transaction log truncation is delayed on a primary database while any of its secondary databases is suspended. Also the synchronization health of the synchronous-commit secondary replica can't transition to HEALTHY as long as any local database remains suspended. |
2. |
Once the databases are resumed, the DBA changes the new primary replica to synchronous-commit mode temporarily. This involves two steps: 1. Change one offline availability replica to asynchronous-commit mode. 2. Change the new primary replica to synchronous-commit mode. Note: This step enables resumed synchronous-commit secondary databases to become SYNCHRONIZED. |
Change availability mode of a replica within an Always On availability group |
3. |
Once the synchronous-commit secondary replica on Node 03 (the original primary replica) enters the HEALTHY synchronization state, the DBA performs a planned manual failover to that replica, to make it the primary replica again. The replica on Node 04 returns to being a secondary replica. |
sys.dm_hadr_database_replica_states Use Always On Policies to View the Health of an Availability Group (SQL Server) Perform a planned manual failover of an Always On availability group (SQL Server) |
4. |
The DBA connects to the new primary replica and: 1. Changes the former primary replica (in the remote center) back to asynchronous-commit mode. 2. Changes the asynchronous-commit secondary replica in the main data center back to synchronous-commit mode. |
Change availability mode of a replica within an Always On availability group |
Related tasks
Adjust quorum votes
- View Cluster Quorum NodeWeight Settings
- Configure Cluster Quorum NodeWeight Settings
- Force a WSFC Cluster to Start Without a Quorum
Planned manual failover
- Perform a planned manual failover of an Always On availability group (SQL Server)
- Use the Fail Over Availability Group Wizard (SQL Server Management Studio)
Troubleshoot
- Troubleshoot Always On Availability Groups Configuration (SQL Server)
- Troubleshoot a Failed Add-File Operation (Always On Availability Groups)
Related content
- SQL Server Always On Team Blogs: The official SQL Server Always On Team Blog
- CSS SQL Server Engineers Blogs
- Microsoft SQL Server Always On Solutions Guide for High Availability and Disaster Recovery
- What is an Always On availability group?
- Differences between availability modes for an Always On availability group
- Failover and Failover Modes (Always On Availability Groups)
- Types of client connections to replicas within an Always On availability group
- Tools to monitor Always On availability groups
- Windows Server Failover Clustering with SQL Server