Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this tutorial, you build on work by a Power BI analyst that's stored as semantic models (Power BI datasets). By using SemPy (preview) in the Synapse Data Science experience in Microsoft Fabric, you analyze functional dependencies in DataFrame columns. This analysis helps you discover subtle data quality issues to get more accurate insights.
In this tutorial, you learn how to:
- Apply domain knowledge to formulate hypotheses about functional dependencies in a semantic model.
- Get familiar with components of Semantic Link's Python library (SemPy) that integrate with Power BI and help automate data quality analysis. These components include:
- FabricDataFrame—pandas-like structure enhanced with additional semantic information
- Functions that pull semantic models from a Fabric workspace into your notebook
- Functions that evaluate functional dependency hypotheses and identify relationship violations in your semantic models
Prerequisites
Get a Microsoft Fabric subscription. Or, sign up for a free Microsoft Fabric trial.
Sign in to Microsoft Fabric.
Use the experience switcher on the bottom left side of your home page to switch to Fabric.
Select Workspaces from the navigation pane to find and select your workspace. This workspace becomes your current workspace.
Download the Customer Profitability Sample.pbix file from the fabric-samples GitHub repository.
In your workspace, select Import > Report or Paginated Report > From this computer to upload the Customer Profitability Sample.pbix file to your workspace.
Follow along in the notebook
The powerbi_dependencies_tutorial.ipynb notebook accompanies this tutorial.
To open the accompanying notebook for this tutorial, follow the instructions in Prepare your system for data science tutorials to import the notebook to your workspace.
If you'd rather copy and paste the code from this page, you can create a new notebook.
Be sure to attach a lakehouse to the notebook before you start running code.
Set up the notebook
Set up a notebook environment with the modules and data you need.
Use
%pipto install SemPy from PyPI in the notebook.%pip install semantic-linkImport the modules you need.
import sempy.fabric as fabric from sempy.dependencies import plot_dependency_metadata
Load and preprocess the data
This tutorial uses a standard sample semantic model Customer Profitability Sample.pbix. For a description of the semantic model, see Customer Profitability sample for Power BI.
Load Power BI data into a
FabricDataFrameby using thefabric.read_tablefunction.dataset = "Customer Profitability Sample" customer = fabric.read_table(dataset, "Customer") customer.head()Load the
Statetable into aFabricDataFrame.state = fabric.read_table(dataset, "State") state.head()Although the output looks like a pandas DataFrame, this code initializes a data structure called a
FabricDataFramethat adds operations on top of pandas.Check the data type of
customer.type(customer)The output shows that
customerissempy.fabric._dataframe._fabric_dataframe.FabricDataFrame.Join the
customerandstateDataFrameobjects.customer_state_df = customer.merge(state, left_on="State", right_on="StateCode", how='left') customer_state_df.head()
Identify functional dependencies
A functional dependency is a one-to-many relationship between values in two or more columns in a DataFrame. Use these relationships to automatically detect data quality problems.
Run SemPy's
find_dependenciesfunction on the mergedDataFrameto identify functional dependencies between column values.dependencies = customer_state_df.find_dependencies() dependenciesVisualize the dependencies by using SemPy's
plot_dependency_metadatafunction.plot_dependency_metadata(dependencies)
The functional dependencies graph shows that the
Customercolumn determines columns likeCity,Postal Code, andName.The graph doesn't show a functional dependency between
CityandPostal Code, likely because there are many violations in the relationship between the columns. Use SemPy'splot_dependency_violationsfunction to visualize dependency violations between specific columns.

Explore the data for quality issues
Draw a graph with SemPy's
plot_dependency_violationsvisualization function.customer_state_df.plot_dependency_violations('Postal Code', 'City')
The plot of dependency violations shows values for
Postal Codeon the left side, and values forCityon the right side. An edge connects aPostal Codeon the left hand side with aCityon the right hand side if there's a row that contains these two values. The edges are annotated with the count of such rows. For example, there are two rows with postal code 20004, one with city "North Tower" and the other with city "Washington".The plot also shows a few violations and many empty values.
Confirm the number of empty values for
Postal Code:customer_state_df['Postal Code'].isna().sum()50 rows have NA for
Postal Code.Drop rows with empty values. Then, find dependencies using the
find_dependenciesfunction. Notice the extra parameterverbose=1that offers a glimpse into the internal workings of SemPy:customer_state_df2=customer_state_df.dropna() customer_state_df2.find_dependencies(verbose=1)The conditional entropy for
Postal CodeandCityis 0.049. This value indicates that there are functional dependency violations. Before you fix the violations, raise the threshold on conditional entropy from the default value of0.01to0.05, just to see the dependencies. Lower thresholds result in fewer dependencies (or higher selectivity).Raise the threshold on conditional entropy from the default value of
0.01to0.05:plot_dependency_metadata(customer_state_df2.find_dependencies(threshold=0.05))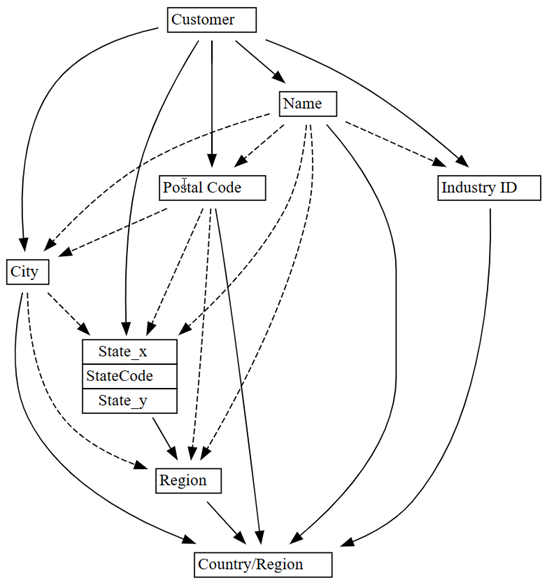
If you apply domain knowledge of which entity determines the values of other entities, this dependency graph seems accurate.
Explore more data quality issues that were detected. For example, a dashed arrow joins
CityandRegion, which indicates that the dependency is only approximate. This approximate relationship could imply that there's a partial functional dependency.customer_state_df.list_dependency_violations('City', 'Region')Take a closer look at each of the cases where a nonempty
Regionvalue causes a violation:customer_state_df[customer_state_df.City=='Downers Grove']The result shows the city of Downers Grove in Illinois and Nebraska. However, Downers Grove is a city in Illinois, not Nebraska.
Take a look at the city of Fremont:
customer_state_df[customer_state_df.City=='Fremont']There's a city called Fremont in California. However, for Texas, the search engine returns Premont, not Fremont.
It's also suspicious to see violations of the dependency between
NameandCountry/Region, as signified by the dotted line in the original graph of dependency violations (before dropping the rows with empty values).customer_state_df.list_dependency_violations('Name', 'Country/Region')One customer, SDI Design, appears in two regions—United States and Canada. This case might not be a semantic violation, just uncommon. Still, it's worth a close look:
Take a closer look at the customer SDI Design:
customer_state_df[customer_state_df.Name=='SDI Design']Further inspection shows two different customers from different industries with the same name.

Exploratory data analysis and data cleaning are iterative. What you find depends on your questions and perspective. Semantic Link gives you new tools to get more from your data.
Related content
Check out other tutorials for semantic link and SemPy:
- Tutorial: Clean data with functional dependencies
- Tutorial: Extract and calculate Power BI measures from a Jupyter notebook
- Tutorial: Discover relationships in a semantic model, using semantic link
- Tutorial: Discover relationships in the Synthea dataset, using semantic link
- Tutorial: Validate data using SemPy and Great Expectations (GX)