Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
If you already have an AI project in Azure AI Foundry, the model catalog deploys models from partner model providers as stand-alone endpoints in your project by default. Each model deployment has its own set of URI and credentials to access it. On the other hand, Azure OpenAI models are deployed to the Azure AI Foundry resource or to the Azure OpenAI in Azure AI Foundry Models resource.
You can change this behavior and deploy both types of models to Azure AI Foundry (formerly known Azure AI Services). Once configured, deployments of models as serverless API deployments happen to the connected Azure AI Foundry resource instead to the project itself, giving you a single set of endpoint and credentials to access all the models deployed in Azure AI Foundry. You can manage models from Azure OpenAI and partner model providers in the same way.
Additionally, deploying models to Azure AI Foundry Models brings the extra benefits of:
- Routing capability
- Custom content filters
- Global capacity deployment type
- Key-less authentication with Microsoft Entra ID
In this article, you learn how to configure your project to use Foundry Models deployments.
Prerequisites
To complete this tutorial, you need:
An Azure subscription. If you're using GitHub Models, you can upgrade your experience and create an Azure subscription in the process. To learn more, see Upgrade from GitHub Models to Foundry Models.
An Azure AI Foundry resource. For more information, see Create your first AI Foundry resource.
An Azure AI Foundry project and hub. For more information, see How to create and manage an Azure AI Foundry hub.
Tip
When your AI hub is provisioned, an Azure AI Foundry resource is created with it and the two resources are connected. To see which resource is connected to your project, go to the Azure AI Foundry portal > Management center > Connected resources, and find the connections of type AI Services.
Configure the project to use Foundry Models
To configure the project to use the Foundry Models capability in Azure AI Foundry, follow these steps:
In the landing page of your project, select Management center at the bottom of the sidebar menu. Identify the Azure AI Foundry resource connected to your project.
If no resource is listed, your AI hub doesn't have an Azure AI Foundry resource connected to it. Create a new connection.
Select +New connection, then choose Azure AI foundry from the tiles.
In the window, look for an existing resource in your subscription and then select Add connection.
The new connection is added to your hub.
Return to the project's landing page.
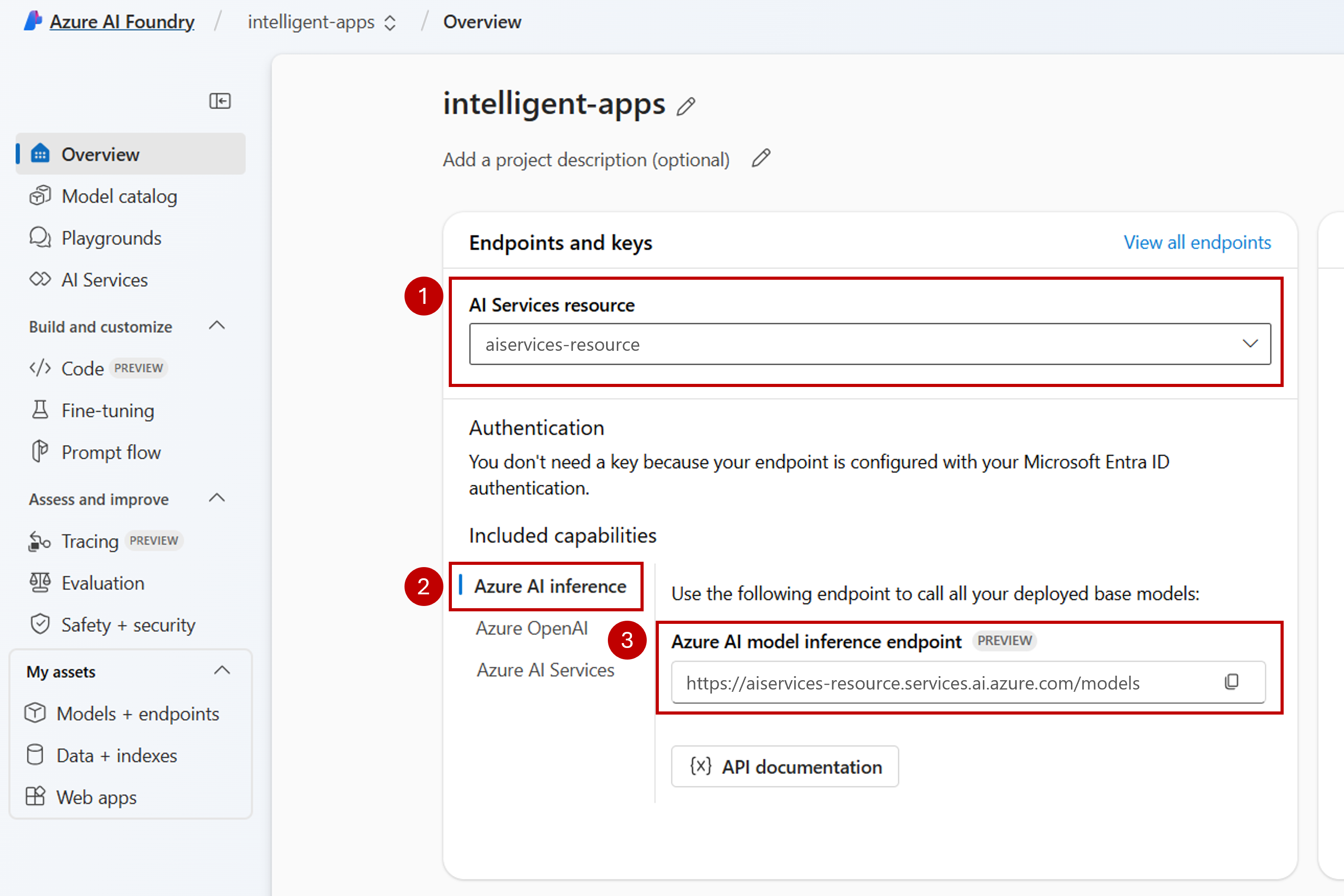
Under Included capabilities, ensure you select Azure AI Inference. The Foundry Models endpoint URI is displayed along with the credentials to get access to it.
Tip
Each Azure AI Foundry resource has a single Foundry Models endpoint that can be used to access any model deployment on it. The same endpoint serves multiple models depending on which ones are configured. To learn how the endpoint works, see Azure OpenAI inference endpoint.
Take note of the endpoint URL and credentials.

Create the model deployment in Foundry Models
For each model you want to deploy under Foundry Models, follow these steps:
Go to the Model catalog in Azure AI Foundry portal.
Scroll to the model you're interested in and select it.
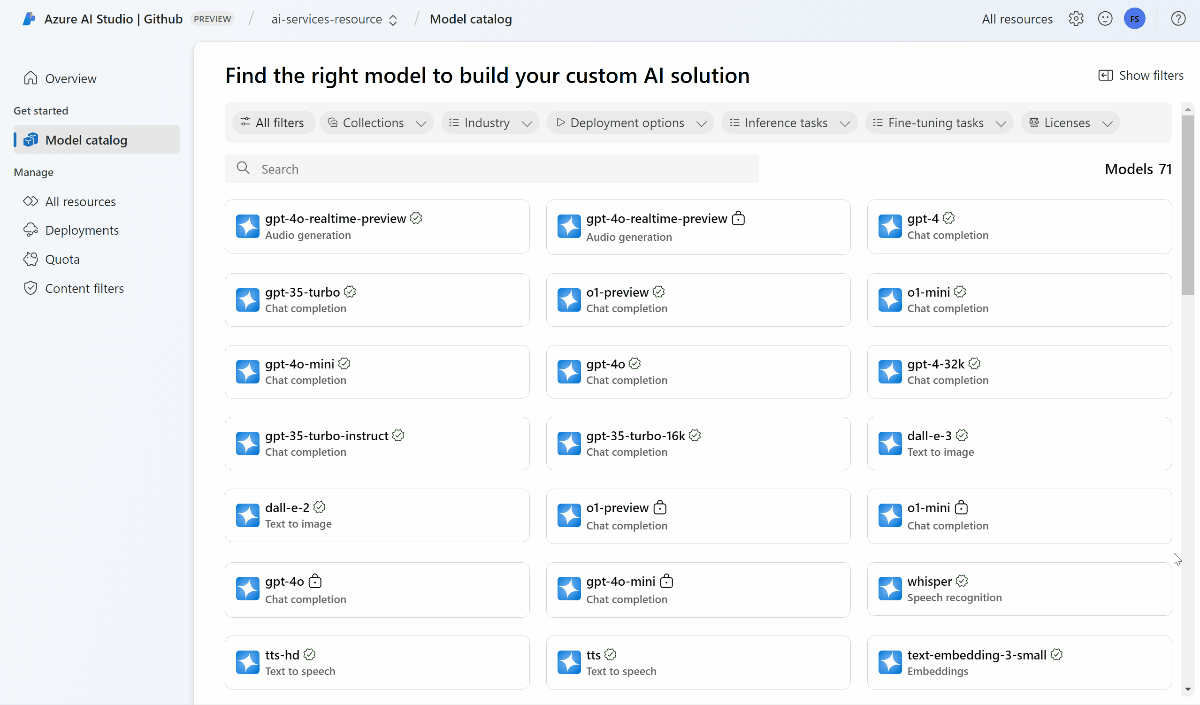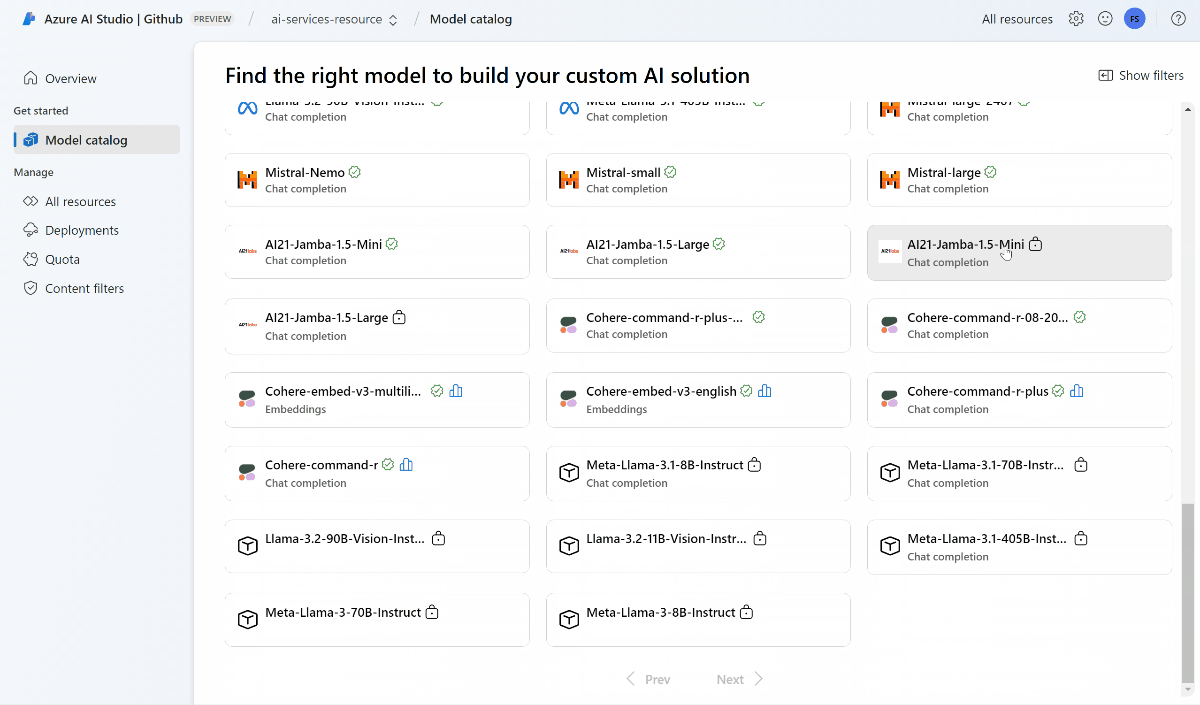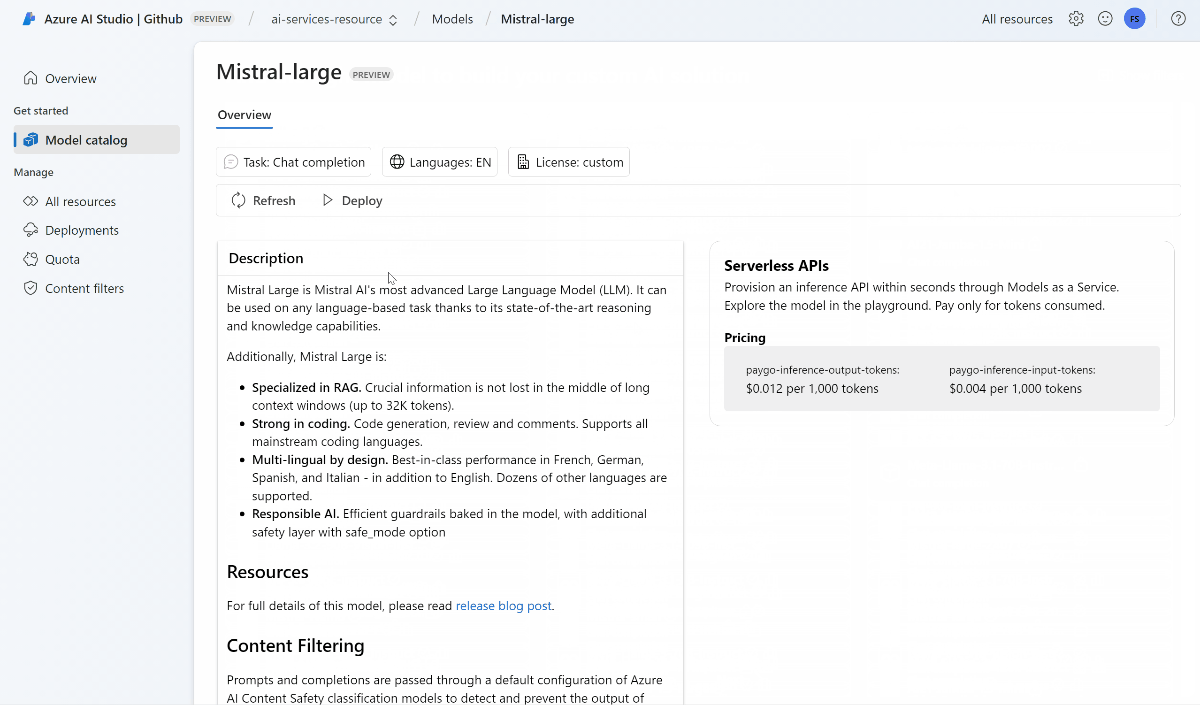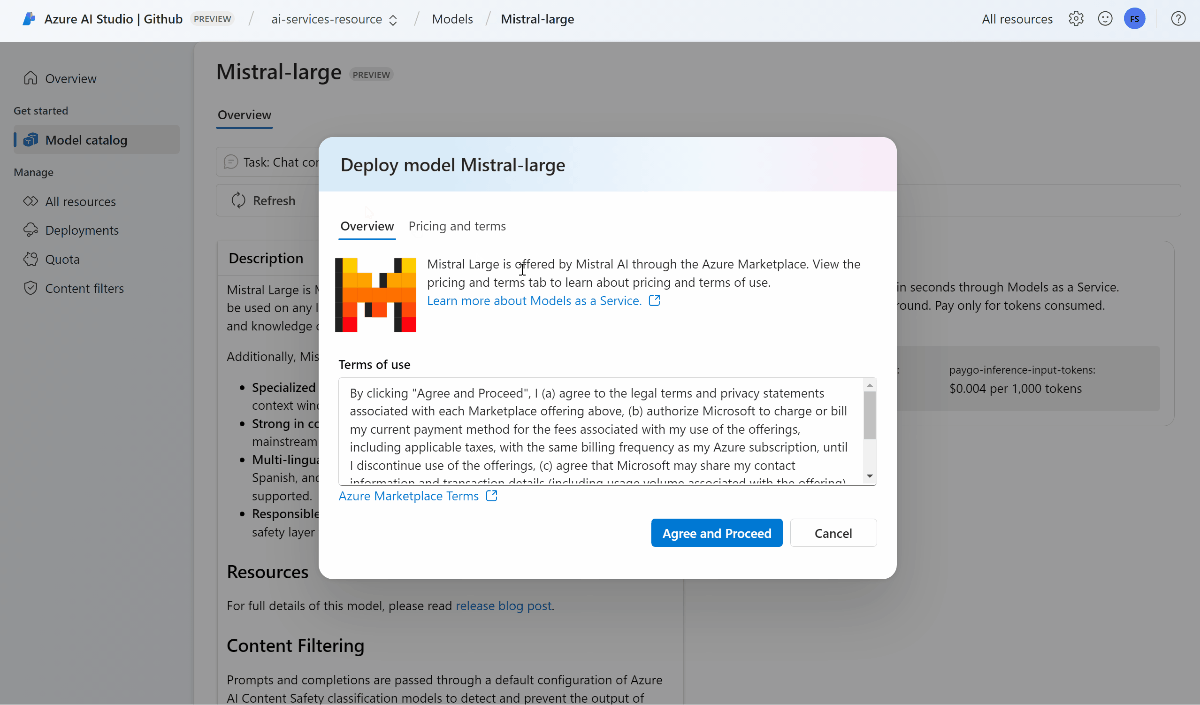
You can review the details of the model in the model card.
Select Use this model.
For model providers that require more contract terms, you're asked to accept those terms by selecting Agree and proceed.
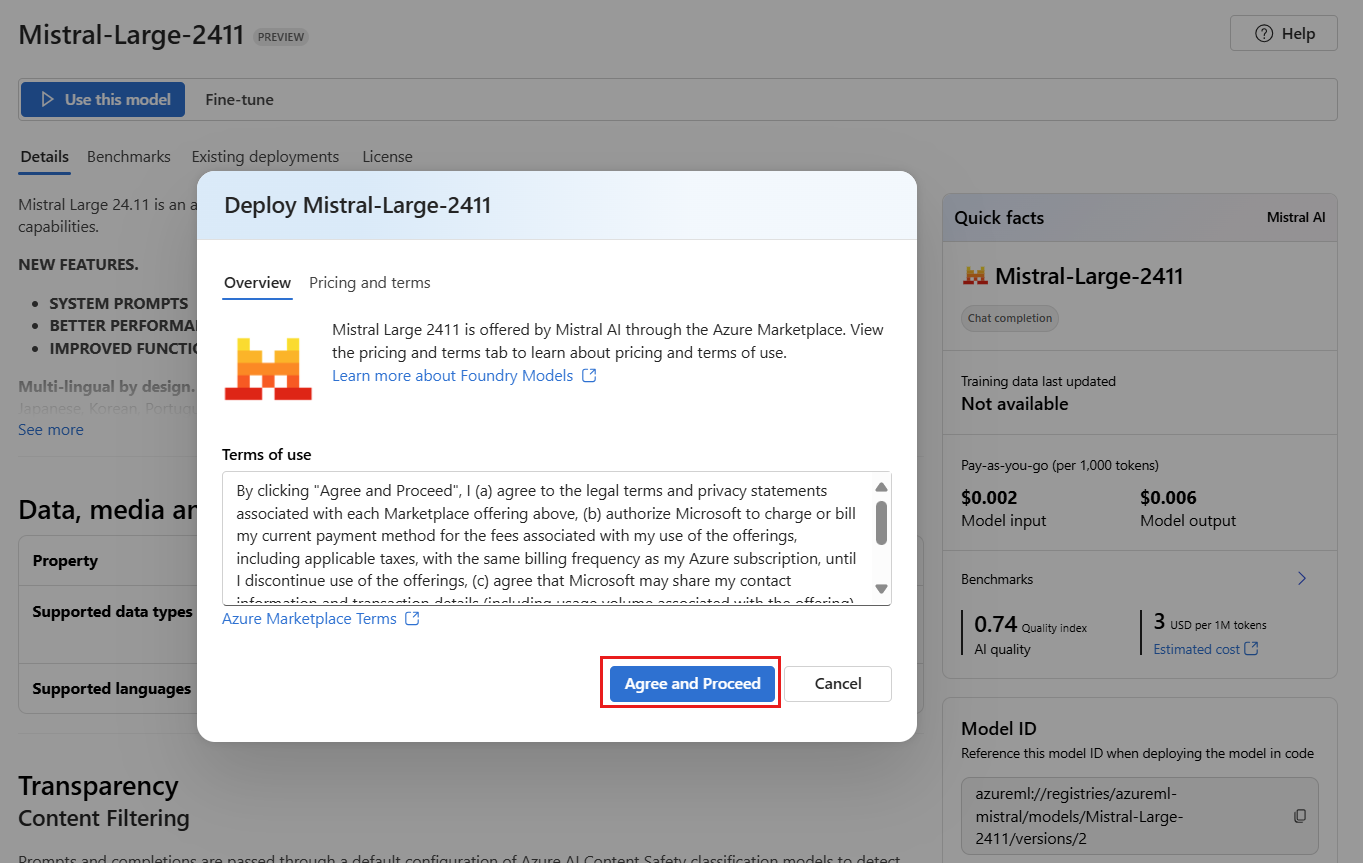
You can configure the deployment settings at this time. By default, the deployment receives the name of the model you're deploying. The deployment name is used in the
modelparameter for request to route to this particular model deployment. It allows you to configure specific names for your models when you attach specific configurations. For instance,o1-preview-safefor a model with a strict content filter.We automatically select an Azure AI Foundry connection depending on your project because you turned on the feature Deploy models to Azure AI model inference service. Select Customize to change the connection based on your needs. If you're deploying under the serverless API deployment type, the models need to be available in the region of the Foundry resource.
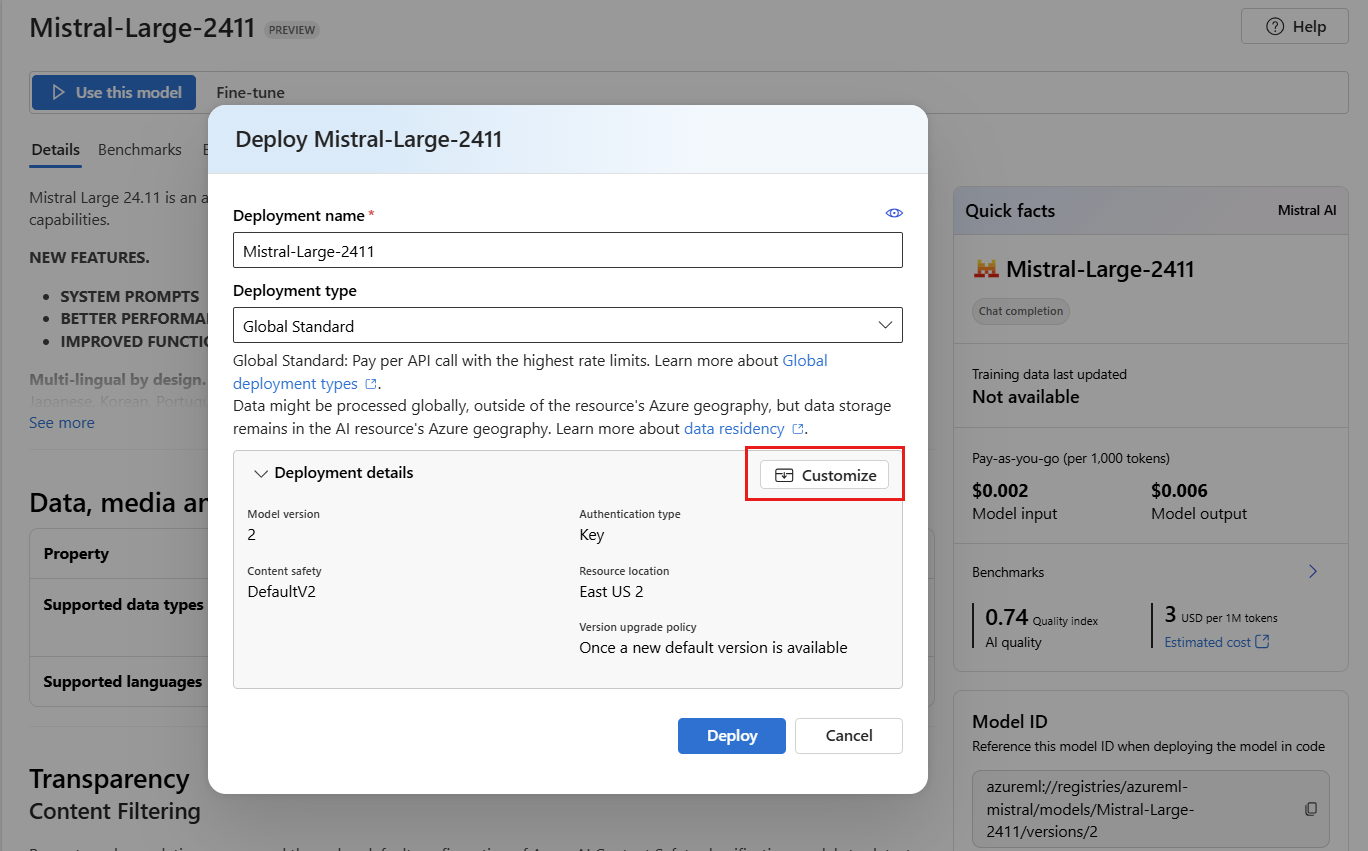
Select Deploy.
Once the deployment finishes, you see the endpoint URL and credentials to get access to the model. Notice that now the provided URL and credentials are the same as displayed in the landing page of the project for the Foundry Models endpoint.
You can view all the models available under the resource by going to Models + endpoints section and locating the group for the connection to your resource:





Upgrade your code with the new endpoint
Once your Azure AI Foundry resource is configured, you can start consuming it from your code. You need the endpoint URL and key for it, which can be found in the Overview section:
You can use any of the supported SDKs to get predictions out from the endpoint. The following SDKs are officially supported:
- OpenAI SDK
- Azure OpenAI SDK
- Azure AI Inference package
- Azure AI Projects package
For more information and examples, see Supported programming languages for Azure AI Inference SDK. The following example shows how to use the Azure AI Inference package with the newly deployed model:
Install the package azure-ai-inference using your package manager, like pip:
pip install azure-ai-inference
Then, you can use the package to consume the model. The following example shows how to create a client to consume chat completions:
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
)
Explore our samples and read the API reference documentation to get yourself started.
Generate your first chat completion:
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="Explain Riemann's conjecture in 1 paragraph"),
],
model="mistral-large"
)
print(response.choices[0].message.content)
Use the parameter model="<deployment-name> to route your request to this deployment. Deployments work as an alias of a given model under certain configurations. To learn how Azure AI Foundry Models routes deployments, see Routing.
Move from serverless API deployments to Foundry Models
Although you configured the project to use Foundry Models, existing model deployments continue to exist within the project as serverless API deployments. Those deployments aren't moved for you. Hence, you can progressively upgrade any existing code that references previous model deployments. To start moving the model deployments, we recommend the following workflow:
Recreate the model deployment in Foundry Models. This model deployment is accessible under the Foundry Models endpoint.
Upgrade your code to use the new endpoint.
Clean up the project by removing the serverless API deployment.
Upgrade your code with the new endpoint
Once the models are deployed under Azure AI Foundry, you can upgrade your code to use the Foundry Models endpoint. The main difference between how serverless API deployments and Foundry Models work resides in the endpoint URL and model parameter. While serverless API deployments have a set of URI and key per each model deployment, Foundry Models has only one for all of them.
The following table summarizes the changes you have to introduce:
| Property | serverless API deployments | Foundry Models |
|---|---|---|
| Endpoint | https://<endpoint-name>.<region>.inference.ai.azure.com |
https://<ai-resource>.services.ai.azure.com/models |
| Credentials | One per model/endpoint. | One per Foundry resource. You can use Microsoft Entra ID too. |
| Model parameter | None. | Required. Use the name of the model deployment. |
Clean-up existing serverless API deployments from your project
After you refactored your code, you might want to delete the existing serverless API deployments inside of the project (if any).
For each model deployed as serverless API deployments, follow these steps:
Go to the Azure AI Foundry portal.
Select Models + endpoints, then choose the Service endpoints tab.
Identify the endpoints of type serverless API deployment and select the one you want to delete.
Select the option Delete.
Warning
This operation can't be reverted. Ensure that the endpoint isn't currently used by any other user or piece of code.
Confirm the operation by selecting Delete.
If you created a serverless API deployment connection to this endpoint from other projects, such connections aren't removed and continue to point to the inexistent endpoint. Delete any of those connections for avoiding errors.
Limitations
Consider the following limitations when configuring your project to use Foundry Models:
- Only models that support serverless API deployments are available for deployment to Foundry Models. Models requiring compute quota from your subscription (managed compute), including custom models, can only be deployed within a given project as Managed Online Endpoints and continue to be accessible using their own set of endpoint URI and credentials.
- Models available as both serverless API deployments and managed compute offerings are, by default, deployed to Foundry Models in Azure AI Foundry resources. Azure AI Foundry portal doesn't offer a way to deploy them to Managed Online Endpoints. You have to turn off the feature mentioned at Configure the project to use Foundry Models or use the Azure CLI/Azure ML SDK/ARM templates to perform the deployment.